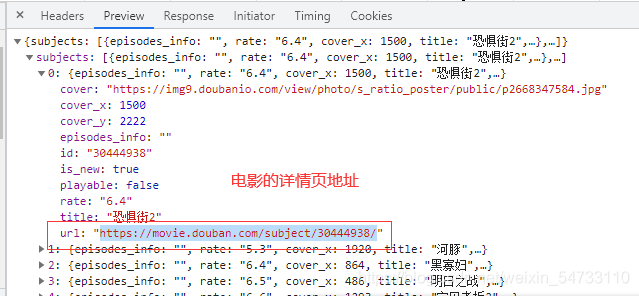
def save_excel(self, data, title, f):
os_path_1 = os.getcwd() + '/数据/'
if not os.path.exists(os_path_1):
os.mkdir(os_path_1)
os_path = os_path_1 + '数据.xls'
if not os.path.exists(os_path):
workbook = xlwt.Workbook(encoding='utf-8')
worksheet1 = workbook.add_sheet("基本详情", cell_overwrite_ok=True)
borders = xlwt.Borders()
"""定义边框实线"""
borders.left = xlwt.Borders.THIN
borders.right = xlwt.Borders.THIN
borders.top = xlwt.Borders.THIN
borders.bottom = xlwt.Borders.THIN
borders.left_colour = 0x40
borders.right_colour = 0x40
borders.top_colour = 0x40
borders.bottom_colour = 0x40
style = xlwt.XFStyle()
style.borders = borders
"""居中写入设置"""
al = xlwt.Alignment()
al.horz = 0x02
al.vert = 0x01
style.alignment = al
'''基本详情13'''
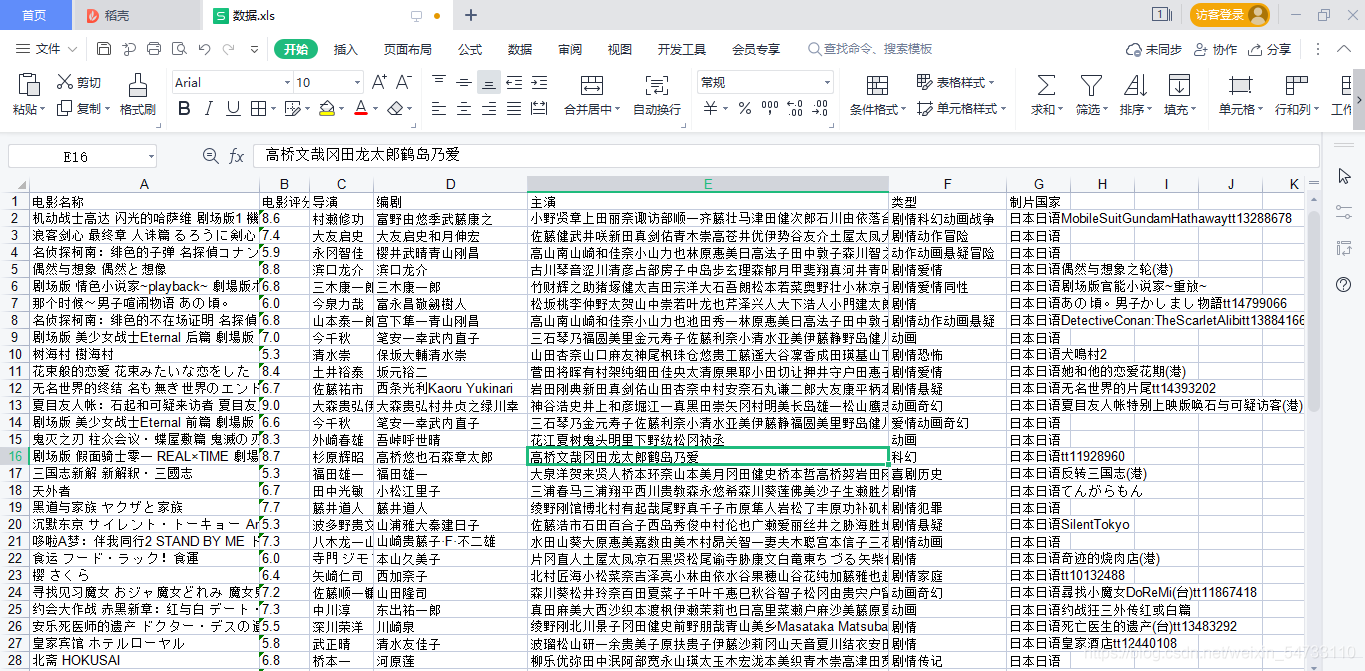
excel_data_1 = ('电影名称', '电影评分', '导演', '编剧', '主演', '类型', '制片国家')
for i in range(0, len(excel_data_1)):
worksheet1.col(i).width = 2560 * 3
worksheet1.write(0, i, excel_data_1[i], style)
workbook.save(os_path)
if os.path.exists(os_path):
workbook = xlrd.open_workbook(os_path)
sheets = workbook.sheet_names()
for i in range(len(sheets)):
for name in data.keys():
worksheet = workbook.sheet_by_name(sheets[i])
if worksheet.name == name:
rows_old = worksheet.nrows
new_workbook = copy(workbook)
new_worksheet = new_workbook.get_sheet(i)
for num in range(0, len(data[name])):
new_worksheet.write(rows_old, num, data[name][num])
new_workbook.save(os_path)
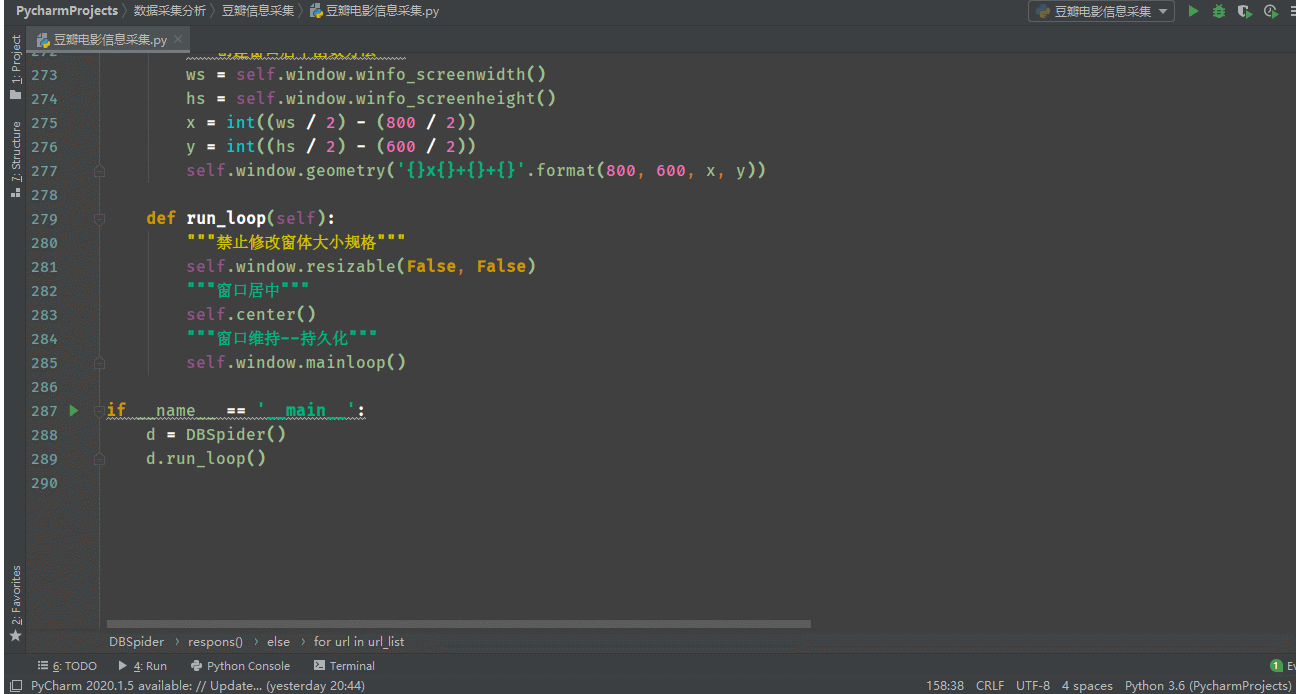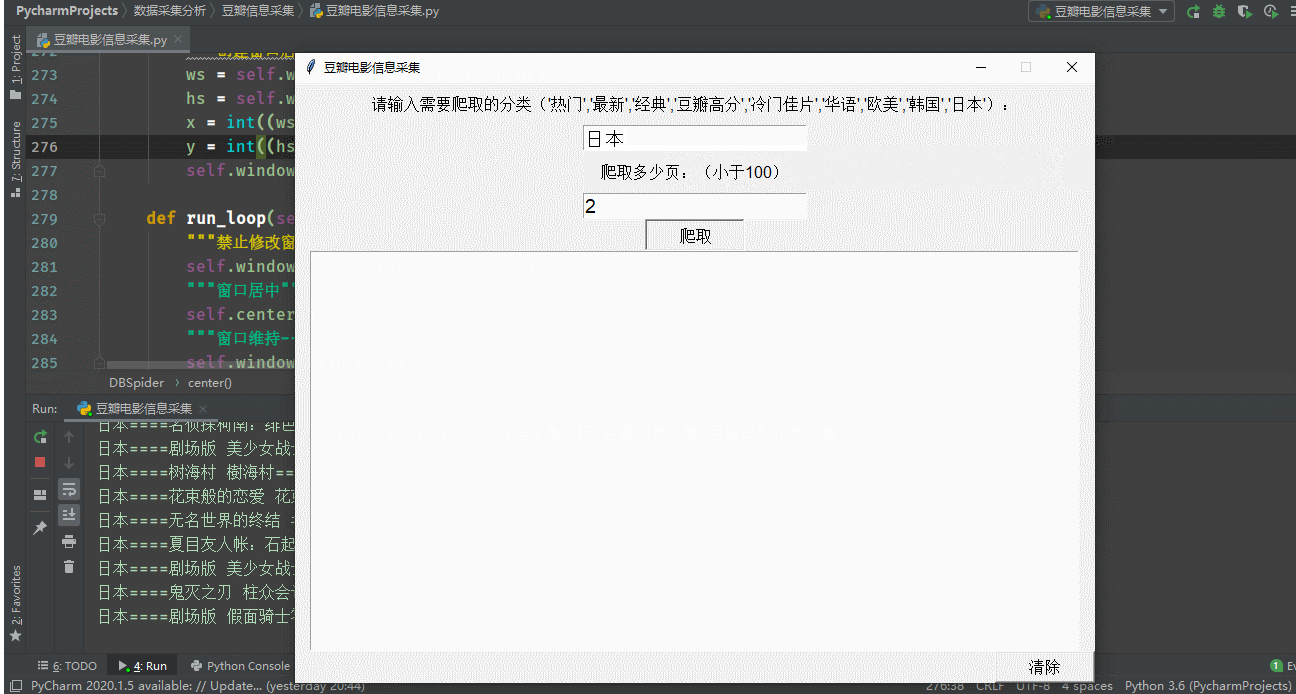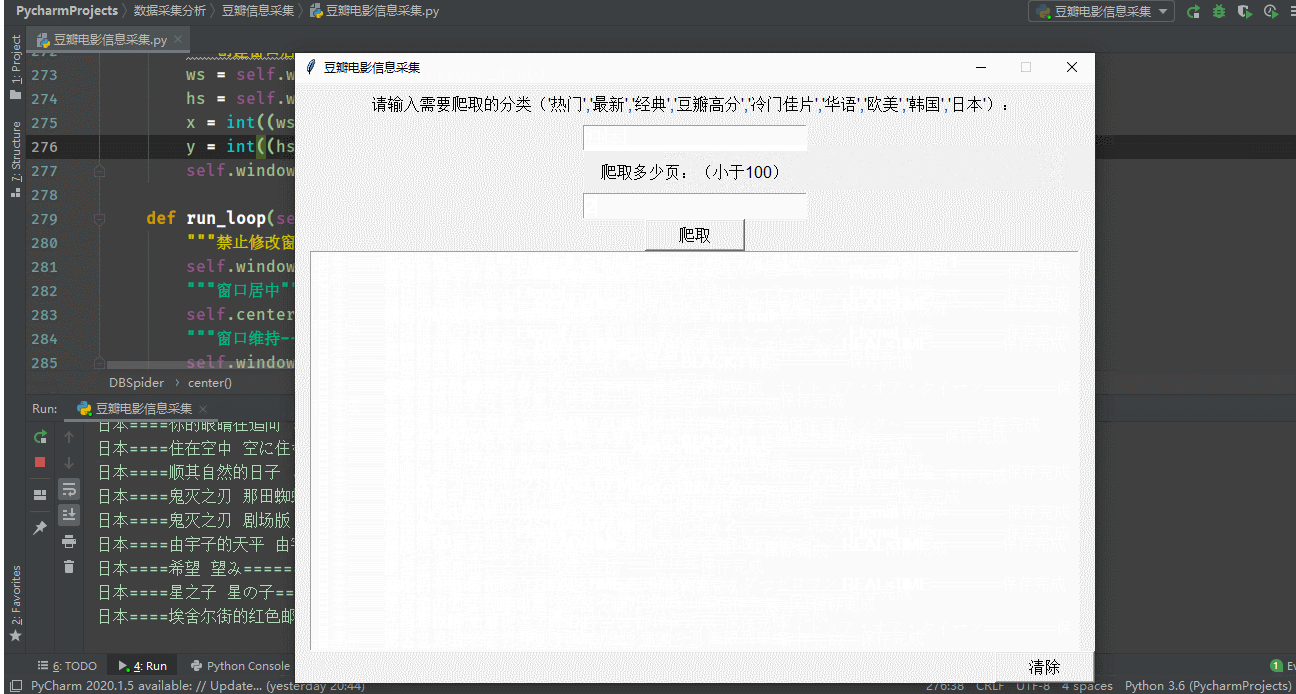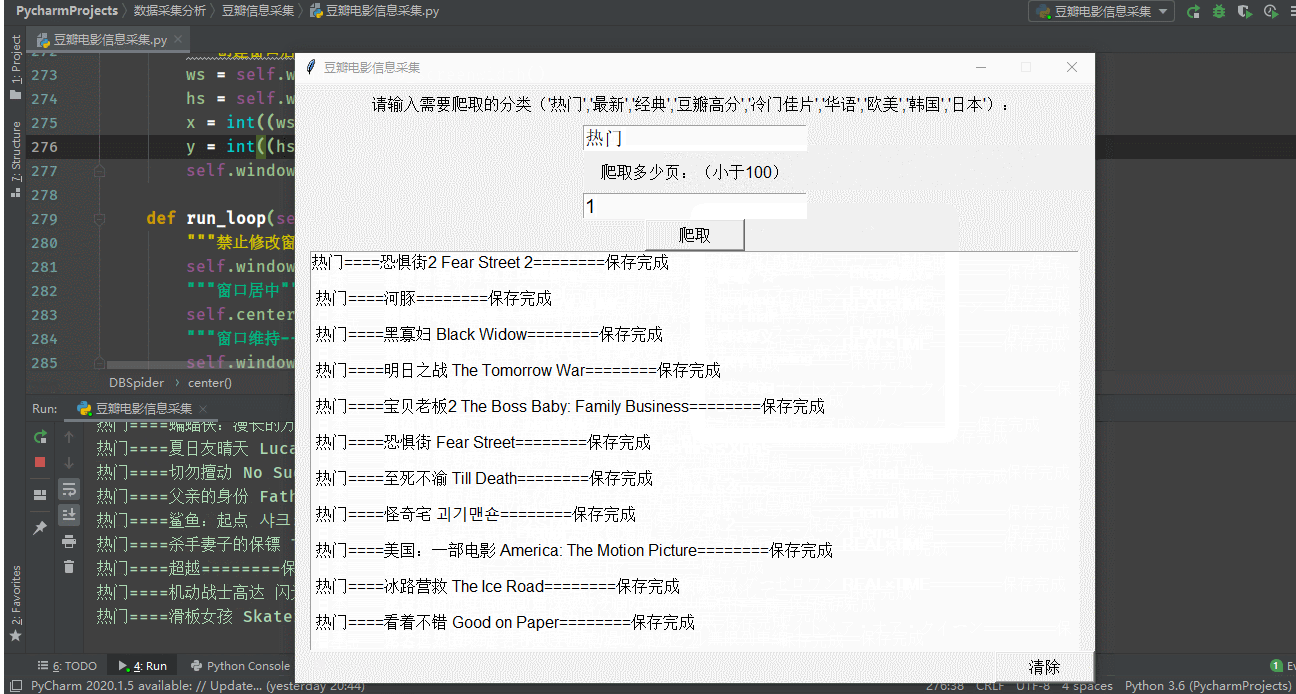
print(f'{f}===={title}========保存完成')
源码展示:
USER_AGENT_LIST = ['Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; Hot Lingo 2.0)',
'Mozilla/5.0 (Windows NT 6.2; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3451.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:57.0) Gecko/20100101 Firefox/57.0',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.71 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.2999.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.70 Safari/537.36',
'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.4; en-US; rv:1.9.2.2) Gecko/20100316 Firefox/3.6.2',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.155 Safari/537.36 OPR/31.0.1889.174',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.1.4322; MS-RTC LM 8; InfoPath.2; Tablet PC 2.0)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/48.0.2564.116 Safari/537.36 TheWorld 7',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 OPR/55.0.2994.61',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; MATP; InfoPath.2; .NET4.0C; CIBA; Maxthon 2.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.814.0 Safari/535.1',
'Mozilla/5.0 (Macintosh; U; PPC Mac OS X; ja-jp) AppleWebKit/418.9.1 (KHTML, like Gecko) Safari/419.3',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.134 Safari/537.36',
'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0; Touch; MASMJS)',