前言
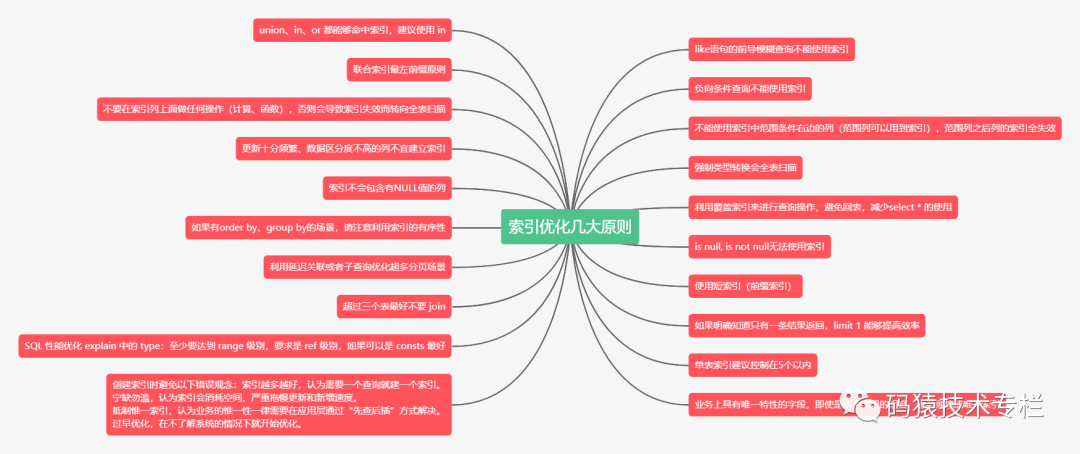
索引优化规则
1、like语句的前导模糊查询不能使用索引
select?*?from?doc?where?title?like?'%XX';???--不能使用索引
select?*?from?doc?where?title?like?'XX%';???--非前导模糊查询,可以使用索引
2、union、in、or 都能够命中索引,建议使用 in
union能够命中索引,并且MySQL 耗费的 CPU 最少。
select?*?from?doc?where?status=1
union?all
select?*?from?doc?where?status=2;
in能够命中索引,查询优化耗费的 CPU 比 union all 多,但可以忽略不计,一般情况下建议使用 in。
select?*?from?doc?where?status?in?(1,?2);
or 新版的 MySQL 能够命中索引,查询优化耗费的 CPU 比 in多,不建议频繁用or。
select?*?from?doc?where?status?=?1?or?status?=?2
补充:有些地方说在where条件中使用or,索引会失效,造成全表扫描,这是个误区:
①要求where子句使用的所有字段,都必须建立索引;
②如果数据量太少,mysql制定执行计划时发现全表扫描比索引查找更快,所以会不使用索引;
③确保mysql版本5.0以上,且查询优化器开启了index_merge_union=on, 也就是变量optimizer_switch里存在index_merge_union且为on。
3、负向条件查询不能使用索引
select?*?from?doc?where?status?!=?1?and?status?!=?2;
select?*?from?doc?where?status?in?(0,3,4);
4、联合索引最左前缀原则
如果在(a,b,c)三个字段上建立联合索引,那么他会自动建立 a| (a,b) | (a,b,c)组索引。
登录业务需求,SQL语句如下:
select?uid,?login_time?from?user?where?login_name=??andpasswd=?
可以建立(login_name, passwd)的联合索引。因为业务上几乎没有passwd 的单条件查询需求,而有很多login_name 的单条件查询需求,所以可以建立(login_name, passwd)的联合索引,而不是(passwd, login_name)。
建立联合索引的时候,区分度最高的字段在最左边
存在非等号和等号混合判断条件时,在建立索引时,把等号条件的列前置。如 where a>? and b=?,那么即使a 的区分度更高,也必须把 b 放在索引的最前列。
最左前缀查询时,并不是指SQL语句的where顺序要和联合索引一致。
select?uid,?login_time?from?user?where?passwd=??andlogin_name=?
假如index(a,b,c), where a=3 and b like 'abc%' and c=4,a能用,b能用,c不能用。
5、不能使用索引中范围条件右边的列(范围列可以用到索引),范围列之后列的索引全失效
范围条件有:<、<=、>、>=、between等。
索引最多用于一个范围列,如果查询条件中有两个范围列则无法全用到索引。
假如有联合索引 (empno、title、fromdate),那么下面的 SQL 中 emp_no 可以用到索引,而title 和 from_date 则使用不到索引。
select?*?from?employees.titles?where?emp_no?<?10010'?and?title='Senior?Engineer'and?from_date?between?'1986-01-01'?and?'1986-12-31'
6、不要在索引列上面做任何操作(计算、函数),否则会导致索引失效而转向全表扫描
select?*?from?doc?where?YEAR(create_time)?<=?'2016';
select?*?from?doc?where?create_time?<=?'2016-01-01';
select?*?from?order?where?date?<?=?CURDATE();
select?*?from?order?where?date?<?=?'2018-01-2412:00:00';
7、强制类型转换会全表扫描
select?*?from?user?where?phone=13800001234
select?*?from?user?where?phone='13800001234';
8、更新十分频繁、数据区分度不高的列不宜建立索引
更新会变更 B+ 树,更新频繁的字段建立索引会大大降低数据库性能。
“性别”这种区分度不大的属性,建立索引是没有什么意义的,不能有效过滤数据,性能与全表扫描类似。
一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算。
9、利用覆盖索引来进行查询操作,避免回表,减少select * 的使用
Select?uid,?login_time?from?user?where?login_name=??and?passwd=?
10、索引不会包含有NULL值的列
11、is null, is not null无法使用索引
12、如果有order by、group by的场景,请注意利用索引的有序性
order by 最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现file_sort 的情况,影响查询性能。
如果索引中有范围查找,那么索引有序性无法利用,如WHERE a>10 ORDER BY b;,索引(a,b)无法排序。
13、使用短索引(前缀索引)
对列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个CHAR(255)的列,如果该列在前10个或20个字符内,可以做到既使得前缀索引的区分度接近全列索引,那么就不要对整个列进行索引。因为短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作,减少索引文件的维护开销。可以使用count(distinct leftIndex(列名, 索引长度))/count(*) 来计算前缀索引的区分度。
但缺点是不能用于 ORDER BY 和 GROUP BY 操作,也不能用于覆盖索引。
不过很多时候没必要对全字段建立索引,根据实际文本区分度决定索引长度即可。
14、利用延迟关联或者子查询优化超多分页场景
selecta.*?from?表1?a,(select?id?from?表1?where?条件?limit100000,20?)?b?where?a.id=b.id;
15、如果明确知道只有一条结果返回,limit 1 能够提高效率
select?*?from?user?where?login_name=?;
select?*?from?user?where?login_name=??limit?1
16、超过三个表最好不要 join
17、单表索引建议控制在5个以内
18、SQL 性能优化 explain 中的 type:至少要达到 range 级别,要求是 ref 级别,如果可以是 consts 最好
consts:单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
ref:使用普通的索引(Normal Index)。
range:对索引进行范围检索。
当 type=index 时,索引物理文件全扫,速度非常慢。
19、业务上具有唯一特性的字段,即使是多个字段的组合,也必须建成唯一索引
20.创建索引时避免以下错误观念
索引越多越好,认为需要一个查询就建一个索引。
宁缺勿滥,认为索引会消耗空间、严重拖慢更新和新增速度。
抵制惟一索引,认为业务的惟一性一律需要在应用层通过“先查后插”方式解决。
过早优化,在不了解系统的情况下就开始优化。
索引选择性与前缀索引
既然索引可以加快查询速度,那么是不是只要是查询语句需要,就建上索引?答案是否定的。因为索引虽然加快了查询速度,但索引也是有代价的:索引文件本身要消耗存储空间,同时索引会加重插入、删除和修改记录时的负担,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。一般两种情况下不建议建索引。
第一种情况是表记录比较少,例如一两千条甚至只有几百条记录的表,没必要建索引,让查询做全表扫描就好了。至于多少条记录才算多,这个个人有个人的看法,我个人的经验是以2000作为分界线,记录数不超过 2000可以考虑不建索引,超过2000条可以酌情考虑索引。
另一种不建议建索引的情况是索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值:
Index?Selectivity?=?Cardinality?/?#T
SELECT?count(DISTINCT(title))/count(*)?AS?Selectivity?FROM?employees.titles;
+-------------+
|?Selectivity?|
+-------------+
|??????0.0000?|
+-------------+
title的选择性不足0.0001(精确值为0.00001579),所以实在没有什么必要为其单独建索引。
有一种与索引选择性有关的索引优化策略叫做前缀索引,就是用列的前缀代替整个列作为索引key,当前缀长度合适时,可以做到既使得前缀索引的选择性接近全列索引,同时因为索引key变短而减少了索引文件的大小和维护开销。下面以employees.employees表为例介绍前缀索引的选择和使用。
假设employees表只有一个索引<emp_no>,那么如果我们想按名字搜索一个人,就只能全表扫描了:
EXPLAIN?SELECT?*?FROM?employees.employees?WHERE?first_name='Eric'?AND?last_name='Anido';
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
|?id?|?select_type?|?table?????|?type?|?possible_keys?|?key??|?key_len?|?ref??|?rows???|?Extra???????|
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
|??1?|?SIMPLE??????|?employees?|?ALL??|?NULL??????????|?NULL?|?NULL????|?NULL?|?300024?|?Using?where?|
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
SELECT?count(DISTINCT(first_name))/count(*)?AS?Selectivity?FROM?employees.employees;
+-------------+
|?Selectivity?|
+-------------+
|??????0.0042?|
+-------------+
SELECT?count(DISTINCT(concat(first_name,?last_name)))/count(*)?AS?Selectivity?FROM?employees.employees;
+-------------+
|?Selectivity?|
+-------------+
|??????0.9313?|
+-------------+
<first_name>显然选择性太低,``<first_name, last_name>选择性很好,但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如<first_name, left(last_name, 3)>`,看看其选择性:
SELECT?count(DISTINCT(concat(first_name,?left(last_name,?3))))/count(*)?AS?Selectivity?FROM?employees.employees;
+-------------+
|?Selectivity?|
+-------------+
|??????0.7879?|
+-------------+
SELECT?count(DISTINCT(concat(first_name,?left(last_name,?4))))/count(*)?AS?Selectivity?FROM?employees.employees;
+-------------+
|?Selectivity?|
+-------------+
|??????0.9007?|
+-------------+
ALTER?TABLE?employees.employees
ADD?INDEX?`first_name_last_name4`?(first_name,?last_name(4));
SHOW?PROFILES;
+----------+------------+---------------------------------------------------------------------------------+
|?Query_ID?|?Duration???|?Query???????????????????????????????????????????????????????????????????????????|
+----------+------------+---------------------------------------------------------------------------------+
|???????87?|?0.11941700?|?SELECT?*?FROM?employees.employees?WHERE?first_name='Eric'?AND?last_name='Anido'?|
|???????90?|?0.00092400?|?SELECT?*?FROM?employees.employees?WHERE?first_name='Eric'?AND?last_name='Anido'?|
+----------+------------+---------------------------------------------------------------------------------+
总结
cs