?
��ע���ű�֮�ҡ�,���������һ��
���� | ����
��Դ | Java������Ⱥ(ID:javacn666)
�������
���dz����� ���õ��������ݽṹ,Ҳ�������г�����������֮һ��Ȼ�����ںܶ�����˵,ֻ��ģ���ļǵö��ߵ�����,���ܻ��ǵò�һ����,����ÿ�ε������Ե�ʱ��,���ð���Щ�ĸ����ó�����һ�����,δ����Щ�鷳������������ִ�й���ͼ�Լ���������ȷ�������,����������������ͼ�����ߵ�����,������������ѧϰ֮��,���Ż����������̡�
�� ��
�ڿ�ʼ(��������)֮ǰ���������ع�һ��,ʲô������?
����Ķ�������:
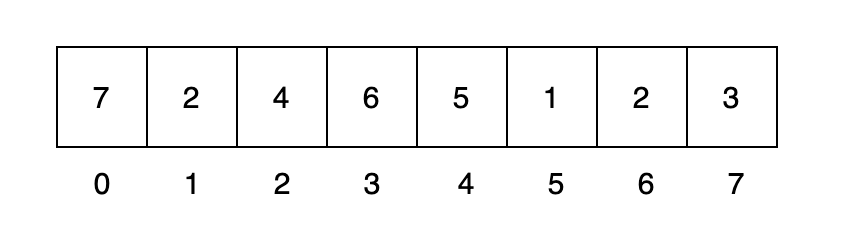
����(Array)������ͬ���͵�Ԫ��(element)�ļ�������ɵ����ݽṹ,����һ���������ڴ����洢������Ԫ�ص�����(index)���Լ������Ԫ�ض�Ӧ�Ĵ洢��ַ��
������ݽṹ������һά���顣����,����Ϊ 0 �� 9 �� 32 λ��������,����Ϊ�ڴ洢����ַ 2000,2004,2008,...2036 ��,�洢 10�� ����,�������Ϊ i ��Ԫ�ؼ��ڴ洢���е� 2000+4��i ��ַ�������һ��Ԫ�صĴ洢����ַ��Ϊ��һ��ַ�������ַ��
����˵,���������һ������ ���ڴ���ɵ����ݽṹ�������������һ���ؼ��ʡ����� ��,����ӳ�������һ���ص�,��������������һ���������ڴ���ɵġ�
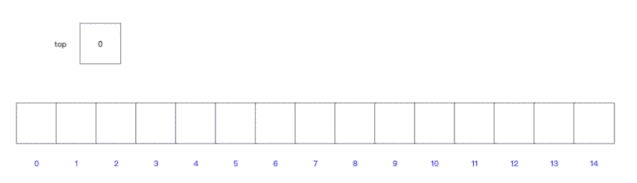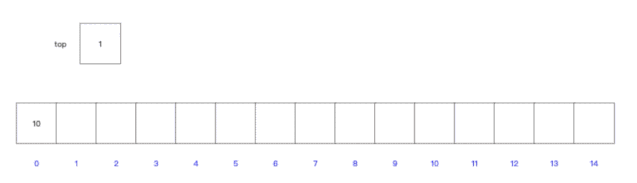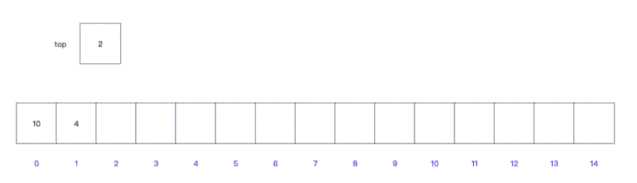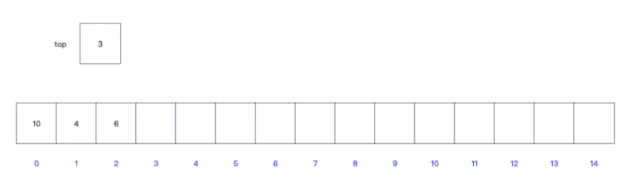
��������ݽṹ,����ͼ��ʾ:
�������ӵĹ���,����ͼ��ʾ:
������ŵ�
����ġ����� ���������������ķ����ٶȺܿ�,��Ϊ���������洢��,������;��������Ĵ洢λ�þ��ǹ̶���,������ķ����ٶȾͺܿ졣���������� 10 �������ǰ�������˳����ס��,������֪����һ����ס���� 20 �����֮��,��ô���Ǿ�֪���˵ڶ��������� 21 �����,����������� 24 �����......�ȵȡ�
�����ȱ��
���⸣����,���������������������Լ����ŵ�����ȱ��,�ŵ������Ѿ�˵��,��ȱ�������ڴ��Ҫ��Ƚϸ�,����Ҫ�ҵ�һ���������ڴ���С�
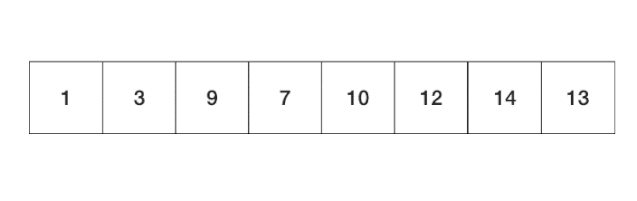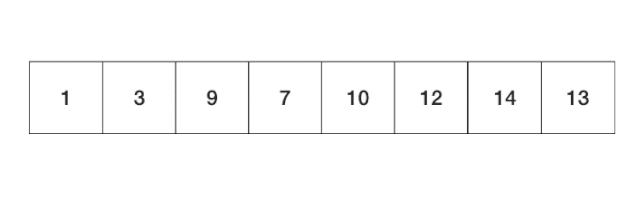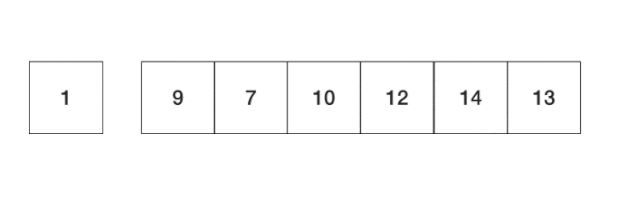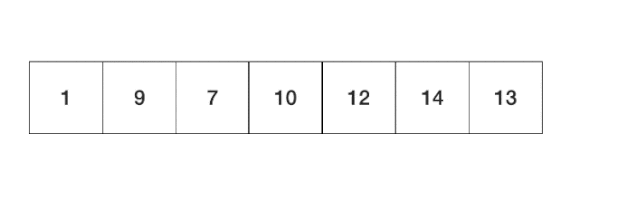
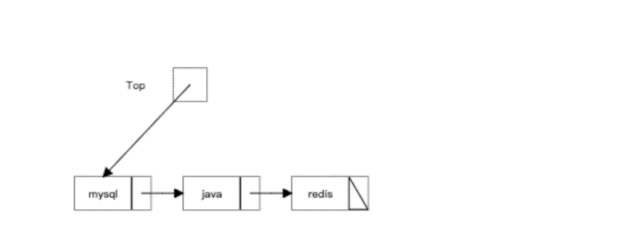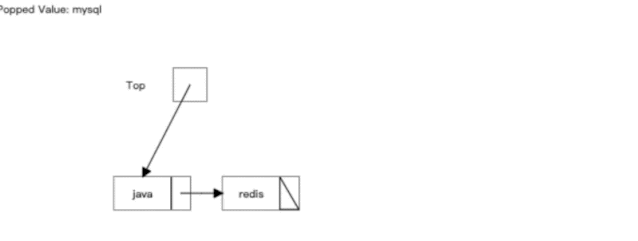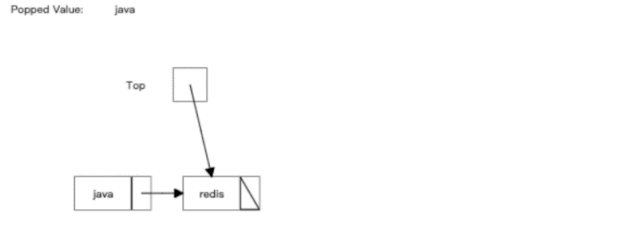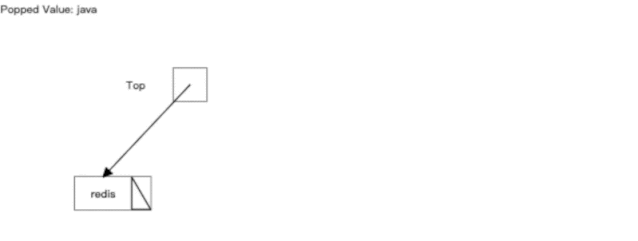
�������һ��ȱ����Dz����ɾ����Ч�ʱȽ���,��������������ķ�β�������ɾ��һ������,��ô��Ҫ�ƶ�֮�����������,��ͻ����һ�������ܿ���,ɾ���Ĺ�������ͼ��ʾ:
���黹��һ��ȱ��,���Ĵ�С�̶�,���ܶ�̬��չ��
�� ��
�����Ǻ����黥����һ�����ݽṹ,���Ķ�������:
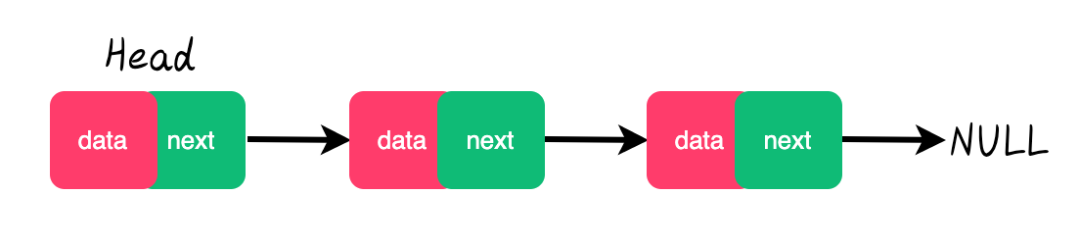
����(Linked list)��һ�ֳ����Ļ������ݽṹ,��һ�����Ա�,���Dz����ᰴ���Ե�˳��洢����,������ÿһ���ڵ���浽��һ���ڵ��ָ��(Pointer)�����ڲ����밴˳��洢,�����ڲ����ʱ����Դﵽ O(1) �ĸ��Ӷ�,����һ�����Ա�˳�����ö�,���Dz���һ���ڵ���߷����ض���ŵĽڵ�����Ҫ O(n) ��ʱ��,��˳�����Ӧ��ʱ�临�Ӷȷֱ��� O(logn) �� O(1)��
Ҳ��˵������һ�����������ڴ�洢�����ݽṹ,������Ԫ������������,һ����Ԫ�ص�ֵ,��һ����ָ��,��ָ��������һ��Ԫ�صĵ�ַ��
���������ݽṹ,����ͼ��ʾ:
�������ӵĹ���,����ͼ��ʾ:
����ɾ���Ĺ���,����ͼ��ʾ:
��������
������Ҫ��Ϊ���¼���:
��������
���������а���������,һ����Ϣ���һ��ָ�����������ָ���б��е���һ���ڵ�,�����һ���ڵ���ָ��һ����ֵ,����������չʾ���������ǵ���������
˫������
˫������Ҳ��˫����,˫�������в�����ָ���һ���ڵ��ָ��,����ָ��ǰһ���ڵ��ָ��,�������Դ��κ�һ���ڵ����ǰһ���ڵ�,��ȻҲ���Է��ʺ�һ���ڵ�,��������������
˫�������Ľṹ����ͼ��ʾ:
ѭ������
ѭ�������е�һ���ڵ�֮ǰ�������һ���ڵ�,��֮��Ȼ��ѭ���������ޱ߽�ʹ��������������������㷨�����ͨ�����������ס�
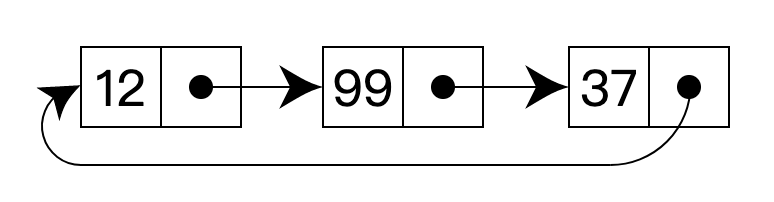
ѭ�������Ľṹ����ͼ��ʾ:
Ϊʲô���е���˫����֮��?
���˿��ܻ���,��Ȼ�Ѿ��е���������,��Ϊʲô��Ҫ˫��������?˫��������ʲô������?
�����Ҫ��������ɾ��˵����,�����������Ҫɾ��Ԫ�صĻ�,����Ҫ�ҵ�ɾ���Ľڵ�,��Ҫ�ҵ�ɾ���ڵ����һ���ڵ�(ͨ����֮Ϊǰ��),��Ϊ��Ҫ�����һ���ڵ��� next ��ָ��,������Ϊ���ǵ�������,������ɾ���Ľڵ��в�û�д洢��һ���ڵ�������Ϣ,��ô���Ǿ���Ҫ�ٲ�ѯһ���������ҵ���һ���ڵ�,�����ʹ�����һ������������,���Ծ�����˫��������
�����ŵ�
�������ŵ���¿ɷ�Ϊ��������:
�������ڴ�������ʱȽϸ�,�����������ڴ�ռ�,��ʹ���ڴ���Ƭ,Ҳ��Ӱ�������Ĵ���; �����IJ����ɾ�����ٶȺܿ�,����������һ����Ҫ�ƶ�������Ԫ��; ������С���̶�,���Ժܷ���Ľ��ж�̬��չ�� ����ȱ��
��������Ҫȱ���Dz����������,����ӵ�һ����ʼ����,����Ч�ʱȽϵ�,������ѯ��ʱ�临�Ӷ��� O(n)��
��������
�˽�������������Ļ���֪ʶ֮��,������������ʽ������������ڡ�
����ʽ��ʼ֮ǰ,����������ȷһ�²���Ŀ��,������Ҫ���Եĵ���ʵֻ�� 6 ��:
��ͷ��/�м䲿��/β�� �������Ӳ��������ܲ���; ��ͷ��/�м䲿��/β�� ��ʼ��ѯ�����ܲ��ԡ� ��Ϊ���Ӳ�����ɾ��������ִ��ʱ����������һ�µ�,��������������Ҫ�ƶ������Ԫ��,ɾ��Ҳͬ�����ƶ������Ԫ��;������Ҳ�����,���Ӻ�ɾ�����Ǹı������������ڵ����Ϣ,������ǾͰ����Ӻ�ɾ���IJ��Ժ϶�Ϊһ,�����Ӳ��������в��ԡ�
����˵�� :
�� Java ������,����Ĵ���Ϊ?ArrayList,�������Ĵ���Ϊ?LinkedList,������Ǿ������������������в���; �������ǽ�ʹ�� Oracle �ٷ��Ƽ� JMH ��������в���; ���IJ��Ի����� JDK 1.8��MacMini��Idea 2020.1�� 1.ͷ���������ܲ���
import?org.openjdk.jmh.annotations.*;�����ϴ�����Կ���,�ڲ���֮ǰ,�����Ƚ�?ArrayList?��?LinkedList?�������ݳ�ʼ��,�ٴ�ͷ����ʼ���� 100 ��Ԫ��,ִ�н������:
�����Ͻ�����Կ���,LinkedList?��ƽ��ִ��(���)ʱ���?ArrayList?ƽ��ִ��ʱ�����Լ 216 ����
2.�м��������ܲ���
import?org.openjdk.jmh.annotations.*;�����ϴ�����Կ���,�ڲ���֮ǰ,�����Ƚ�?ArrayList?��?LinkedList?�������ݳ�ʼ��,�ٴ��м俪ʼ���� 100 ��Ԫ��,ִ�н������:
������������Կ���,
LinkedList
?��ƽ��ִ��ʱ���?
ArrayList
?ƽ��ִ��ʱ�����Լ 54 ����
3.β���������ܲ���
import?org.openjdk.jmh.annotations.*;���ϳ����ִ�н��Ϊ:
������������Կ���,LinkedList?��ƽ��ִ��ʱ���?ArrayList?ƽ��ִ��ʱ�����Լ 32 ����
4.ͷ����ѯ��������
import?org.openjdk.jmh.annotations.*;���ϳ����ִ�н��Ϊ:
������������Կ���,��ͷ����ѯ 100 ��Ԫ��ʱ?ArrayList?��ƽ��ִ��ʱ���?LinkedList?ƽ��ִ��ʱ�����Լ 1990 ����
5.�м��ѯ��������
import?org.openjdk.jmh.annotations.*;���ϳ����ִ�н��Ϊ:
������������Կ���,���м��ѯ 100 ��Ԫ��ʱ?ArrayList?��ƽ��ִ��ʱ���?LinkedList?ƽ��ִ��ʱ�����Լ 28089 ��,���ǿֲ���
6.β����ѯ��������
import?org.openjdk.jmh.annotations.*;���ϳ����ִ�н��Ϊ:
������������Կ���,��β����ѯ 100 ��Ԫ��ʱ?ArrayList?��ƽ��ִ��ʱ���?LinkedList?ƽ��ִ�г�ʱ�����Լ 1839 ����
7.��չ���Ӳ���
������������������һ��,������������Ǵ�ͷ��ʼ������������������ܶԱ�,���Դ�������:
import?org.openjdk.jmh.annotations.*;���ϳ����ִ�н��Ϊ:
������,���ǽ����ӵĴ������� 1w,���Խ������:
���,�����ٽ����Ӵ������� 10w,���Խ������:
�����Ͻ�����Կ��������������,��ͷ�����ο�ʼ����Ԫ��ʱ,�������ܲ��
�� ��
�������ǽ���������ĸ����Լ�������ȱ��,ͬʱ�������˵���������˫��������ѭ�������ĸ����Լ���������ȱ�㡣���������������п��Կ���,������������ͷ����������Ԫ��ʱ,��������������ܲ���������ݳ�ʼ�����֮��,�����ٽ��в������ʱ,�����Ǵ�ͷ������ʱ,��Ϊ����Ҫ�ƶ�֮�������Ԫ��,�������Ҫ�������ͺܶ�;���ڲ�ѯʱ���ܸպ��෴,��Ϊ����Ҫ������ѯ,����?LinkedList?��˫������,�������м��ѯʱ����Ҫ�������ѯ��������(��ѯ 100 ��Ԫ��),����ͷ��ѯ(�ײ���β��)ʱ,����Ҳ���������˽��� 1000 �(��ѯ 100 ��Ԫ��),����ڲ�ѯ�Ƚ϶�ij�����,����Ҫ����ʹ������,�������Ӻ�ɾ�������Ƚ϶�ʱ,����Ӧ��ʹ�������ṹ ��
����������IJ���ʱ�临�Ӷ�,���±���ʾ:
���� ���� ��ѯ O(1) O(n) ���� O(n) O(1) ɾ�� O(n) O(1)
end
�Ƽ��Ķ�:
�������������������Ԫ��ʱ��ı��������?�һ���20��ͼ,������Ů����ѧ���˷�ת����������ϸ��һ��ѧ����������
👇🏻👇🏻👇🏻
cs
 ?
��ע���ű�֮�ҡ�,���������һ��
?
��ע���ű�֮�ҡ�,���������һ��