一.DBnet
1.代码链接
分割条形码与文字代码:github链接:https://github.com/zonghaofan/dbnet_torch(提供模型)
2.论文阅读
model:

? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? model图
可微分二值化
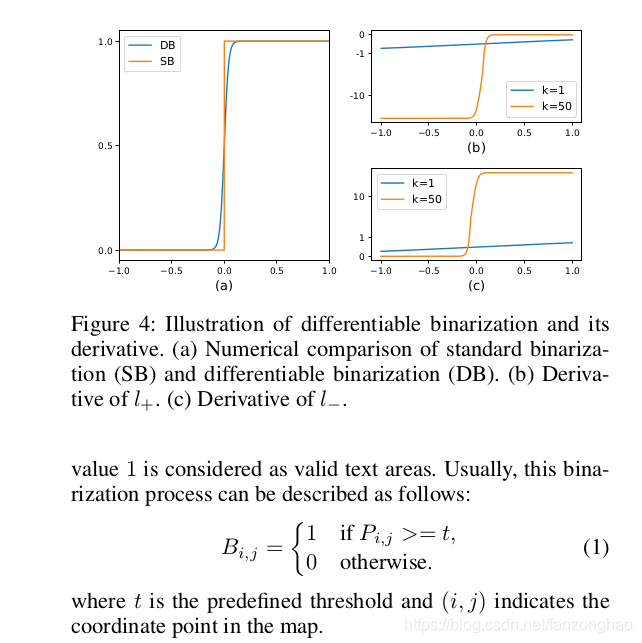
一般的分割模型都是对最终的输出结果取一个固定阈值进行二值化,本文创新点在于将二值化的阈值进行学习,如上图的(a)所示

加入可微分模块,就可以把阈值进行训练,能够更好区分前后景与粘连文本.
P:probability map
T:threshold map
B^:approximate binary map
Loss函数:
?

loss主要三部分:Ls是收缩之后文本实例的loss,?Lb是二值化之后的收缩文本实例loss, Lt是二值化阈值map的loss,?Ls和Lb都使用带OHEM的bceloss, Lt使用L1loss。
注意的是论文给的速度只是包含前向传播和后处理,所以实际上包含预处理,速度没这么快的.


一些结果展示


二.知识蒸馏

其中T是温度,直接使用softmax层的输出值作为soft target,?当softmax输出的概率分布熵相对较小时,负标签的值都很接近0,对损失函数的贡献非常小,小到可以忽略不计。因此"温度"这个变量就派上了用场。T很大时就能软化softmax的输出概率, 分布越趋于平滑,其分布的熵越大,负标签携带的信息会被相对地放大,模型训练将更加关注负标签。也就是从有部分信息量的负标签中学习 --> 温度要高一些,防止受负标签中噪声的影响 -->温度要低一些。
思路:采用resnet50(teacher)先训练,在利用训练好的resnet50(teacher)对resnet18(student)小模型进行联合训练,实验证明f1score比单独训练resnet18涨一个点。
代码见github.
python train_word_industry_res50.py 训练teacher模型;
python train_word_industry_res18_kd.py 训练student模型.
三.torch模型->onnx->tensorrt
思路:采用torch.onnx将.pth转成.onnx格式,在用tensorrt推理。代码见github中的model_to_onnx.py.
四.解析条形码c++版与python版
1.c++版的zxing,见该链接
python调用形式为:
#coding:utf-8
"""用c++编译的zxing进行解析条形码"""
import subprocess
import os
import time
import sysos.path.join(os.path.dirname(__file__)))
def zxing_parse_code(imgpath):
zxing_bin_path = os.path.join(os.path.dirname(__file__), "zxing")
assert os.path.exists(zxing_bin_path), "zxing bin file not exist!"
command = '{} --test-mode {}'.format(zxing_bin_path, imgpath)
process = subprocess.Popen(command, shell=True, stdout=subprocess.PIPE)
process.wait()
output = process.communicate()[0].decode("utf-8").replace(' ', '').split('\n')
# print(output)
try:
if 'Detected:' in output[1]:
return output[1][9:]
else:
return None
except:
return None
2.安装环境:
ubuntu:
apt-get install zbar-tools
apt-get install python-jpype
centos:
yum install zbar-devel
pip install pyzbar
pip install zxing
3.代码案例?
#coding:utf-8
import pyzbar.pyzbar as pyzbar
import time
import shutil
import zxing
import cv2
def parse_code(codeimg, reader):
"""
输入矫正过的条形码图片输出解析结果
:param codeimg: 矫正过的条形码图片
:return: 条形码解析结果
"""
gray = cv2.cvtColor(codeimg, cv2.COLOR_BGR2GRAY)
gray_h, gray_w = gray.shape
barcodes1 = pyzbar.decode(gray)
# barcodes2 = pyzbar.decode(np.rot90(np.rot90(gray)))
# print('==barcodes2:', barcodes2)
def parse_results(barcode):
# for barcode in barcodes:
# 提取条形码的位置
# (x, y, w, h) = barcode.rect
# 字符串转换
barcodeData = barcode.data.decode("utf-8")
return barcodeData
if len(barcodes1):
barcodeData = parse_results(barcodes1[0])
if len(barcodeData) >= 10:#条形码位数大于10位
return barcodeData
else:
if gray_h>gray_w:
cv2.imwrite('./out_clip.jpg', np.rot90(codeimg)[...,::-1])
else:
cv2.imwrite('./out_clip.jpg', codeimg[...,::-1])
barcode = reader.decode('./out_clip.jpg')
# print('==barcode:', barcode)
try:
return barcode.raw
except:
return None
def debug_parse_code():
reader = zxing.BarCodeReader()
path = './5.png'
img = cv2.imread(path)
code_res = parse_code(img, reader)
print('==code_res:', code_res)
if __name__ == '__main__':
debug_parse_code()


cs