前言
最近一部根据真实事件改编的《中国医生》正在火热上映,感动了无数观众,更获钟南山院士高度评价:“真正体现了中国医生的良心、责任、决心、行动!”
影片以金银潭医院为核心故事背景,将抗疫中各地发生的真人真事浓缩凝练,全景式还原记录了波澜壮阔、艰苦卓绝的抗疫斗争。
网友也对《中国医生》原型展开热烈讨论,关于《中国医生》的话题在多个平台登上热搜,今天我们就通过抓取近4万条评论数据,看看电影观众们对这部电影的评价究竟如何?

一、核心功能设计
总体来说,我们需要先从猫眼电影爬取《中国医生》的影评数据,并将这些数据进行可视化分析展示。
拆解需求,大致可以整理出我们需要分为以下几步完成:
- 通过爬虫获取猫眼APP的评论数据,包括用户名,用户城市,评论内容,星级打分,评论时间等。
- 对获取的评论数据进行预处理,获取用户对于电影的星级评分,并通过饼图进行可视化显示。
- 根据评论数据中的城市进行观影用户区域分布可视化。
- 对影评内容进行词云绘制。
二、实现步骤
1. 爬取数据
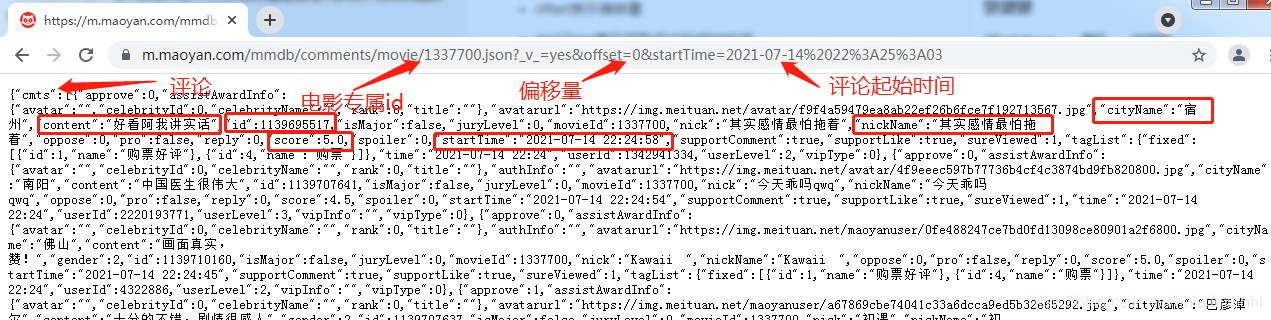
首先我们需要获取猫眼APP上的评论数据,通过分析发现,猫眼APP的评论数据接口为:https://m.maoyan.com/mmdb/comments/movie/1337700.json_v_=yes&offset=0&startTime=2021-07-14%2022%3A25%3A03。
根据对数据分析,返回的json格式数据,可以发现:
- 1337700就是代表《中国医生》电影的id
- offset表示偏移量
- startTime表示获取评论的起始时间
- cmts表示评论,每次获取15条,offset偏移量是指每次获取评论时的起始索引,向后取15条
- cmts中有我们需要的用户id、用户名、城市名、评论内容、评论星级分数、评论时间等信息
网页结构我们上面已经分析好了,那么我们就可以来动手爬取我们所需要的数据了。获取到所有的数据资源之后,可以把这些数据保存下来。
获取数据:
def get_data(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.123 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
html_data = response.text
return html_data
处理数据:
def parse_data(html):
data = json.loads(html)['cmts']
comments = []
for item in data:
comment = {
'id': item['id'],
'nickName': item['nickName'],
'cityName': item['cityName'] if 'cityName' in item else '',
'content': item['content'].replace('\n', ' ', 10),
'score': item['score'],
'startTime': item['startTime']
}
comments.append(comment)
return comments
存储数据:
def save_to_data():
start_time = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
end_time = '2021-07-09 00:00:00'
while start_time > end_time:
url = 'https://m.maoyan.com/mmdb/comments/movie/1337700.json?_v_=yes&offset=0&startTime=' + start_time.replace(' ', '%20')
html = None
try:
html = get_data(url)
except Exception as e:
time.sleep(0.5)
html = get_data(url)
else:
time.sleep(0.1)
comments = parse_data(html)
print(comments)
start_time = comments[14]['startTime']
start_time = datetime.strptime(start_time, '%Y-%m-%d %H:%M:%S') + timedelta(seconds=-1)
start_time = datetime.strftime(start_time, '%Y-%m-%d %H:%M:%S')
for item in comments:
with open('中国医生.txt', 'a', encoding='utf-8') as f:
f.write(str(item['id'])+','+item['nickName'] + ',' + item['cityName'] + ',' + item['content'] + ',' + str(item['score'])+ ',' + item['startTime'] + '\n')
这样我们就可以把需要用到的观影用户数据存储下来了,效果如下:

数据获取存储之后,接下来我们就需要对数据进行可视化显示。 这里使用的是pyecharts,是一个用于生成Echarts图表的类库,便于在Python中根据数据生成可视化的图表。
之前博主有写过一篇关于pyecharts的文章,里面很详细的介绍了各类图表的使用方法和案例,不会的可以先去学习下pyecharts相关的内容。【一文学会炫酷图表利器pyecharts】
2. 星级评分
我们根据上面获取的观影数据,其中有一个score属性代表电影分数,我们需要读取用户的评分进行一星至五星格式转换。
rates = []
with open('中国医生.txt', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
try:
rates.append(row.split(',')[4])
except:
pass
attr = ['五星', '四星', '三星', '二星', '一星']
value = [
rates.count('5.0') + rates.count('4.5'),
rates.count('4.0') + rates.count('3.5'),
rates.count('3.0') + rates.count('2.5'),
rates.count('2.0') + rates.count('1.5'),
rates.count('1.0') + rates.count('0.5')
]
拿到对应的星级数据之后,我们可以绘制饼状图查看电影评分比例数据。
pie = (
Pie()
.add("", [list(z) for z in zip(attr, value)])
.set_global_opts(title_opts=opts.TitleOpts(title="《中国医生》评分比例饼图"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
)
pie.render('评分.html')
效果如下:
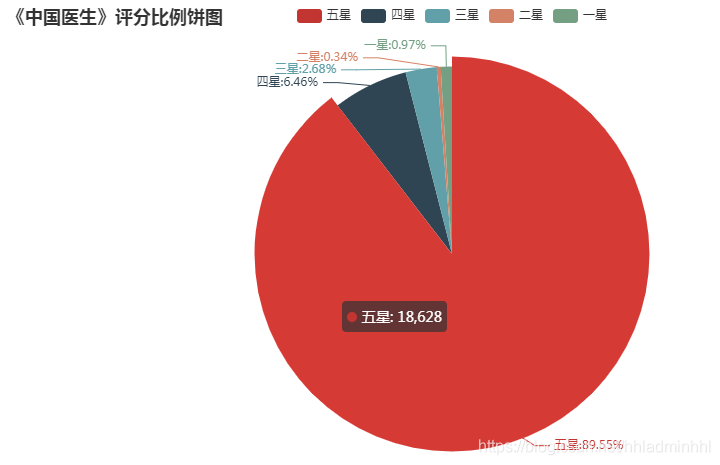
从图中可以看出,五星比例接近89.5%,四星比例为6.5%,两者合计高达96%,可见《中国医生》电影的口碑还是相当不错的。
3. 观影用户分布
我们还可以根据存储的数据中cityName获取观影用户的地点分布情况。
获取评论中所有城市:
cities = []
with open('./中国医生.txt', mode='r', encoding='utf-8') as f:
rows = f.readlines()
for row in rows:
try:
city = row.split(',')[2]
except IndexError:
pass
if city != '':
cities.append(city)
统计每个城市出现的次数:
data = []
value = []
attr = []
for city in set(cities):
data.append((city, cities.count(city)))
data = Counter(cities).most_common(93)
value = [city[1] for city in data]
max2 = value[0]
min2 = value[-1]
if (max2-min2)%5!=0:
max2 = max2 + (5-(max2-min2)%5)
data_top25 = Counter(cities).most_common(25)
attr = [city[0] for city in data_top25]
value = [city[1] for city in data_top25]
max1 = value[0]
min1 = value[-1]
绘制观影用户Top25分布:
def bar_base():
c = (
Bar()
.add_xaxis(attr)
.add_yaxis("", value,category_gap="15%")
.set_series_opts(label_opts=opts.LabelOpts(is_show=True