ФПТМ
- ЧАбд
- вЛЁЂМйдьЪ§Он
- ЖўЁЂГЬађбнЪО
- 1ЁЂНЋвЛИіДѓExcelЕШЗнВ№ГЩЖрИіExcel
- 2ЁЂКЯВЂЖрИіаЁExcelЕНвЛИіДѓExcel
- змНс
ЧАбд
БЪепзюНќе§дкбЇЯАPandasЪ§ОнЗжЮіЃЌНЋздМКЕФбЇЯАБЪМЧзіГЩвЛЬзЯЕСаЮФеТЁЃБОНкжївЊМЧТМPandasжаЪ§ОнЕФКЯВЂ(concatКЭappend)
НЋвЛИіДѓЕФExcelЕШЗнВ№ГЩЖрИіExcelНЋЖрИіаЁExcelКЯВЂГЩвЛИіДѓЕФExcelВЂЧвБъМЧРДдД
вЛЁЂМйдьЪ§Он
work_dir="./datas"
splits_dir=f"{work_dir}/splits"
import os
if not os.path.exists(splits_dir):
os.mkdir(splits_dir)
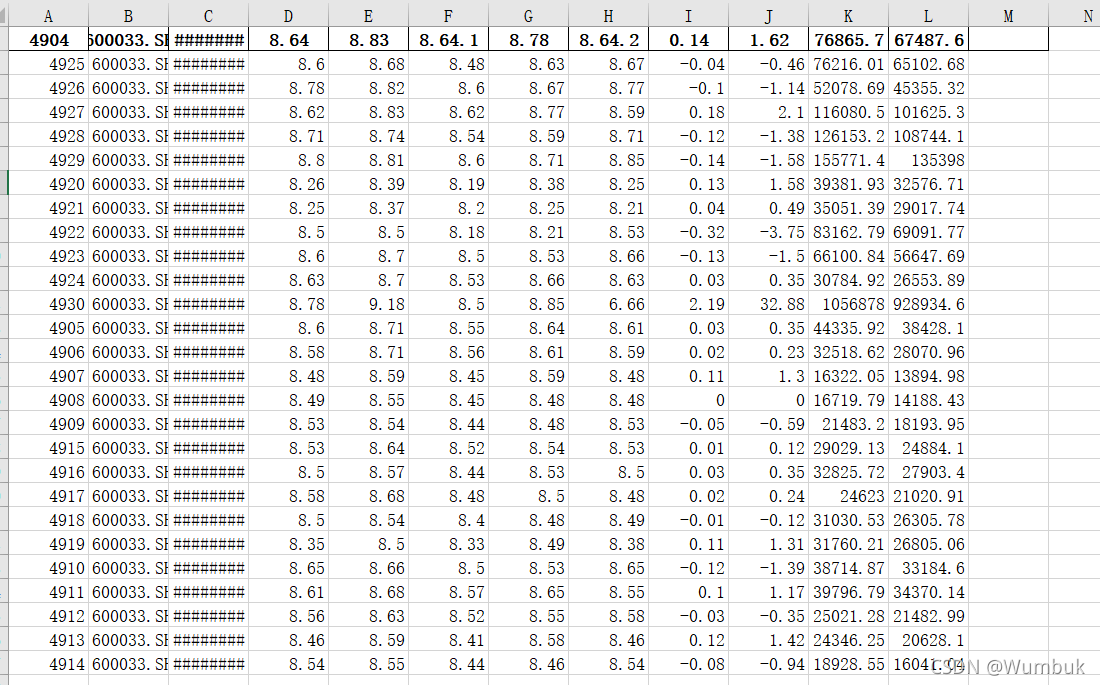
#0.ЖСШЁдДExcelЕНPandas
import pandas as pd
df_source=pd.read_excel(f"{work_dir}/1.xlsx")
df_source.head()
df_source.index
df_source.shape
total_row_count=df_source.shape[0]
total_row_count
ЖўЁЂГЬађбнЪО
1ЁЂНЋвЛИіДѓExcelЕШЗнВ№ГЩЖрИіExcel
- ЪЙгУdf.ilocЗНЗЈЃЌНЋвЛИіДѓЕФdataframeЃЌВ№ЗжГЩЖрИіаЁЕФdataframe
- НЋЪЙгУdataframe.to_excelБЃДцУПИіаЁЕФExcel
#1.МЦЫуВ№ЗжКѓЕФУПИіexcelЕФааЪ§
#етИіДѓexcelЃЌЛсВ№ЗжИјетМИИіШЫ
user_names=['xiao_shuai',"xiao_wang","xiao_ming","xiao_lei","xiao_bo","xiao_hong"]
#УПИіШЫЕФШЫЪ§Ъ§ФП
split_size=total_row_count//len(user_names)
if total_row_count%len(user_names)!=0:
split_size+=1
split_size
#В№ЗжГЩЖрИіdataframe
df_subs=[]
for idx,user_name in enumerate(user_names):
#ilocЕФПЊЪМЫїв§
begin=idx*split_size
#ilocЕФНсЪјЫїв§
end=begin+split_size
#ЪЕЯжdfАДееilocВ№Зж
df_sub=df_source.iloc[begin:end]
#НЋУПИізгdfДцШыЕНСаБэ
df_subs.append((idx,user_name,df_sub))
#3. НЋУПИіdataframeДцШыЕНexcel
for idx,user_name,df_sub in df_subs:
file_name=f"{splits_dir}/articles_{idx}_{user_name}.xlsx"
df_sub.to_excel(file_name,index=False)
2ЁЂКЯВЂЖрИіаЁExcelЕНвЛИіДѓExcel
- БщРњЮФМўМаЃЌЕУЕНвЊКЯВЂЕФExcelЮФМўСаБэ
- ЗжБ№ЖСШЁЕНdataframeЃЌИјУПИіdfЬэМгвЛСагУгкБъМЧРДдД
- ЪЙгУpd.concatНјааdfХњСПКЯВЂ
- НЋКЯВЂКѓЕФdataframeЪфГіЕНexcel
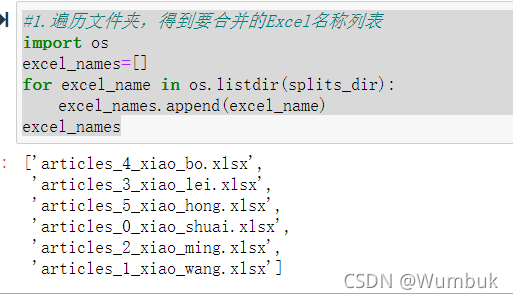
#1.БщРњЮФМўМаЃЌЕУЕНвЊКЯВЂЕФExcelУћГЦСаБэ
import os
excel_names=[]
for excel_name in os.listdir(splits_dir):
excel_names.append(excel_name)
excel_names
#2ЗжБ№ЖСШЁЕНdataframe
df_list=[]
for excel_name in excel_names:
#ЖСШЁУПИіexcelЕНdf
excel_path=f"{splits_dir}/{excel_name}"
df_split=pd.read_excel(excel_path)
#ЕУЕНusername
username=excel_name.replace("articles_","").replace(".xlsx","")[2:]
print(excel_name,username)
#ИјУПИіdfЬэМг1СаЃЌМДгУЛЇУћзж
df_split["username"]=username
df_list.append(df_split)
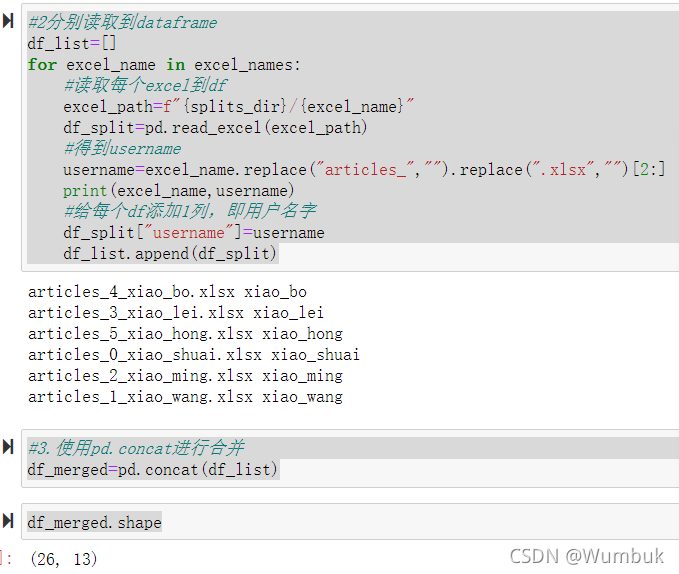
#3.ЪЙгУpd.concatНјааКЯВЂ
df_merged=pd.concat(df_list)
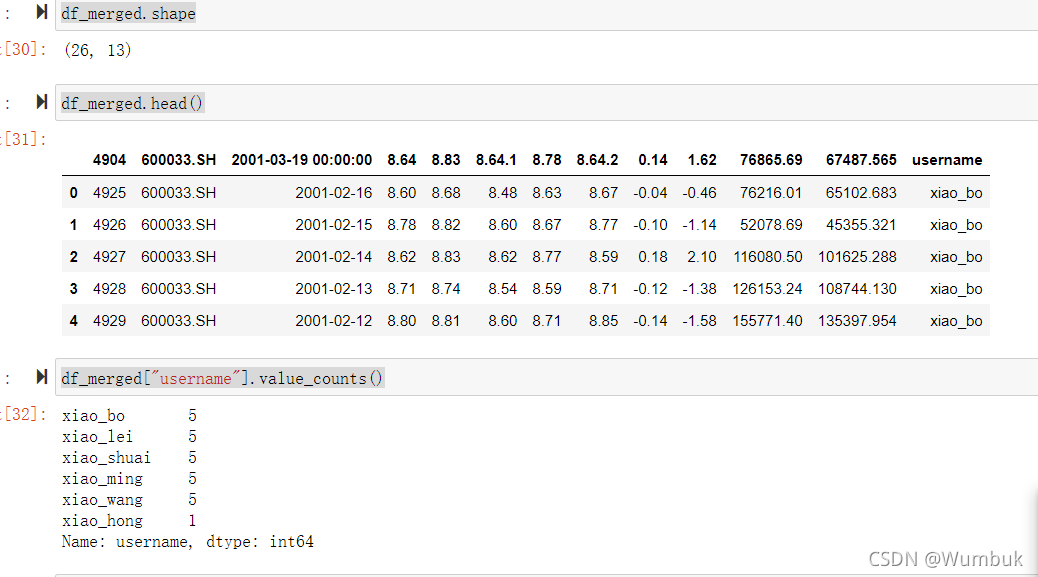
df_merged.shape
df_merged.head()
df_merged["username"].value_counts()
#4.НЋКЯВЂКѓЕФdataframeЪфГіЕНexcel
df_merged.to_excel(f"{work_dir}/result_merged.xlsx",index=False)
змНс
етОЭЪЧpandasЕФDataFrameКЭДцДЂЮФМўжЎМфзЊЛЛЕФЛљБОгУЗЈСЫЃЌЯЃЭћПЩвдАяжњЕНФуЁЃ
jsjbwy