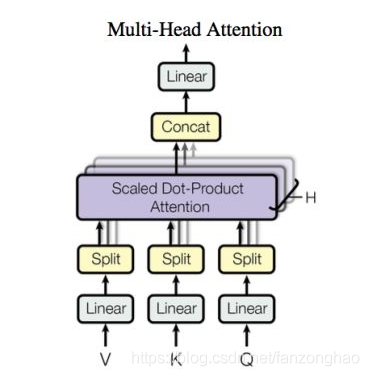
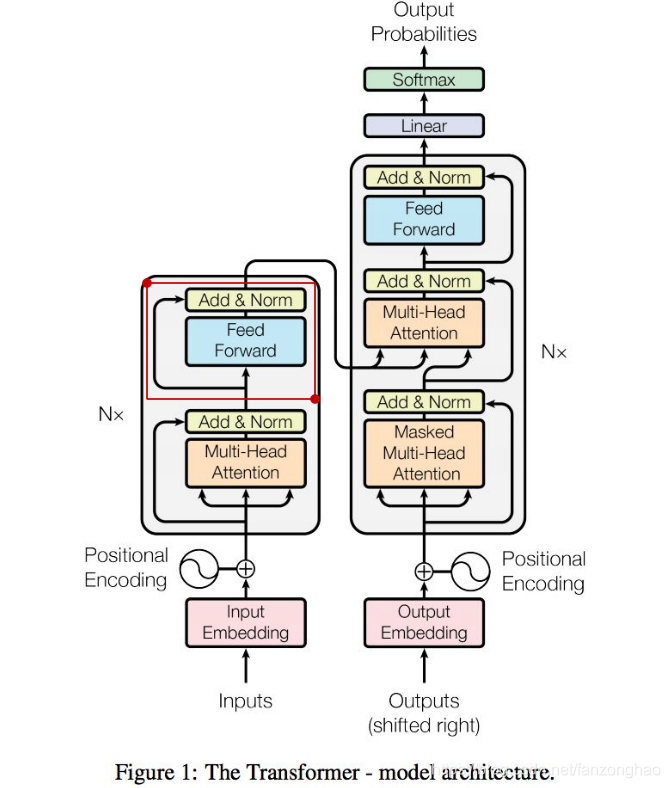
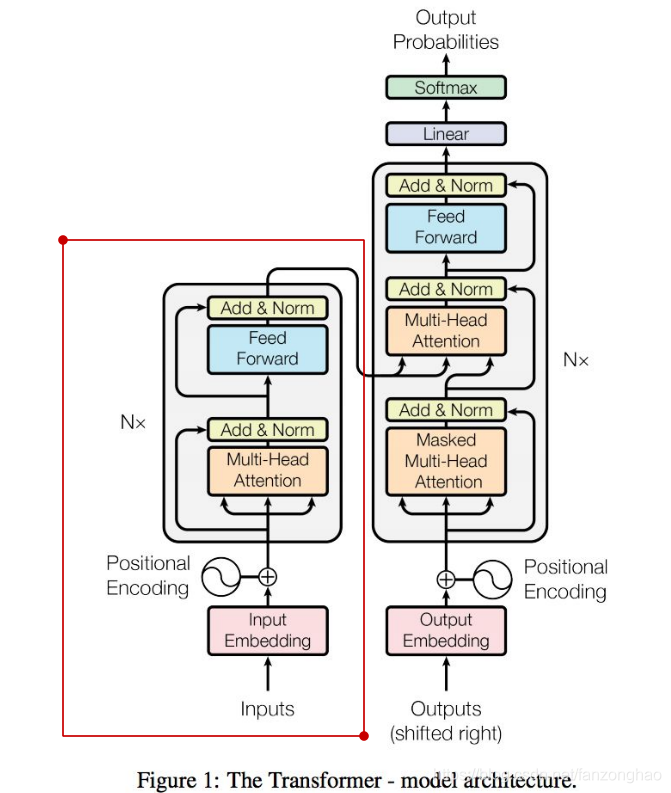
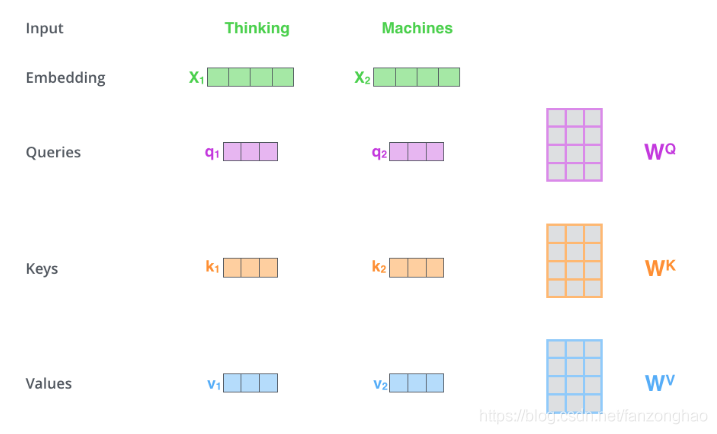
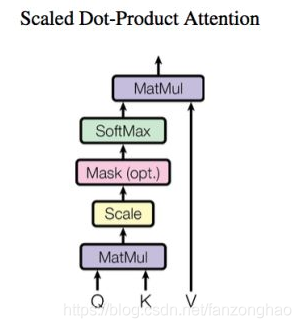
其共有6层4,5的结构,可看出q k v 均来自同一文本.
def sequence_mask(seq):
batch_size, seq_len = seq.size()
mask = torch.triu(torch.ones((seq_len, seq_len), dtype=torch.uint8),
diagonal=1)
mask = mask.unsqueeze(0).expand(batch_size, -1, -1) # [B, L, L]
return mask
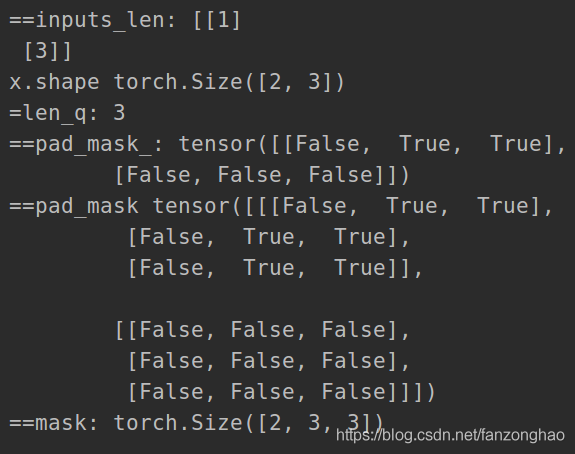
def padding_mask(seq_k, seq_q):
len_q = seq_q.size(1)
# `PAD` is 0
pad_mask = seq_k.eq(0)
pad_mask = pad_mask.unsqueeze(1).expand(-1, len_q, -1) # shape [B, L_q, L_k]
return pad_mask
class EncoderLayer(nn.Module):
"""一个encode的layer实现"""
def __init__(self, model_dim=512, num_heads=8, ffn_dim=2018, dropout=0.0):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
def forward(self, inputs, attn_mask=None):
# self attention
# [B, sequence, model_dim] [B* num_heads, sequence, sequence]
context, attention = self.attention(inputs, inputs, inputs, attn_mask)
# feed forward network
output = self.feed_forward(context) # [B, sequence, model_dim]
return output, attention
class Encoder(nn.Module):
"""编码器实现 总共6层"""
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Encoder, self).__init__()
self.encoder_layers = nn.ModuleList(
[EncoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
# [bs, max_seq_len] [bs, 1]
def forward(self, inputs, inputs_len):
output = self.seq_embedding(inputs) # [bs, max_seq_len, model_dim]
print('========output.shape', output.shape)
# 加入位置信息embedding
output += self.pos_embedding(inputs_len) # [bs, max_seq_len, model_dim]
print('========output.shape', output.shape)
self_attention_mask = padding_mask(inputs, inputs)
attentions = []
for encoder in self.encoder_layers:
output, attention = encoder(output, attn_mask=None)
# output, attention = encoder(output, self_attention_mask)
attentions.append(attention)
return output, attentions
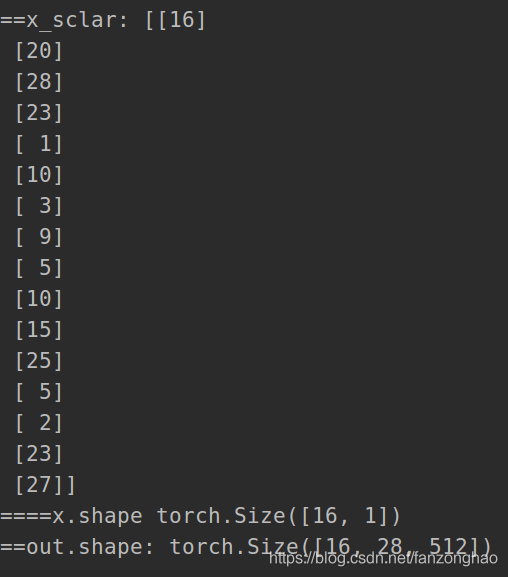
def debug_encoder():
Bs = 16
inputs_len = np.random.randint(1, 30, Bs).reshape(Bs, 1)
# print('==inputs_len:', inputs_len) # 模拟获取每个词的长度
vocab_size = 6000 # 词汇数
max_seq_len = int(max(inputs_len))
# vocab_size = int(max(inputs_len))
x = np.zeros((Bs, max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(inputs_len[s][0]):
x[s][j] = j+1
x = torch.LongTensor(torch.from_numpy(x))
inputs_len = torch.from_numpy(inputs_len)#[Bs, 1]
model = Encoder(vocab_size=vocab_size, max_seq_len=max_seq_len)
# x = torch.LongTensor([list(range(1, max_seq_len + 1)) for _ in range(Bs)])#模拟每个单词
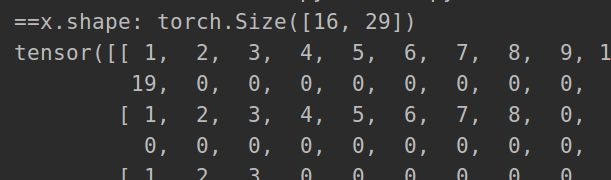
print('==x.shape:', x.shape)
print(x)
model(x, inputs_len=inputs_len)
if __name__ == '__main__':
debug_encoder()

7.Sequence Mask
样本:“我/爱/机器/学习”和 "i/ love /machine/ learning"
训练:
7.1. 把“我/爱/机器/学习”embedding后输入到encoder里去,最后一层的encoder最终输出的outputs [10, 512](假设我们采用的embedding长度为512,而且batch size = 1),此outputs 乘以新的参数矩阵,可以作为decoder里每一层用到的K和V;
7.2. 将<bos>作为decoder的初始输入,将decoder的最大概率输出词 A1和‘i’做cross entropy计算error。
7.3. 将<bos>,"i" 作为decoder的输入,将decoder的最大概率输出词 A2 和‘love’做cross entropy计算error。
7.4. 将<bos>,"i","love" 作为decoder的输入,将decoder的最大概率输出词A3和'machine' 做cross entropy计算error。
7.5. 将<bos>,"i","love ","machine" 作为decoder的输入,将decoder最大概率输出词A4和‘learning’做cross entropy计算error。
7.6. 将<bos>,"i","love ","machine","learning" 作为decoder的输入,将decoder最大概率输出词A5和终止符</s>做cross entropy计算error。
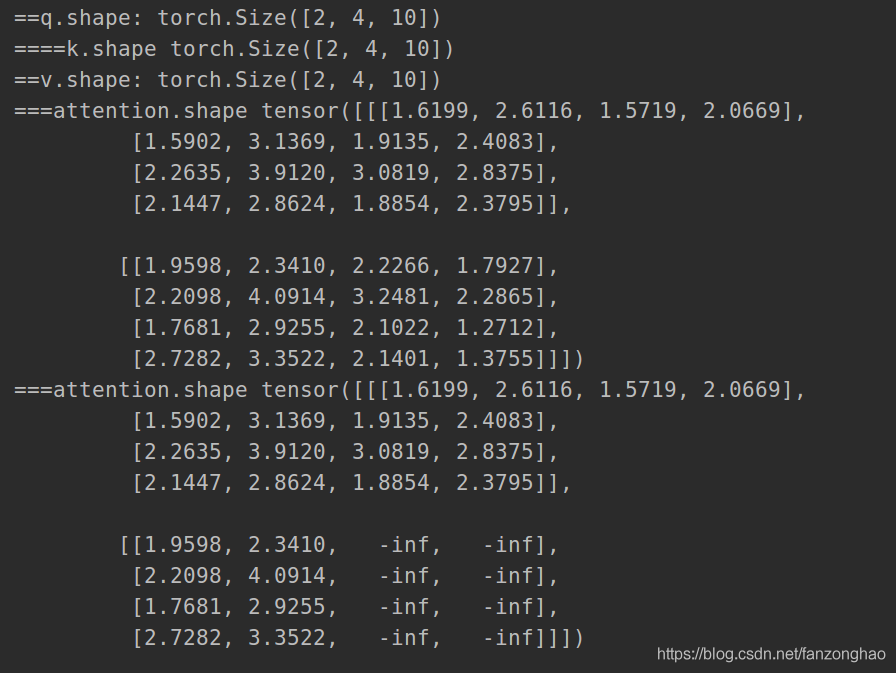
可看出上述训练过程是挨个单词串行进行的,故引入sequence mask,用于并行训练.
?
 作用
作用 生成
生成
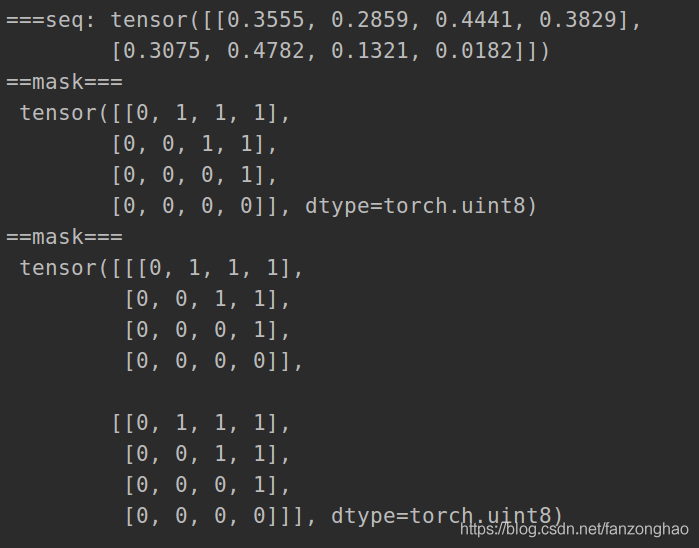
?
8.decoder实现
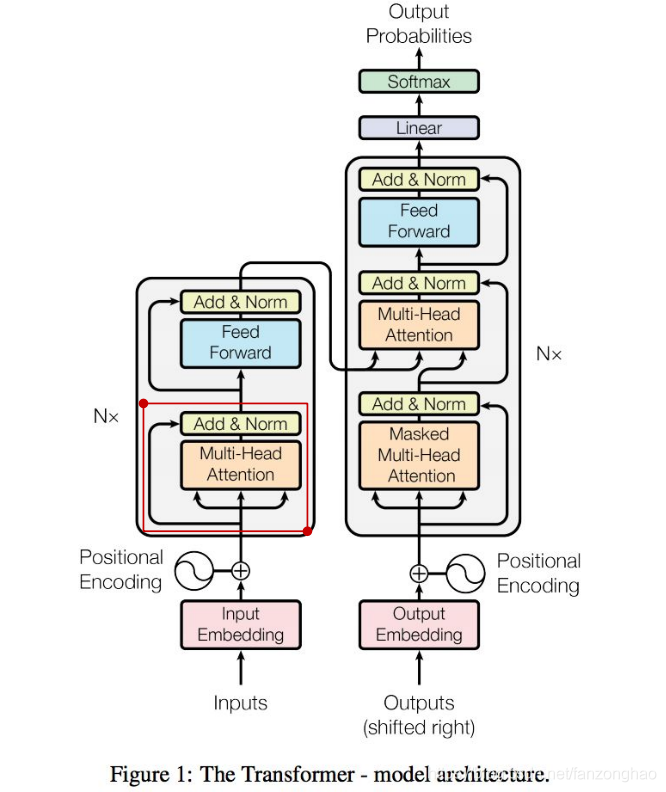
也是循环6层,可以看出decoder的soft-attention,q来自于decoder,k和v来自于encoder。它体现的是encoder对decoder的加权贡献。
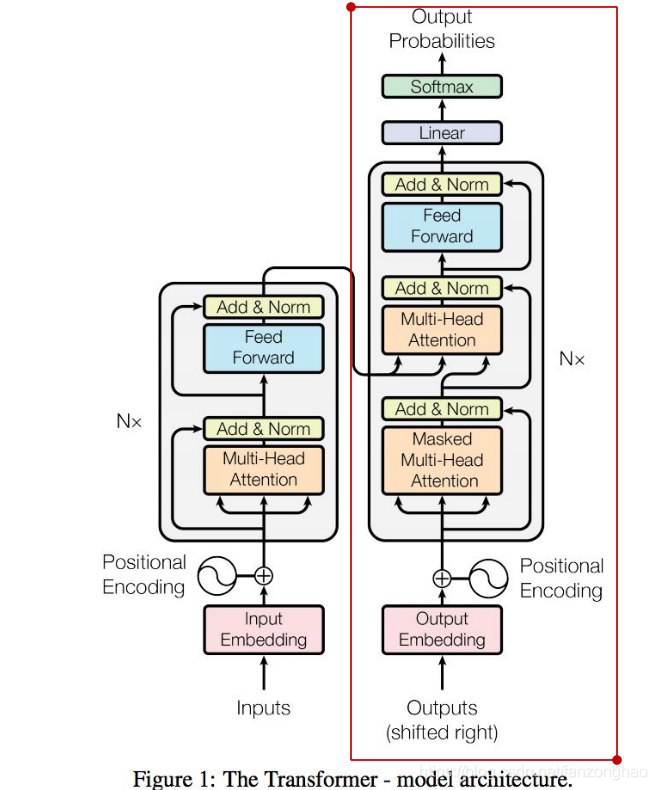
class DecoderLayer(nn.Module):
"""解码器的layer实现"""
def __init__(self, model_dim, num_heads=8, ffn_dim=2048, dropout=0.0):
super(DecoderLayer, self).__init__()
self.attention = MultiHeadAttention(model_dim, num_heads, dropout)
self.feed_forward = PositionalWiseFeedForward(model_dim, ffn_dim, dropout)
# [B, sequence, model_dim] [B, sequence, model_dim]
def forward(self,
dec_inputs,
enc_outputs,
self_attn_mask=None,
context_attn_mask=None):
# self attention, all inputs are decoder inputs
# [B, sequence, model_dim] [B* num_heads, sequence, sequence]
dec_output, self_attention = self.attention(
key=dec_inputs, value=dec_inputs, query=dec_inputs, attn_mask=self_attn_mask)
# context attention
# query is decoder's outputs, key and value are encoder's inputs
# [B, sequence, model_dim] [B* num_heads, sequence, sequence]
dec_output, context_attention = self.attention(
key=enc_outputs, value=enc_outputs, query=dec_output, attn_mask=context_attn_mask)
# decoder's output, or context
dec_output = self.feed_forward(dec_output) # [B, sequence, model_dim]
return dec_output, self_attention, context_attention
class Decoder(nn.Module):
"""解码器"""
def __init__(self,
vocab_size,
max_seq_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.0):
super(Decoder, self).__init__()
self.num_layers = num_layers
self.decoder_layers = nn.ModuleList(
[DecoderLayer(model_dim, num_heads, ffn_dim, dropout) for _ in
range(num_layers)])
self.seq_embedding = nn.Embedding(vocab_size + 1, model_dim, padding_idx=0)
self.pos_embedding = PositionalEncoding(model_dim, max_seq_len)
def forward(self, inputs, inputs_len, enc_output, context_attn_mask=None):
output = self.seq_embedding(inputs)
output += self.pos_embedding(inputs_len)
print('==output.shape:', output.shape)
self_attention_padding_mask = padding_mask(inputs, inputs)
seq_mask = sequence_mask(inputs)
self_attn_mask = torch.gt((self_attention_padding_mask + seq_mask), 0)
self_attentions = []
context_attentions = []
for decoder in self.decoder_layers:
# [B, sequence, model_dim] [B* num_heads, sequence, sequence] [B* num_heads, sequence, sequence]
output, self_attn, context_attn = decoder(
output, enc_output, self_attn_mask=None, context_attn_mask=None)
self_attentions.append(self_attn)
context_attentions.append(context_attn)
return output, self_attentions, context_attentions
def debug_decoder():
Bs = 2
model_dim = 512
vocab_size = 6000 #词汇数
inputs_len = np.random.randint(1, 5, Bs).reshape(Bs, 1)#batch里每句话的单词个数
inputs_len = torch.from_numpy(inputs_len) # [Bs, 1]
max_seq_len = int(max(inputs_len))
x = np.zeros((Bs, max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(inputs_len[s][0]):
x[s][j] = j + 1
x = torch.LongTensor(torch.from_numpy(x))#模拟每个单词
# x = torch.LongTensor([list(range(1, max_seq_len + 1)) for _ in range(Bs)])
print('==x:', x)
print('==x.shape:', x.shape)
model = Decoder(vocab_size=vocab_size, max_seq_len=max_seq_len, model_dim=model_dim)
enc_output = torch.rand(Bs, max_seq_len, model_dim) #[B, sequence, model_dim]
print('==enc_output.shape:', enc_output.shape)
out, self_attentions, context_attentions = model(inputs=x, inputs_len=inputs_len, enc_output=enc_output)
print('==out.shape:', out.shape)#[B, sequence, model_dim]
print('==len(self_attentions):', len(self_attentions), self_attentions[0].shape)
print('==len(context_attentions):', len(context_attentions), context_attentions[0].shape)
if __name__ == '__main__':
debug_decoder()
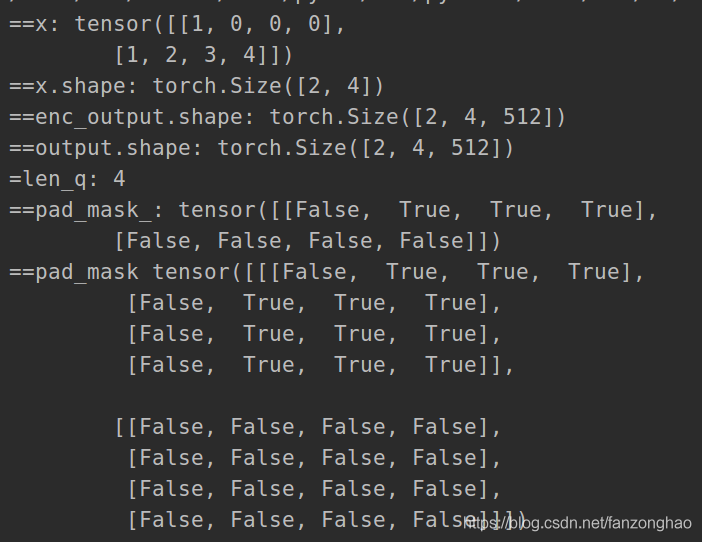

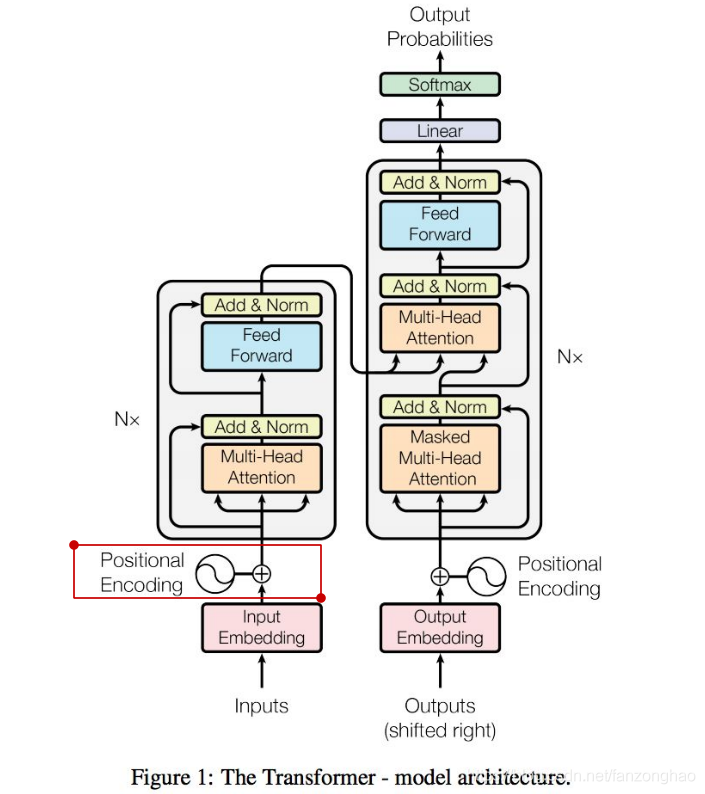
9.transformer
将encoder和decoder组合起来即可.
class Transformer(nn.Module):
def __init__(self,
src_vocab_size,
src_max_len,
tgt_vocab_size,
tgt_max_len,
num_layers=6,
model_dim=512,
num_heads=8,
ffn_dim=2048,
dropout=0.2):
super(Transformer, self).__init__()
self.encoder = Encoder(src_vocab_size, src_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.decoder = Decoder(tgt_vocab_size, tgt_max_len, num_layers, model_dim,
num_heads, ffn_dim, dropout)
self.linear = nn.Linear(model_dim, tgt_vocab_size, bias=False)
self.softmax = nn.Softmax(dim=2)
def forward(self, src_seq, src_len, tgt_seq, tgt_len):
context_attn_mask = padding_mask(tgt_seq, src_seq)
print('==context_attn_mask.shape', context_attn_mask.shape)
output, enc_self_attn = self.encoder(src_seq, src_len)
output, dec_self_attn, ctx_attn = self.decoder(
tgt_seq, tgt_len, output, context_attn_mask)
output = self.linear(output)
output = self.softmax(output)
return output, enc_self_attn, dec_self_attn, ctx_attn
def debug_transoform():
Bs = 4
#需要翻译的
encode_inputs_len = np.random.randint(1, 10, Bs).reshape(Bs, 1)
src_vocab_size = 6000 # 词汇数
encode_max_seq_len = int(max(encode_inputs_len))
encode_x = np.zeros((Bs, encode_max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(encode_inputs_len[s][0]):
encode_x[s][j] = j + 1
encode_x = torch.LongTensor(torch.from_numpy(encode_x))
#翻译的结果
decode_inputs_len = np.random.randint(1, 10, Bs).reshape(Bs, 1)
target_vocab_size = 5000 # 词汇数
decode_max_seq_len = int(max(decode_inputs_len))
decode_x = np.zeros((Bs, decode_max_seq_len), dtype=np.int)
for s in range(Bs):
for j in range(decode_inputs_len[s][0]):
decode_x[s][j] = j + 1
decode_x = torch.LongTensor(torch.from_numpy(decode_x))
encode_inputs_len = torch.from_numpy(encode_inputs_len) # [Bs, 1]
decode_inputs_len = torch.from_numpy(decode_inputs_len) # [Bs, 1]
model = Transformer(src_vocab_size=src_vocab_size, src_max_len=encode_max_seq_len, tgt_vocab_size=target_vocab_size, tgt_max_len=decode_max_seq_len)
# x = torch.LongTensor([list(range(1, max_seq_len + 1)) for _ in range(Bs)])#模拟每个单词
print('==encode_x.shape:', encode_x.shape)
print('==decode_x.shape:', decode_x.shape)
model(encode_x, encode_inputs_len, decode_x, decode_inputs_len)
if __name__ == '__main__':
debug_transoform()
10.总结
(1):相比lstm而言,其能够实现并行,而lstm由于依赖上一时刻只能串行输出;
(2):利用self-attention将每个词之间距离缩短为1,大大缓解了长距离依赖问题,所以网络相比lstm能够堆叠得更深;
 ? ? ? ? ? ? ? ? ? ? ??
? ? ? ? ? ? ? ? ? ? ??