一.定义
在python中,变量名只有在第一次出现的时候,才是定义变量。当再次出现时,不是定义变量,而是直接调用之前定义的变量。
二.命名方法
2.1小驼峰命名法
第一个单词以小写字母开始,后续单词的首字母大写
firstName , lastName
2.2大驼峰命名法
每一个单词的首字母都采用大写字母
FirstName , LastName
2.3下划线命名法
每个单词之间用下划线连接起来
first_name , last_name
三.命名规则
3.1标识符
开发人员自定义的一些符号和名称
如:变量名、函数名、类名
标识符命名规则
1.只能由数字、字母、下划线组成,且不能以数字开头
2.不能和python中的关键字重名
3.尽量做到见名知义
4.不能使用单字符(i,o)作为变量名,因为太像0和1了
5.函数首字母小写,类的首字母大写
3.2关键字
1.关键字就是在python内部已经使用的标识符
2.关键字具有特殊的功能和含义
3.开发者不允许定义和关键字相同的名字的标识符
注意:
1.命名规则可以被视为一种惯例,无绝对与强制,目的是为了增加代码的识别和可读性
2.python中的标识符是区分大小写的
3.在定义变量时,为了保证代码格式,遵循PEP8规范,等号(=)的左右两边该各保留一个空格
四.使用方法
4.1单变量赋值:
变量名 = 值
例:a = 1
在python中赋值语句总是建立对象的引用值,而不是复制对象。因此,python中的变量存储的是引用数据的内存地址,而不是数据存储区域。
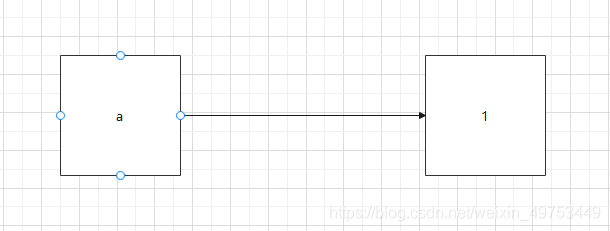
当涉及多个变量时:
a = 1
b = a
c = b
print(a) # 1
print(id(a)) # 140710098927888
print(b) # 1
print(id(b)) # 140710098927888
print(c) # 1
print(id(c)) # 140710098927888
a、b、c三个变量的值都等于1,即使在最初定义变量的时候b和c不是直接等于1的,但是他们仍然存储着指向“1”的内存地址。
4.2底层逻辑:
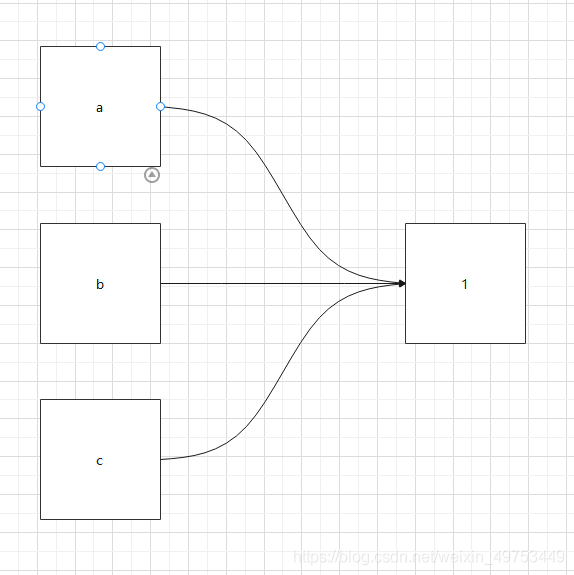
4.3总结:
可以说Python中没有赋值,只有引用。Python 没有“变量”,我们平时所说的变量其实只是“标签”,是引用。
当创建了无数个变量=1时,在内存中,只会开辟无数个空间存储变量,再开辟一个空间存储“1”,而这些变量中存储的内存地址都相同,全都指向“1”的内存地址。
在代码层面,看起来像是给变量赋值,但是在底层却是变量指向值,也就是变量引用了值。
相信大家还有疑问,那么请继续阅读
5.变量进阶
先提出一个问题:
a = [0, 1, 2]
a[1] = a
print(a)
猜想结果是:
但是真正的结果是:
为什么结果会赋值了无限次??
结合刚才得出的结论:Python中没有赋值,只有引用。
真相是:
这样相当于创建了一个引用自身的结构,所以导致了无限循环。
通过递归函数可能更好理解:
a = [0,1,2]
a[1] = a
def fun1(n1):
for i in n1:
if type(i) == list:
return fun1(n1)
else:
print(i)
print(fun1(a[1]))
结果:
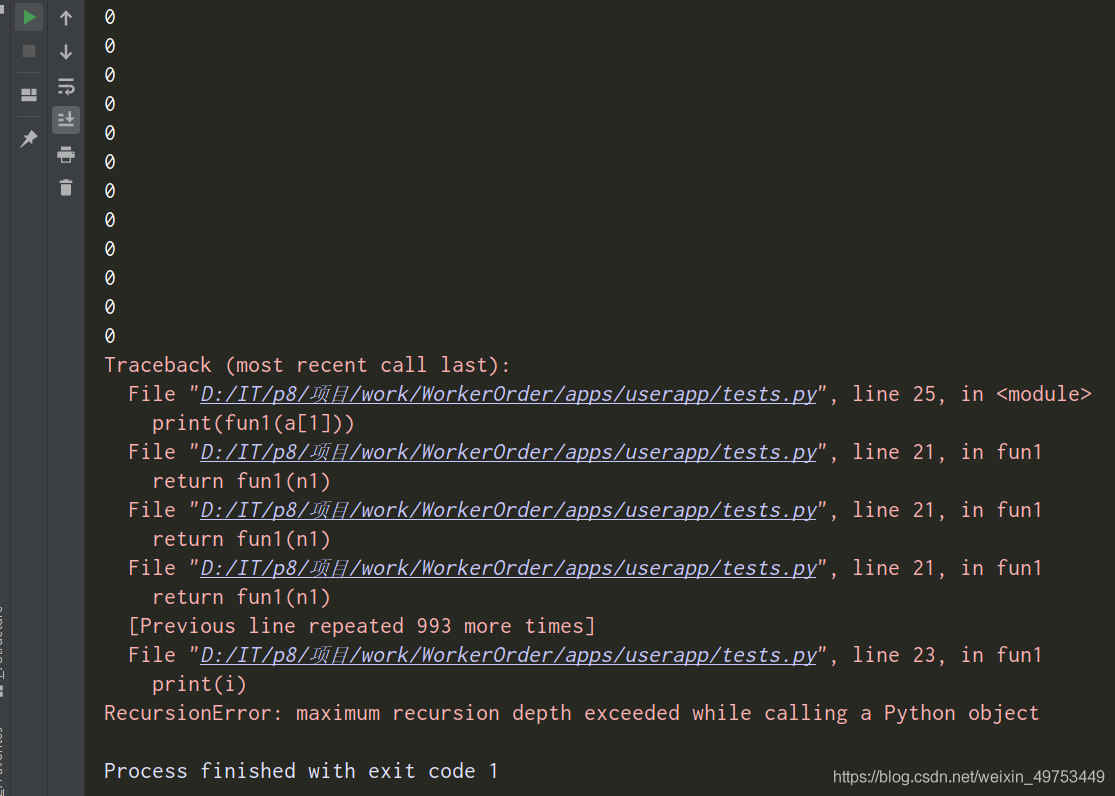
果然是:调用Python对象时超出最大递归深度。
底层逻辑:a[1] = a 造成了递归引用
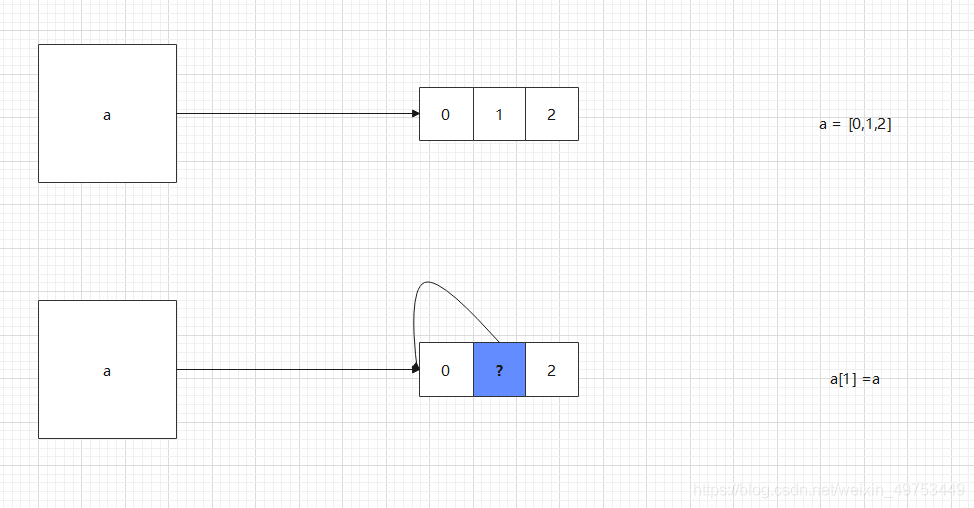
当调用变量a时,就是调用[0,1,2],此时 [0,1,2] 的结构变成了 [0,?,2] ,而 ? 又指向 [0,?,2] 本身,以此类推,造成了递归调用的情况。
所以在遍历a并输出的时候会引起超出最大递归深度的错误。
想得到 [0, [0, 1, 2], 2] 的结果并不难:
a = [0,1,2]
a[1] = a[:]
print(a) # [0, [0, 1, 2], 2]
a[:] = a[0:尾部索引值:1]
生成对象的浅拷贝或者是复制序列,不再是引用和共享变量,但此法只能顶层复制
6. a = a + 1 和 a += 1 的区别
既然谈到了赋值和引用的区别,那就捎带谈一下a = a + 1 和 a += 1 的区别:
直接上代码:
a = [1, 2]
b = a
print(id(a)) # 1878561149448
print(id(b)) # 1878561149448
a = a + [1, 2]
print(a, b) # [1, 2, 1, 2] [1, 2]
print(id(a)) # 1878593529288
print(id(b)) # 1878561149448
print ("-------------------")
a = [1, 2]
b = a
print(id(a)) # 1878561149960
print(id(b)) # 1878561149960
a += [1, 2]
print(a, b) # [1, 2, 1, 2] [1, 2, 1, 2]
print(id(a)) # 1878561149960
print(id(b)) # 1878561149960
通过对比发现问题:变量a通过“=” 和 “+=”运算,得到的变量b竟然是不同的,运算后变量a的id竟然也是不同的。
执行a = a + [1, 2] 后:
变量b指向的值并未发生改变,而变量a的id发生了变化,值也发生了变化
执行a += [1, 2] 后:
变量a和b的值都发生了改变,而二者的id却没有改变
具体原因,看图说话:
执行a = a + [1, 2] 后,会生成一个新对象,并在cpu上开辟一块空间存储 a + [1, 2] ,然后由a指向它。所以变量a的id发生了变化,值也发生了变化。此时变量b指向的值并未发生改变。
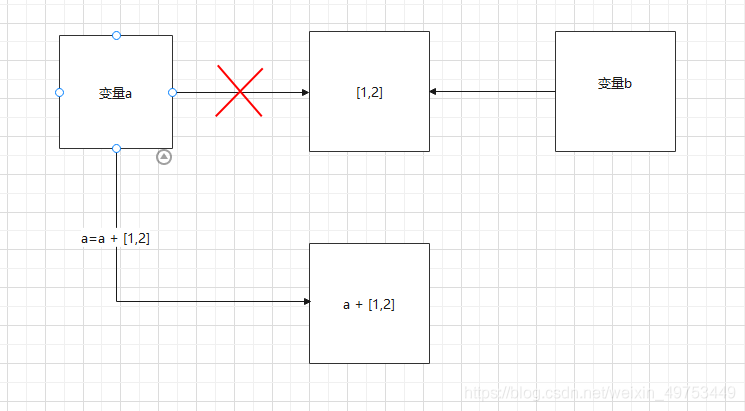
执行a += [1, 2] 后:并不会生成新对象,只是把a原本指向内存地址的对象的值改变成了 a + [1, 2],所以变量a和b的值都发生了改变,而二者的id却没有改变。
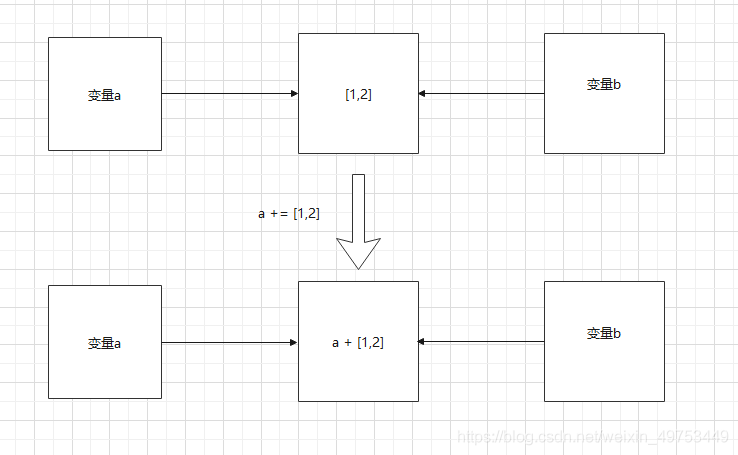
对于可变对象类型和不可变对象类型有不同的结果:
可变对象类型:+=改变了原本地址上对象的值,不改变原本的指向地址;=则改变了原本的指向地址,创建了新的对象,并指向新的地址
不可改变对象类型:都是改变原本的指向地址,指向新创建的对象地址
a = 'abc'
b = a
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
a = a + 'd'
print(a, b) # abcd abc
print(id(a)) # 1629835853168
print(id(b)) # 1629835782384
print ("-------------------")
a = 'abc'
b = a
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
a += 'd'
print(a, b) # abcd abc
print(id(a)) # 1629835782384
print(id(b)) # 1629835782384
js