R语言与数据分析练习:K-Means聚类
k-means实现
k-means算法,是一种最广泛使用的聚类算法。k-means以k作为参数,把数据分为k个组,通过迭代计算过程,将各个分组内的所有数据样本的均值作为该类的中心点,使得组内数据具有较高的相似度,而组间的相似度最低。
k-means工作原理
- 初始化数据,选择k个对象作为中心点。
- 遍历整个数据集,计算每个点与每个中心点的距离,将它分配给距离中心最近的组。
- 重新计算每个组的平均值,作为新的聚类中心。
- 上面2-3步,过程不断重复,直到函数收敛,不再新的分组情况出现。
k-means聚类,适用于连续型数据集。在计算数据样本之间的距离时,通常使用欧式距离作为相似性度量。k-means支持多种距离计算,还包括maximum, manhattan, pearson, correlation, spearman, kendall等。各种的距离算法的介绍,请参考文章R语言实现46种距离算法
kmeans()函数实现
在R语言中,我们可以直接调用系统中自带的kmeans()函数,就可以实现k-means的聚类。同时,有很多第三方算法包也提供了k-means的计算函数。当我们需要使用kmeans算法,可以使用第三方扩展的包,比如flexclust, amap等包。
题目:
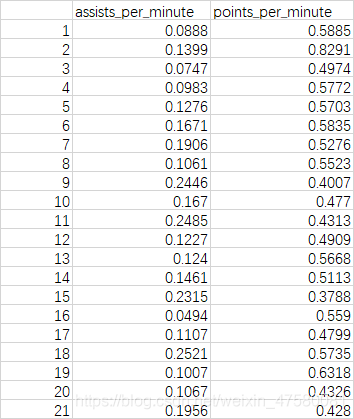
在篮球运动中,一般情况下,控球后卫与得分后卫的助攻数较多,小前锋的得分数较多,而大前锋与中锋的助攻数与得分数较少。下表为21名篮球运动员每分钟助攻数和每分钟得分数的数据集,请运用K-Means聚类算法将这21名篮球运动员划分为5类,并通过画图判断他们分别属于什么位置。
数据如下:
assists_per_minute为每分钟助攻次数
points_per_minute为每分钟得分数
实现代码:
setwd('D:/bigdata/R语言与数据分析/data03')
basketballdata <- read.csv("data.csv",stringsAsFactors = F)
outfile <- matrix(data=NA,
nrow = nrow(basketballdata),
ncol = 2,
byrow = TRUE,
dimnames = list(c(1:nrow(basketballdata)),
c("assists_per_minute","points_per_minute")))
outfile[,1] <- basketballdata[,2]
outfile[,2] <- basketballdata[,3]
summary(outfile)
write.csv(outfile,'datachange.csv',row.names = FALSE)
basketballdata <- read.csv('datachange.csv', header = TRUE)
zscoredfile <- scale(basketballdata)
write.csv(zscoredfile, 'standardizeddata.csv',row.names = FALSE)
inputfile <- read.csv('standardizeddata.csv', header = TRUE)
result <- kmeans(inputfile, 5)
type <- result$cluster
type
table(type)
centervec <- result$center
centervec
max <- apply(centervec,2,max)
max
min <- apply(centervec,2,min)
min
df = data.frame(rbind(max,min,centervec))
df
library(cluster)
library(factoextra)
fviz_cluster(result,basketballdata)
运行结果:
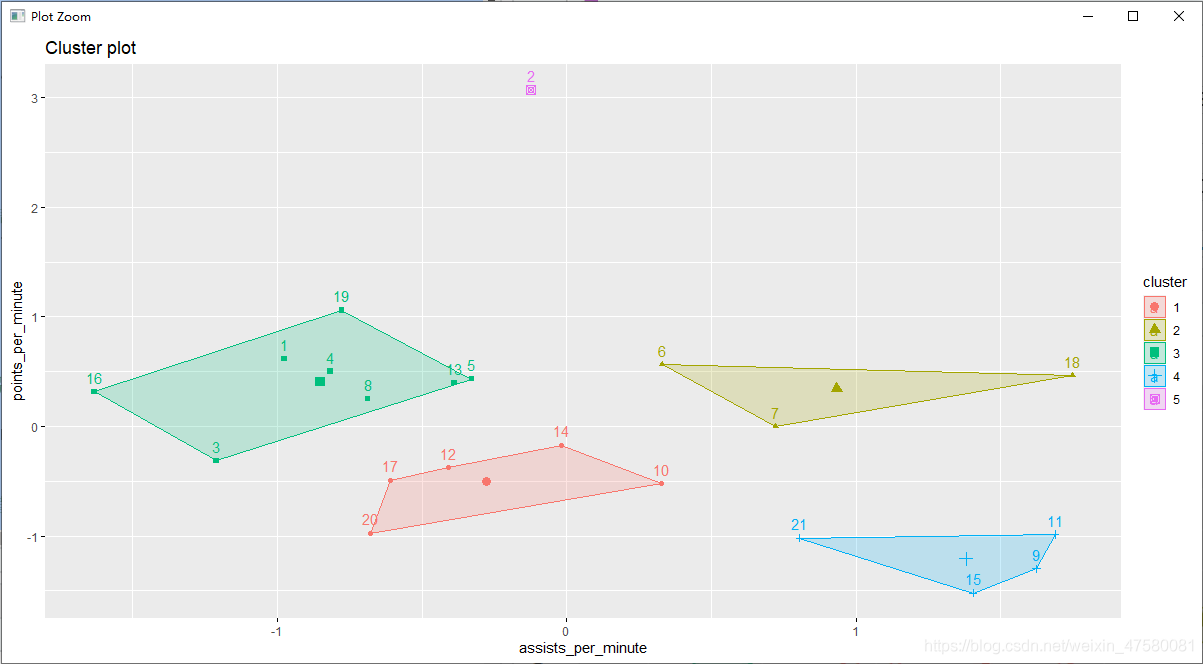
对球员的数据进行分析:
第一组(蓝色部分)与第二组(棕色部分)的每分钟助攻次数较多,所以对应控球后卫与得分后卫。又因为得分后卫的每分钟得分数多于控球后卫,所以第一组(蓝色部分)为控球后卫,第二组(棕色部分)为得分后卫。
第三组(紫色部分)的每分钟得分数较多,所以对应小前锋
第四组(绿色部分)和第五组(红色部分)的每分钟助攻次数及每分钟得分数较少,所以对应大前锋与中锋。又因为中锋每分钟得分数多于大前锋,所以,第四组(绿色部分)为大前锋,第五组(红色部分)为中锋。
推测出每个球员的位置:
第一组(蓝色部分)为控球后卫
(第一组:9,11,15,21)
第二组(棕色部分)为得分后卫
(第二组:6,7,18)
第三组(紫色部分)为小前锋
(第三组:2)
第四组(绿色部分)为大前锋
(第四组:10,12,14,17,20)
第五组(红色部分)为中锋
(第五组:1,3,4,5,8,13,16,19)
cs