

作者 | 荣仔!最靓的仔!
责编 | 王晓曼
出品 | CSDN博客

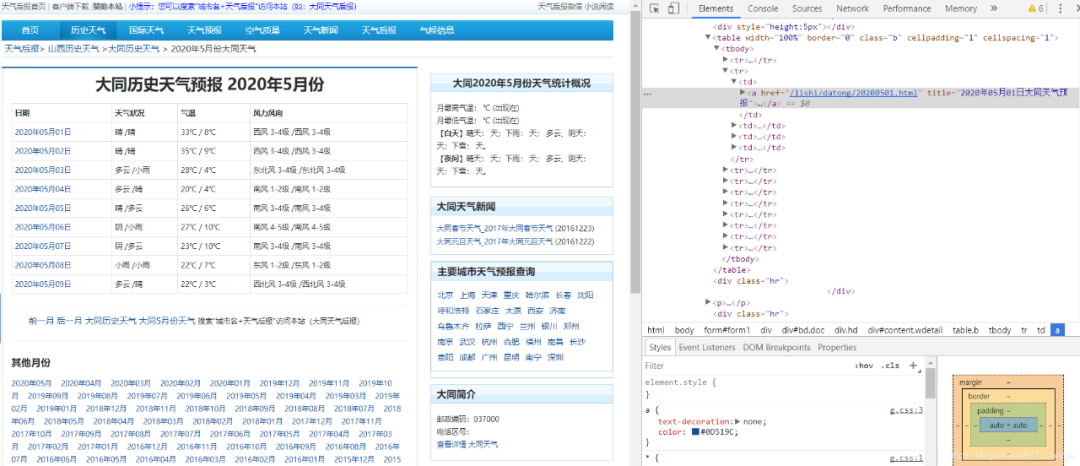
天气数据集爬取
?
爬取思路:
import?requests
from?bs4?import?BeautifulSoup
import?pandas?as?pd
def?get_data(url):
????#?请求网页(第三方?requests)
????resp?=?requests.get(url)
????#?对于获取到的?HTML?二进制文件进行?'gbk'?转码成字符串文件
????html?=?resp.content.decode('gbk')
????#?通过第三方库?BeautifulSoup?缩小查找范围(同样作用的包库还有re模块、xpath等)
????soup?=?BeautifulSoup(html,'html.parser')
????#?获取?HTML?中所有<tr>…</tr>标签,因为我们需要的数据全部在此标签中存放
????tr_list?=?soup.find_all('tr')
????#?初始化日期dates、气候contains、温度temp值
????dates,contains,temp?=?[],[],[]
????for?data?in?tr_list[1:]:??#?不要表头
????????#?数据值拆分,方便进一步处理(这里可以将获得的列表输出[已注释],不理解的读者可运行查看)
????????sub_data?=?data.text.split()
????????#?print(sub_data)
????????#?观察上一步获得的列表,这里只想要获得列表中第二个和第三个值,采用切片法获取
????????dates.append(sub_data[0])
????????contains.append(','.join(sub_data[1:3]))
????????#?print(contains)
????????#?同理采用切片方式获取列表中的最高、最低气温
????????temp.append(','.join(sub_data[3:6]))
????????#?print(temp)
????#?使用?_data?表存放日期、天气状况、气温表头及其值
????_data?=?pd.DataFrame()
????#?分别将对应值传入?_data?表中
????_data['日期']?=?dates
????_data['天气状况']?=?contains
????_data['气温']?=?temp
????return?_data
#?爬取目标网页(大同市2020年5月份天气[网站:天气后报])
data_5_month?=?get_data('http://www.tianqihoubao.com/lishi/datong/month/202005.html')
#?拼接所有表并重新设置行索引(若不进行此步操作,可能或出现多个标签相同的值)
data?=?pd.concat([data_5_month]).reset_index(drop?=?True)
#?将?_data 表以 .csv 格式存入指定文件夹中,并设置转码格式防止乱花(注:此转码格式可与 HTML 二进制转字符串的转码格式不同)
data.to_csv('F:/DaTong5Mouth.csv',encoding='utf-8')

数据可视化
?
数据可视化用到了可视化工具。
其要点包含有:读取数据、数据清洗、数据处理、可视化工具的使用。
#?数据可视化
from?matplotlib?import?pyplot?as?plt
import?pandas?as?pd
#?解决显示中文问题
plt.rcParams['font.sans-serif']?=?['SimHei']
#?第一步:数据读取
data?=?pd.read_csv('F:/DaTong5Mouth.csv')
#?第二步:数据处理(由于我们知道文本内容,不存在脏数据,故忽略数据清理步骤)
data['最高气温']?=?data['气温'].str.split('/',expand=True)[0]
data['最低气温']?=?data['气温'].str.split('/',expand=True)[1]
data['最高气温']?=?data['最高气温'].map(lambda?x:x.replace('℃,',''))
data['最低气温']?=?data['最低气温'].map(lambda?x:x.replace('℃,',''))
dates?=?data['日期']
highs?=?data['最高气温']
lows?=?data['最低气温']
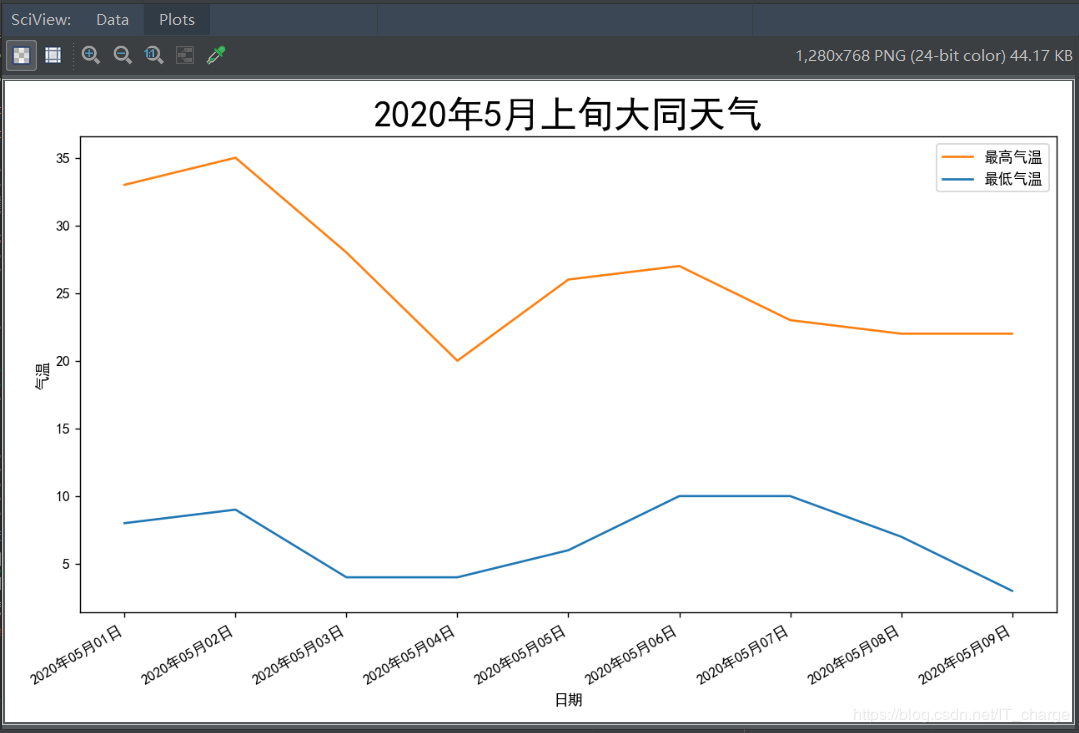
#?画图(折线图)
#?设置画布大小及比例
fig?=?plt.figure(dpi=128,figsize=(10,6))
#?设置最高温最低温线条颜色及宽度等信息
L1,=plt.plot(dates,lows,label='最低气温')
L2,=plt.plot(dates,highs,label='最高气温')
plt.legend(handles=[L1,L2],labels=['最高气温','最低气温'],?loc='best')#?添加图例
#?图表格式
#?设置图形格式
plt.title('2020年5月上旬大同天气',fontsize=25)??#?字体大小设置为25
plt.xlabel('日期',fontsize=10)???#?x轴显示“日期”,字体大小设置为10
fig.autofmt_xdate()?#?绘制斜的日期标签,避免重叠
plt.ylabel('气温',fontsize=10)??#?y轴显示“气温”,字体大小设置为10
plt.tick_params(axis='both',which='major',labelsize=10)
#?plt.plot(highs,lows,label?=?'最高气温')
#?修改刻度
plt.xticks(dates[::1])??#?由于数据不多,将每天的数据全部显示出来
#?显示折线图
plt.show()

模型预测数据
?
1、单变量线性回归
模型一:单变量线性回归模型
import?numpy?as?np
import?pandas?as?pd
import?matplotlib.pyplot?as?plt
#?解决中文问题(若没有此步骤,表名字及横纵坐标中的汉语将无法显示[具体会显示矩形小方格])
plt.rcParams['font.sans-serif']?=?['SimHei']
#?将数据从上一步存入的?.csv?格式文件中读取
data?=?pd.read_csv(r'F:\DaTong5Mouth.csv')
#?由于最高气温与最低气温中有?/?分隔,故将其分开,即“气温”列由一列变为两列――“最高气温”和“最低气温”
data['最高气温']?=?data['气温'].str.split('/',expand=True)[0]
#?我们要对数值进行分析,所以将多余的单位?℃?从列表中去掉,只保留数值部分
data['最高气温']?=?data['最高气温'].map(lambda?x:x.replace('℃,',''))
#?日次操作同理,这里不再赘述
data['日期']?=?data['日期'].map(lambda?x:x.replace('2020年05月0',''))
data['日期']?=?data['日期'].map(lambda?x:x.replace('日',''))
#?不理解的小伙伴可运行下两行代码查看运行结果(这里先注释掉了)
#?print(data['日期'])
#?print(data['最高气温'])
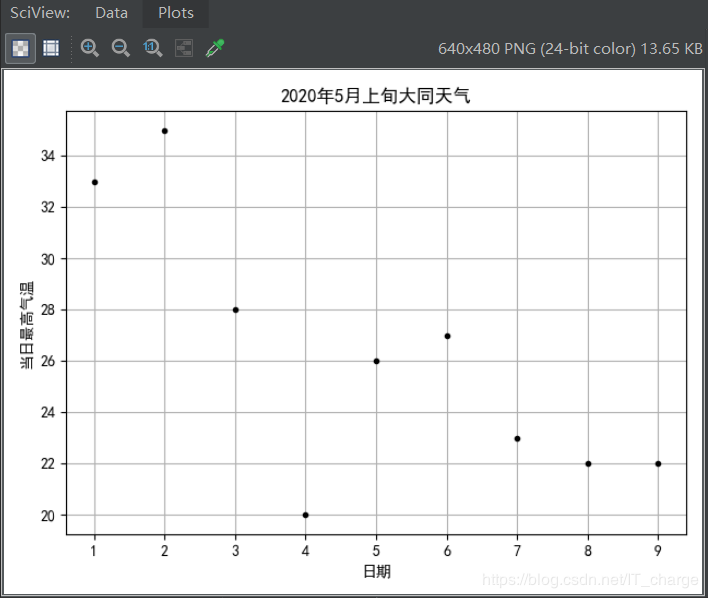
def?initPlot():
????#?先准备好一块画布
????plt.figure()
????#?生成图表的名字
????plt.title('2020年5月上旬大同天气')
????#?横坐标名字
????plt.xlabel('日期')
????#?纵坐标名字
????plt.ylabel('当日最高气温')
????#?表内有栅格(不想要栅格把此行注释掉即可)
????plt.grid(True)?
????return?plt
plt?=?initPlot()??#?画图
#?传入对应日期及其最高气温参数
xTrain?=?np.array([1,2,3,4,5,6,7,8,9])
yTrain?=?np.array([33,35,28,20,26,27,23,22,22])
#?k是黑色,.是以点作为图上显示
plt.plot(xTrain,?yTrain,?'k.')
#?将图显示出来
plt.show()
可以看到:
解决方案:
采用Python scikit-learn库中提供的sklearn.linear_model.LinearRegression对象来进行线性拟合。
根据判别函数,绘制拟合直线,并同时显示训练数据点。
拟合的直线较好的穿过训练数据,根据新拟合的直线,可以方便的求出最近日期下对应的最高气温(预测结果)。
import?numpy?as?np
import?pandas?as?pd
import?matplotlib.pyplot?as?plt
from?sklearn.linear_model?import?LinearRegression
#?解决中文问题(若没有此步骤,表名字及横纵坐标中的汉语将无法显示[具体会显示矩形小方格])
plt.rcParams['font.sans-serif']?=?['SimHei']
#?将数据从上一步存入的?.csv?格式文件中读取
data?=?pd.read_csv(r'F:\DaTong5Mouth.csv')
#?由于最高气温与最低气温中有?/?分隔,故将其分开,即“气温”列由一列变为两列――“最高气温”和“最低气温”
data['最高气温']?=?data['气温'].str.split('/',expand=True)[0]
#?我们要对数值进行分析,所以将多余的单位?℃?从列表中去掉,只保留数值部分
data['最高气温']?=?data['最高气温'].map(lambda?x:x.replace('℃,',''))
#?日次操作同理,这里不再赘述
data['日期']?=?data['日期'].map(lambda?x:x.replace('2020年05月0',''))
data['日期']?=?data['日期'].map(lambda?x:x.replace('日',''))
#?不理解的小伙伴可运行下两行代码查看运行结果(这里先注释掉了)
#?print(data['日期'])
#?print(data['最高气温'])
#?传入对应日期及其最高气温参数
#?#?应以矩阵形式表达(对于单变量,矩阵就是列向量形式)
xTrain?=?np.array([1,2,3,4,5,6,7,8,9])[:,?np.newaxis]
#?为方便理解,也转换成列向量
yTrain?=?np.array([33,35,28,20,26,27,23,22,22])
#?创建模型对象
model?=?LinearRegression()
#?根据训练数据拟合出直线(以得到假设函数)
hypothesis?=?model.fit(xTrain,?yTrain)
#?截距
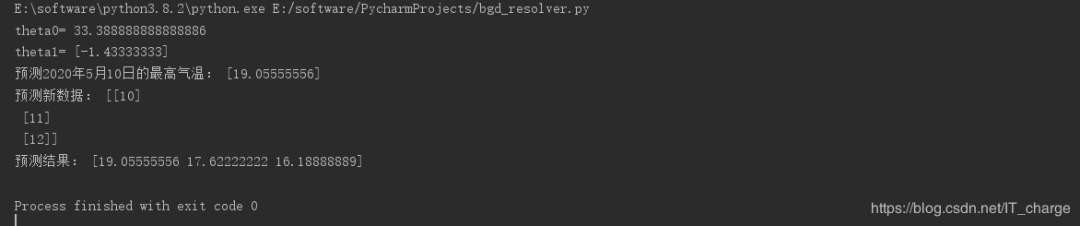
print("theta0=",?hypothesis.intercept_)
#?斜率
print("theta1=",?hypothesis.coef_)
#?预测2020年5月10日的最高气温
print("预测2020年5月10日的最高气温:",?model.predict([[10]]))
#?也可以批量预测多个日期的气温,注意要以列向量形式表达(有余数据集量少,故间隔时间长气温可能有较大差异)
#?此处仅利用模型表示,不代表真实值(假设要预测10号、11号、12号的天气)
xNew?=?np.array([0,10,?11,?12])[:,?np.newaxis]
yNew?=?model.predict(xNew)
print("预测新数据:",?xNew)
print("预测结果:",?yNew)
def?initPlot():
????#?先准备好一块画布
????plt.figure()
????#?生成图表的名字
????plt.title('2020年5月上旬大同天气')
????#?横坐标名字
????plt.xlabel('日期')
????#?纵坐标名字
????plt.ylabel('当日最高气温')
????#?表内有栅格(不想要栅格把此行注释掉即可)
????plt.grid(True)
????return?plt
plt?=?initPlot()??#?画图
#?k是黑色,.是以点作为图上显示
plt.plot(xTrain,?yTrain,?'k.')
#?画出通过这些点的连续直线
plt.plot(xNew,?yNew,?'g--')
#?将图显示出来
plt.show()
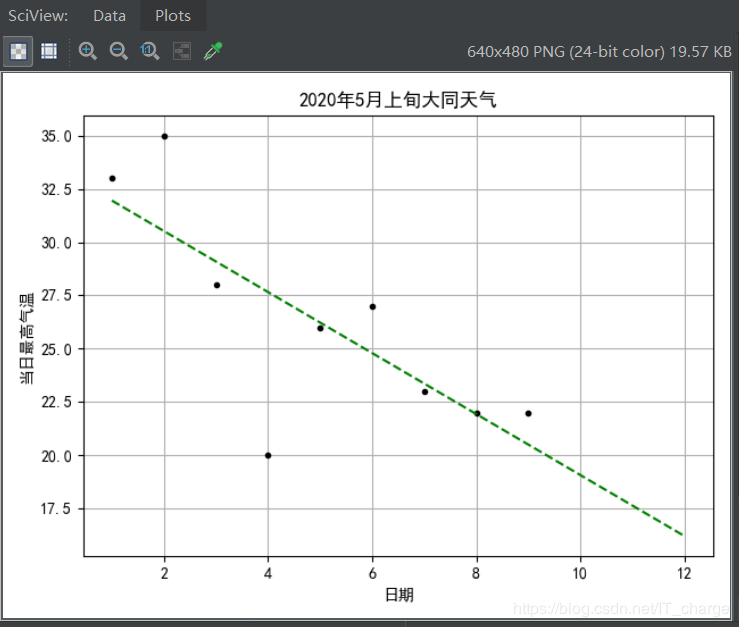
模型评价:
拟合出来的判别函数效果如何:对训练数据的贴合度如何?对新数据的预测准确度如何?
可通过残差(residuals)和R方(r-squared)判断,?在Python中如何对单变量线性回归模型的效果进行评估。
手动计算:
假设hpyTrain代表针对训练数据的预测最高气温值,hpyTest代表针对测试数据的预测最高气温值。
训练数据残差平方和:ssResTrain = sum((hpyTrain - yTrain) ** 2)
测试数据残差平方和:ssResTest = sum((hpyTest - yTest) ** 2)
测试数据偏差平方和:ssTotTest = sum((yTest - np.mean(yTest)) ** 2)
R方:Rsquare = 1 -ssResTest / ssTotTest
LinearRegression对象提供的方法:
import?numpy?as?np
import?pandas?as?pd
import?matplotlib.pyplot?as?plt
from?sklearn.linear_model?import?LinearRegression
#?解决中文问题(若没有此步骤,表名字及横纵坐标中的汉语将无法显示[具体会显示矩形小方格])
plt.rcParams['font.sans-serif']?=?['SimHei']
#?将数据从上一步存入的?.csv?格式文件中读取
data?=?pd.read_csv(r'F:\DaTong5Mouth.csv')
#?由于最高气温与最低气温中有?/?分隔,故将其分开,即“气温”列由一列变为两列――“最高气温”和“最低气温”
data['最高气温']?=?data['气温'].str.split('/',expand=True)[0]
#?我们要对数值进行分析,所以将多余的单位?℃?从列表中去掉,只保留数值部分
data['最高气温']?=?data['最高气温'].map(lambda?x:x.replace('℃,',''))
#?日次操作同理,这里不再赘述
data['日期']?=?data['日期'].map(lambda?x:x.replace('2020年05月0',''))
data['日期']?=?data['日期'].map(lambda?x:x.replace('日',''))
#?不理解的小伙伴可运行下两行代码查看运行结果(这里先注释掉了)
#?print(data['日期'])
#?print(data['最高气温'])
#?传入对应日期及其最高气温参数
#?#?#?应以矩阵形式表达(对于单变量,矩阵就是列向量形式)
#?xTrain?=?np.array(data['日期'])[:,?np.newaxis]
#?#?为方便理解,也转换成列向量
#?yTrain?=?np.array(data['最高气温'])
xTrain?=?np.array([1,2,3,4,5,6,7,8,9])[:,?np.newaxis]??#?训练数据(日期)
yTrain?=?np.array([33,35,28,20,26,27,23,22,22])????????#?训练数据(最高气温)
xTest?=?np.array([3,6,9,10,11])[:,np.newaxis]??????????#?测试数据(日期)
yTest?=?np.array([28,27,22,20,19])????????????????????#?测试数据(最高气温)
#?创建模型对象
model?=?LinearRegression()
#?根据训练数据拟合出直线(以得到假设函数)
hypothesis?=?model.fit(xTrain,?yTrain)
hpyTrain?=?model.predict(xTrain)
#?针对测试数据进行预测
hpyTest?=?model.predict(xTest)
#?手动计算训练数据集残差
ssResTrain?=?sum((hpyTrain?-?yTrain)?**?2)
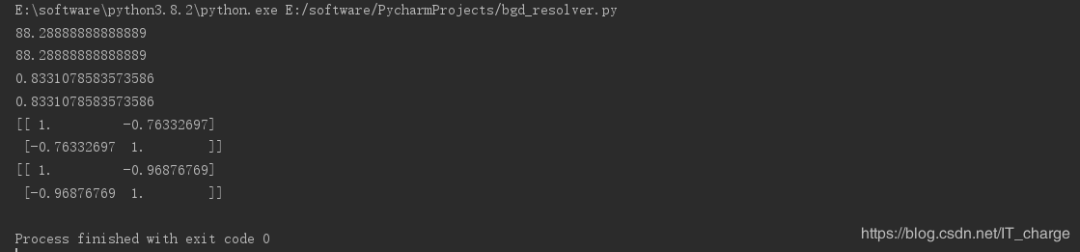
print(ssResTrain)
#?Python计算的训练数据集残差
print(model._residues)
#?手动计算测试数据集残差
ssResTest?=?sum((hpyTest?-?yTest)?**?2)
#?手动计算测试数据集y值偏差平方和
ssTotTest?=?sum((yTest?-?np.mean(yTest))?**?2)
#?手动计算R方
Rsquare?=?1?-?ssResTest?/?ssTotTest
print(Rsquare)
#?Python计算的训练数据集的R方
print(model.score(xTest,?yTest))
#?corrcoef函数是在各行元素之间计算相关性,所以x和y都应是行向量
print(np.corrcoef(xTrain.T,?yTrain.T))??#?计算训练数据的相关性
print(np.corrcoef(xTest.T,?yTest.T))????#?计算测试数据的相关性
def?initPlot():
????#?先准备好一块画布
????plt.figure()
????#?生成图表的名字
????plt.title('2020年5月上旬大同天气')
????#?横坐标名字
????plt.xlabel('日期')
????#?纵坐标名字
????plt.ylabel('当日最高气温')
????#?表内有栅格(不想要栅格把此行注释掉即可)
????plt.grid(True)
????return?plt
plt?=?initPlot()
plt.plot(xTrain,?yTrain,?'r.')??????????#?训练点数据(红色)
plt.plot(xTest,?yTest,?'b.')????????????#?测试点数据(蓝色)
plt.plot(xTrain,?hpyTrain,?'g-')????????#?假设函数直线(绿色)
plt.show()
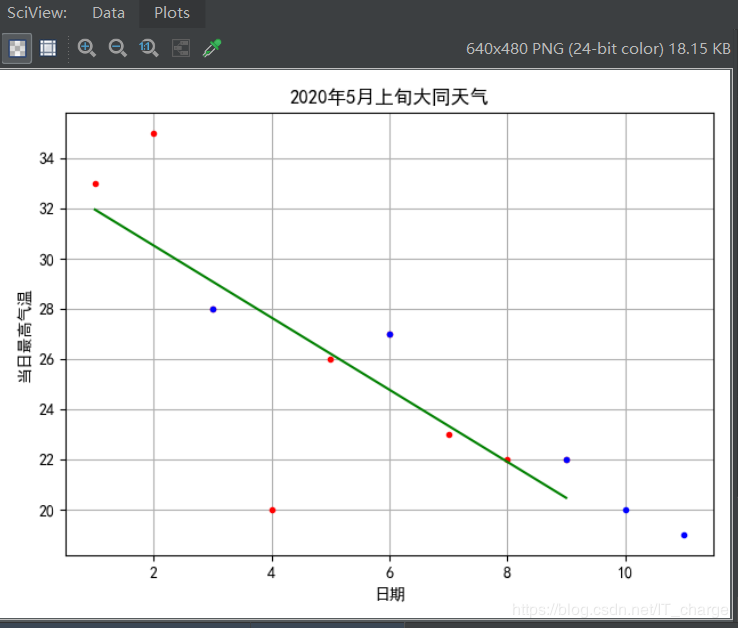
查看上述拟合效果:
2、多变量线性回归
在单变量线性回归中,最高气温仅与日期有关(尝试可知,这显然是极不合理的),按照这一假设,其预测的结果并不令人满意(R方=0.833)。因此在多变线性回归模型中再引入一个新的影响因素:最低气温(此处要注意和最高气温一样,计算前先利用 .map 方法将?℃?置空,仅将最低气温调整成数值,以便能够进行数值计算)。
模型二:基于LinearRegression实现的多变量线性回归模型
import?numpy?as?np
import?pandas?as?pd
import?matplotlib.pyplot?as?plt
from?sklearn.linear_model?import?LinearRegression
#?解决中文问题(若没有此步骤,表名字及横纵坐标中的汉语将无法显示[具体会显示矩形小方格])
plt.rcParams['font.sans-serif']?=?['SimHei']
#?将数据从上一步存入的?.csv?格式文件中读取
data?=?pd.read_csv(r'F:\DaTong5Mouth.csv')
#?由于最高气温与最低气温中有?/?分隔,故将其分开,即“气温”列由一列变为两列――“最高气温”和“最低气温”
data['最高气温']?=?data['气温'].str.split('/',expand=True)[0]
#?我们要对数值进行分析,所以将多余的单位?℃?从列表中去掉,只保留数值部分
data['最高气温']?=?data['最高气温'].map(lambda?x:x.replace('℃,',''))
data['最低气温']?=?data['气温'].str.split('/',expand=True)[1]
#?我们要对数值进行分析,所以将多余的单位?℃?从列表中去掉,只保留数值部分
data['最低气温']?=?data['最低气温'].map(lambda?x:x.replace('℃,',''))
#?日次操作同理,这里不再赘述
data['日期']?=?data['日期'].map(lambda?x:x.replace('2020年05月0',''))
data['日期']?=?data['日期'].map(lambda?x:x.replace('日',''))
#?不理解的小伙伴可运行下两行代码查看运行结果(这里先注释掉了)
#?print(data['日期'])
#?print(data['最高气温'])
#?print(data['最低气温'])
#?传入对应日期及其最高气温参数
#?#?#?应以矩阵形式表达(对于单变量,矩阵就是列向量形式)
#?xTrain?=?np.array(data['日期'])[:,?np.newaxis]
#?#?为方便理解,也转换成列向量
#?yTrain?=?np.array(data['最高气温'])
#?训练集
xTrain?=?np.array([1,?2,?3,?4,?5,?6,?7,?8,?9])??#?无需手动添加Intercept?Item项
yTrain?=?np.array([[33,?8],?[35,?9],?[28,?4],?[20,?4],?[26,?6],?[27,10],?[23,10],?[22,7],?[22,3]])
#?测试集
xTest?=?np.array([3,?6,?9,?10,?11])
yTest?=?np.array([[28,?4],?[27,?10],?[22,?3],?[20,?5],?[19,?7]])
#?创建模型对象
model?=?LinearRegression()
#?根据训练数据拟合出直线(以得到假设函数)
model.fit(yTrain,?xTrain)
#?针对测试数据进行预测
hpyTest?=?model.predict(yTest)
print("假设函数参数:",?model.intercept_,?model.coef_)
print("测试数据预测结果与实际结果差异:",?hpyTest?-?xTest)
print("测试数据R方:",?model.score(yTest,?xTest))

模型三:基于成本函数和梯度下降实现的多变量线性回归模型
经过模型三的拟合,我们发现R方仅为0.164,还不如模型二的预测结果呢。而根据理论知识我们知道,这个模型预测结果应该是线性回归模型中预测拟合效果较好的一种,低的这个R方值经过思考,可进一步说明最高气温的影响因素不仅仅取决于日期和最低气温,甚至我们可推断出可能与日期及最低气温值等影响因素无关。
通过运行结果发现“50000次循环后,计算仍未收敛”。这说明①在未对自变量归一化处理的情况下,运算出现异常,无法收敛;②设置了过大的学习速率,会导致计算不收敛。
import?numpy?as?np
import?pandas?as?pd
import?matplotlib.pyplot?as?plt
import?bgd_resolver
from?sklearn.linear_model?import?LinearRegression
#?解决中文问题(若没有此步骤,表名字及横纵坐标中的汉语将无法显示[具体会显示矩形小方格])
plt.rcParams['font.sans-serif']?=?['SimHei']
def?costFn(theta,?X,?y):??#?成本函数
????temp?=?X.dot(theta)?-?y
????return?(temp.T.dot(temp))?/?(2?*?len(X))
def?gradientFn(theta,?X,?y):??#?根据成本函数,分别对x0,x1...xn求导数(梯度)
????return?(X.T).dot(X.dot(theta)?-?y)?/?len(X)
#?将数据从上一步存入的?.csv?格式文件中读取
data?=?pd.read_csv(r'F:\DaTong5Mouth.csv')
#?由于最高气温与最低气温中有?/?分隔,故将其分开,即“气温”列由一列变为两列――“最高气温”和“最低气温”
data['最高气温']?=?data['气温'].str.split('/',expand=True)[0]
#?我们要对数值进行分析,所以将多余的单位?℃?从列表中去掉,只保留数值部分
data['最高气温']?=?data['最高气温'].map(lambda?x:x.replace('℃,',''))
data['最低气温']?=?data['气温'].str.split('/',expand=True)[1]
#?我们要对数值进行分析,所以将多余的单位?℃?从列表中去掉,只保留数值部分
data['最低气温']?=?data['最低气温'].map(lambda?x:x.replace('℃,',''))
#?日次操作同理,这里不再赘述
data['日期']?=?data['日期'].map(lambda?x:x.replace('2020年05月0',''))
data['日期']?=?data['日期'].map(lambda?x:x.replace('日',''))
#?不理解的小伙伴可运行下两行代码查看运行结果(这里先注释掉了)
#?print(data['日期'])
#?print(data['最高气温'])
#?print(data['最低气温'])
#?传入对应日期及其最高气温参数
#?#?#?应以矩阵形式表达(对于单变量,矩阵就是列向量形式)
#?xTrain?=?np.array(data['日期'])[:,?np.newaxis]
#?#?为方便理解,也转换成列向量
#?yTrain?=?np.array(data['最高气温'])
#?训练集
xTrain?=?np.array([1,?2,?3,?4,?5,?6,?7,?8,?9])??#?无需手动添加Intercept?Item项
yTrainData?=?np.array([[33,?8],?[35,?9],?[28,?4],?[20,?4],?[26,?6],?[27,10],?[23,10],?[22,7],?[22,3]])
yTrain?=?np.c_[yTrainData,?np.ones(len(yTrainData))]
np.random.seed(0)
init_theta?=?np.random.randn(yTrain.shape[1])
theta?=?bgd_resolver.batch_gradient_descent(costFn,?gradientFn,?init_theta,?yTrain,?xTrain)
print("theta值",?theta)
#?测试集
xTest?=?np.array([3,?6,?9,?10,?11])
yTestData?=?np.array([[28,?4],?[27,?10],?[22,?3],?[20,?5],?[19,?7]])
yTest?=?np.c_[yTestData,?np.ones(len(yTestData))]
print("测试数据预测值与真实值的差异:",?xTest.dot(theta)?-?xTest)
rsquare?=?bgd_resolver.batch_gradient_descent_rsquare(theta,?yTest,?xTest)
print("测试数据R方:",?rsquare)
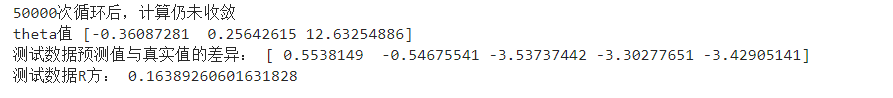
3、以"线性回归"的方式来拟合高阶曲线
这一部分我们分别使用一阶曲线(直线)、二阶曲线和三阶曲线进行拟合,并检查拟合效果。
在拟合数据点时,一般来说,对于一个自变量的,拟合出来是一条直线;对于两个自变量的,拟合出来时一个直平面。这种拟合结果是严格意义上的“线性”回归。但是有时候,采用“曲线”或“曲面”的方式来拟合,能够对训练数据产生更逼近的效果。这就是“高阶拟合”。
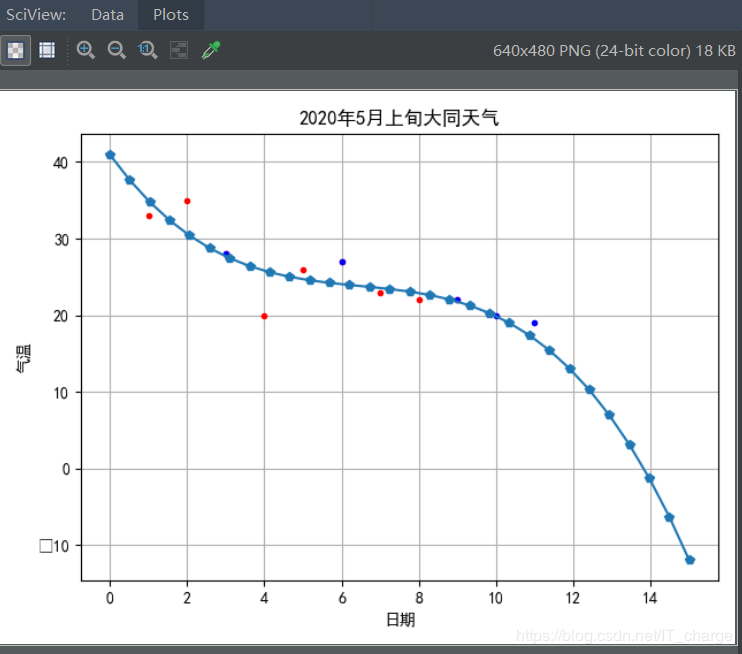
首先,我们查看要拟合的数据:
import?numpy?as?np
import?matplotlib.pyplot?as?plt
#?解决中文问题(若没有此步骤,表名字及横纵坐标中的汉语将无法显示[具体会显示矩形小方格])
plt.rcParams['font.sans-serif']?=?['SimHei']
xTrain?=?np.array([1,2,3,4,5,6,7,8,9])[:,?np.newaxis]??#?训练数据(日期)
yTrain?=?np.array([33,35,28,20,26,27,23,22,22])????????#?训练数据(最高气温)
xTest?=?np.array([3,6,9,10,11])[:,np.newaxis]??????????#?测试数据(日期)
yTest?=?np.array([28,27,22,20,19])????????????????????#?测试数据(最高气温)
plotData?=?np.array(np.linspace(0,?15,?30))[:,np.newaxis]??????????#?作图用的数据点
def?initPlot():
????plt.figure()
????plt.title('2020年5月上旬大同天气')
????plt.xlabel('日期')
????plt.ylabel('气温')
????plt.grid(True)
????return?plt
plt?=?initPlot()
plt.plot(xTrain,?yTrain,?'r.')??????????#?训练点数据(红色)
plt.plot(xTest,?yTest,?'b.')????????????#?测试点数据(蓝色)
plt.show()
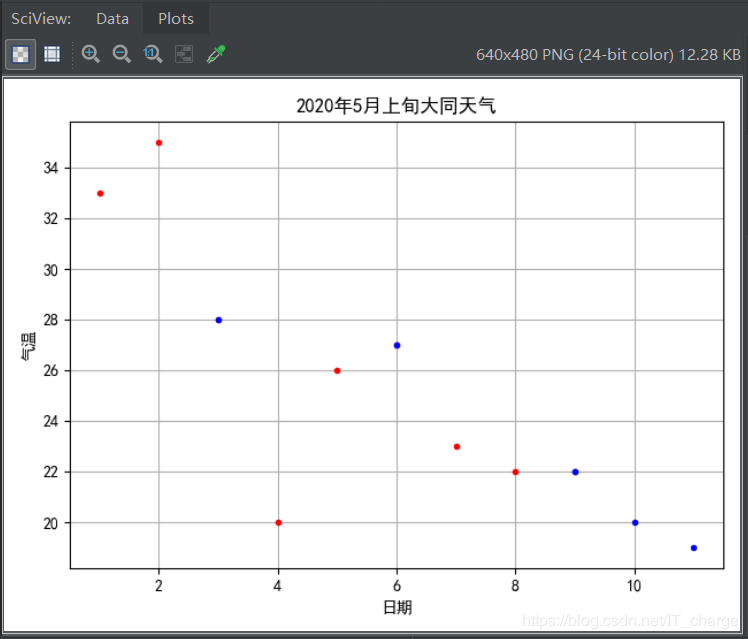
模型四:一阶线性拟合
from?sklearn.linear_model?import?LinearRegression
#?线性拟合
linearModel?=?LinearRegression()
linearModel.fit(xTrain,?yTrain)
linearModelTrainResult?=?linearModel.predict(plotData)
#?计算R方
linearModelRSquare?=?linearModel.score(xTest,?yTest)
print("线性拟合R方:",?linearModelRSquare)
plt?=?initPlot()
plt.plot(xTrain,?yTrain,?'r.')??????????#?训练点数据(红色)
plt.plot(xTest,?yTest,?'b.')????????????#?测试点数据(蓝色)
plt.plot(plotData,?linearModelTrainResult,?'y-')???????????#?线性拟合线
plt.show()
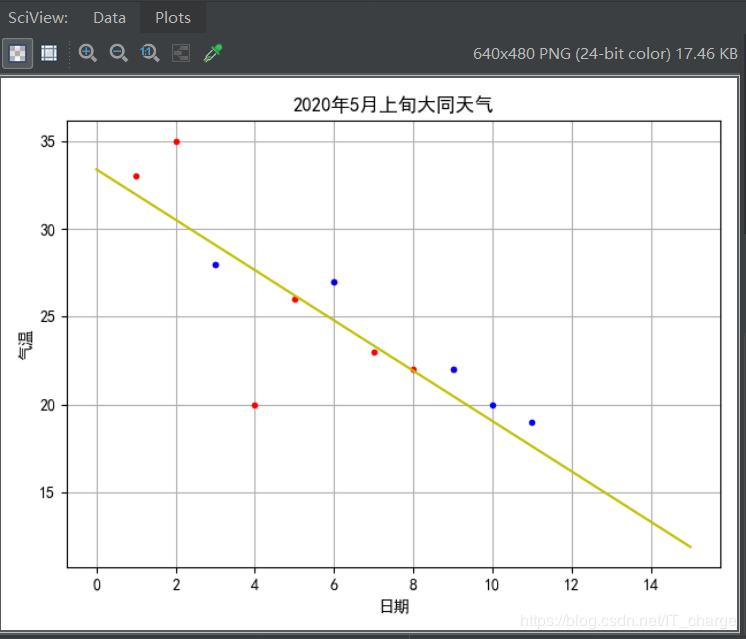

模型五:二阶曲线拟合
from?sklearn.preprocessing?import?PolynomialFeatures
from?sklearn.linear_model?import?LinearRegression
#?二阶曲线拟合??theta0?+?theta1*x?+?theta2*x*x???x*x?=>?z?????theta0+theta1*x+theta2*z
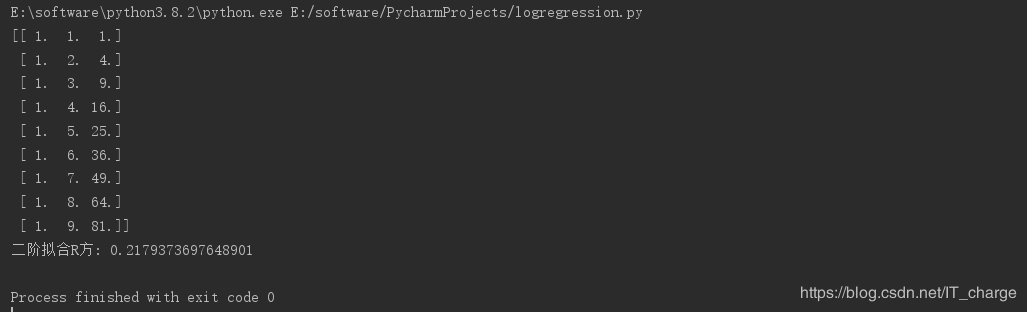
quadratic_featurizer?=?PolynomialFeatures(degree=2)
xTrain_quadratic?=?quadratic_featurizer.fit_transform(xTrain)
print(xTrain_quadratic)????#?查看扩展后的特征矩阵
quadraticModel?=?LinearRegression()
quadraticModel.fit(xTrain_quadratic,?yTrain)
#?计算R方(针对测试数据)
xTest_quadratic?=?quadratic_featurizer.fit_transform(xTest)
quadraticModelRSquare?=?quadraticModel.score(xTest_quadratic,?yTest)
print("二阶拟合R方:",?quadraticModelRSquare)
#?绘图点也同样需要进行高阶扩充以便使用曲线进行拟合
plotData_quadratic?=?quadratic_featurizer.fit_transform(plotData)
quadraticModelTrainResult?=?quadraticModel.predict(plotData_quadratic)
plt?=?initPlot()
plt.plot(xTrain,?yTrain,?'r.')??????????#?训练点数据(红色)
plt.plot(xTest,?yTest,?'b.')????????????#?测试点数据(蓝色)
plt.plot(plotData,?quadraticModelTrainResult,?'g-')????????#?二阶拟合线
plt.show()
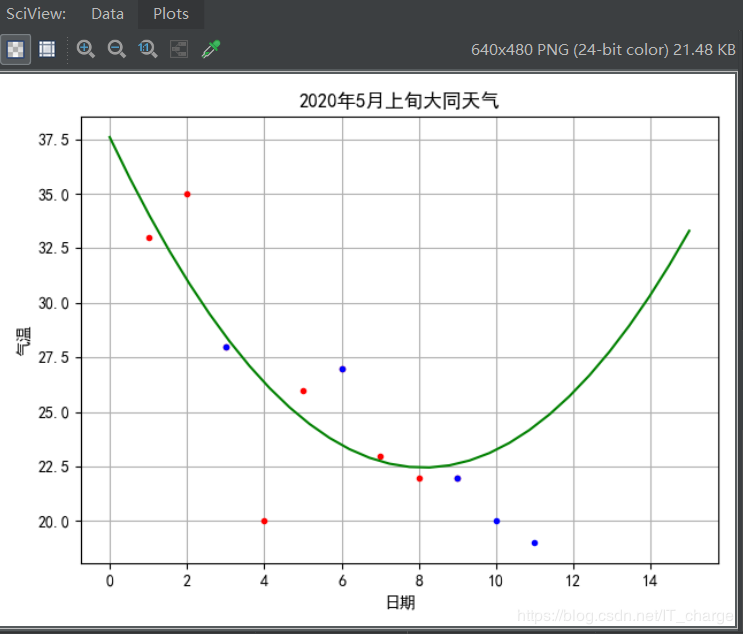
模型六:三阶曲线拟合
from?sklearn.preprocessing?import?PolynomialFeatures
from?sklearn.linear_model?import?LinearRegression
#?三阶曲线拟合
cubic_featurizer?=?PolynomialFeatures(degree=3)
xTrain_cubic?=?cubic_featurizer.fit_transform(xTrain)
cubicModel?=?LinearRegression()
cubicModel.fit(xTrain_cubic,?yTrain)
plotData_cubic?=?cubic_featurizer.fit_transform(plotData)
cubicModelTrainResult?=?cubicModel.predict(plotData_cubic)
#?计算R方(针对测试数据)
xTest_cubic?=?cubic_featurizer.fit_transform(xTest)
cubicModelRSquare?=??cubicModel.score(xTest_cubic,?yTest)
print("三阶拟合R方:",?cubicModelRSquare)
plt?=?initPlot()
plt.plot(xTrain,?yTrain,?'r.')??????????#?训练点数据(红色)
plt.plot(xTest,?yTest,?'b.')????????????#?测试点数据(蓝色)
plt.plot(plotData,?cubicModelTrainResult,?'p-')????????????#?三阶拟合线
plt.show()

综上对比我们发现,一阶拟合R方约为0.833,二阶拟合R方约为0.218,三阶拟合R方约为0.800。很显然,得到的拟合R方值并不是随着阶数的增高而增大,同前理,说明日期和最低气温并不是最高气温的影响因素。这正与我们常识所知的结论相吻合。因此,想要预测天气值就错综而复杂,不得片面考虑一个或为数不多的几个因素,且不应考虑到与气温影响因素无关的影响变量:比如说像上例中所提及的日期、最低气温等。
4、线性回归预测天气
模型七:线性回归预测模型
使用sklearn.linear_model.LinearRegression处理。
无需对自变量进行归一化处理,也能得到一致的结果。针对训练数据的R方约为0.583。
(1)装载并查看数据信息
import?numpy?as?np
xTrain?=?np.array([1,2,3,4,5,6,7,8,9])[:,?np.newaxis]??#?训练数据(日期)
yTrain?=?np.array([33,35,28,20,26,27,23,22,22])????????#?训练数据(最高气温)
#?查看天气统计数据
print("天气数据统计:")
print("最低:%.2f, 最高:%.2f, 平均:%.2f, 中位数:%.2f, 标准差:%.2f"?%
?????(np.min(yTrain),?np.max(yTrain),?np.mean(yTrain),?np.median(yTrain)?,np.std(yTrain)))

(2)使用LinearRegression,没有进行归一化预处理
'''?使用LinearRegression,没有进行归一化预处理?'''
import?numpy?as?np
from?sklearn.linear_model?import?LinearRegression
train_data?=?np.array([1,2,3,4,5,6,7,8,9])[:,?np.newaxis]??#?训练数据(日期)
train_temp?=?np.array([33,35,28,20,26,27,23,22,22])[:,?np.newaxis]??????#?训练数据(最高气温)
xTrain?=?np.array(train_data[:,?0:2])
yTrain?=?np.array(train_temp[:,?-1])
xTrain?=?np.c_[xTrain,?np.ones(len(xTrain))]
model?=?LinearRegression()
model.fit(xTrain,?yTrain)

(3)使用LinearRegression,进行归一化预处理?