�ļ�����
Ŀ¼
??????һ������Ϊʲô��Ҫ�ļ�?
��������ʲô�����ļ�
�����ļ�
�����ļ�
�����ļ���
�ġ��ļ�����
�塢�ļ�������
�����ļ�ָ��
�ߡ����ļ��ر��ļ�
fopen
fclose
�ˡ��ļ�˳���д��
��(stream)
fputc
fgetc
? ? ? ? ?fgets
fputs
fprintf
fscanf
�Ա�һ�麯��
fwrite
fread
�š��ļ������д
fseek
ftell
rewind
ʮ���ļ���ȡ�������ж�
һ������Ϊʲô��Ҫ�ļ�?
????????��������֮ǰ����д�ij�����ִ�й����������������ݼ������ֻ����ʱ������ڴ�����,һ���������н�����,�ó��������ٵ��ڴ�ռ佫ȫ�����ظ�����ϵͳ����ô��ʱ��������Ҫȥ�鿴֮ǰ�����ݺ�ִ�н��,��ʾ�Dz����ܵġ�
�Ǹ���ν�����������??
������Ҫ�õ��ľ��ǡ����ļ��� û��,�ļ� �����þ��ǿ��Խ��������й����������������ݽ�����洢����,��������������,������Ȼ����ͨ�� �ļ� ���ҵ���Щ����,�����ٴ����г���ʱ��Ȼ��ʹ����Щ���ݡ�
��������ʲô�����ļ�
ȷ����˵:������ļ����Ǵ洢�ڼ����Ӳ�̡������ϵ���Ϣ���ϡ�������Ϥ��ͼƬ�ļ�����Ƶ�ļ�������ȵȡ�
�ļ��и��ָ���������,�����ڳ��������,����һ��̸���ļ�������:�����ļ��������ļ�
�����ļ�
����Դ�����ļ�(��Ϊ.c ), Ŀ���ļ�(windows������Ϊ.obj), ��ִ�г���(windows������Ϊ.exe)��
�����ļ�
�ļ������ݲ��dz���,���dz�������ʱ��д������,�������������Ҫ���ж�ȡ���ݵ��ļ�,����������ݵ��ļ���
������DZ�Χ�������ļ���������˵����
�����ļ���
һ���ļ�Ҫ��һ��Ψһ���ļ���ʶ,�Ա��û�ʶ������á�
�ļ�������3���֡��ļ�·�� + �ļ������� + �ļ���
����U c : \code\text.txt
�ļ�·��: c : \code
�ļ�������: test
�ļ���: .txt
��ȻΪ�˷������,�ļ���ʶ������Ϊ �ļ������ļ������� ������������ѭ��ʶ������������
��������Ҫ�˽��ʱ���ƺ����ļ���,ʵ���ϰ�������3��������,�����������ļ������ɡ�
�����������һЩ�������ļ���������ȥ�˽��ļ�������:
txt(�ı��ļ�)dat(�����ļ�)doc(Word���ɵ��ļ�)xlsx(excel���ɵ��ļ�)exe(��ִ���ļ�)jpg(ͼƬ�ļ�)�ȡ���
�ġ��ļ�����
��ô��������������ļ�������?
���ȸ������ݵ���֯��ʽ,�����ļ�����Ϊ�� �ı��ļ� �� �������ļ���
���������ڴ����Զ����Ƶ���ʽ�洢ʱ,�������ת��������������ȥ,��ô���� �������ļ���
��֮,������������ASCII�����ʽ���д洢,����ڴ洢�����ǰ��ת��,��ô���� �ı��ļ���
һ������������ڴ��д洢��?
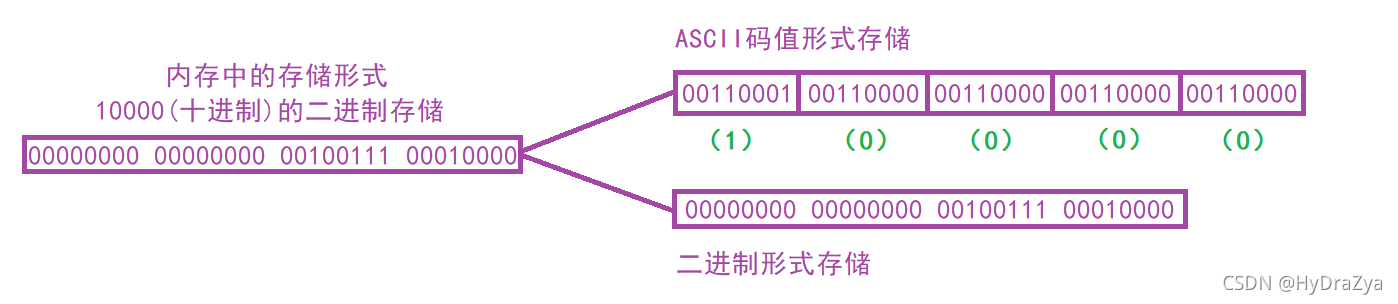
�ַ����ڴ���һ������ASCII��ֵ��ʽ���д洢��,����ֵ�����ݼȿ�����ASCII��ֵ��ʽ�洢,Ҳ����ʹ�ö�������ʽ���д洢��
?��:
#include <stdio.h>
int main()
{
int a = 10000;
FILE *pf = fopen("eg.txt", "wb");
//fopen ����Ϊtest.txt���ļ�
//wb �Զ����Ƶ���ʽд���ļ�
fwrite(&a, 4, 1, pf);//дһ���ĸ��ֽڵ����ݷŵ���pfά�����ļ���ȥ
fclose(pf);
pf = NULL;
return 0;
}
�����Զ����Ʊ༭���������������� eg.txt �ļ���ȥ:
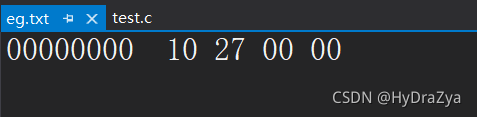
���ǿ��Կ���������16������ʽ��ʾ��,�������ڱ������ǰ���С�˽��д洢�ġ�
����Ӧ��Ϊ 00 00 27 10
ת���ɶ����ƾ��� 00000000 00000000 00100111 00010000
ͼ��:
�塢�ļ�������
�������˽�һ��ʲô���ļ�������:
����ANSIC �������������ļ�ϵͳ�������������ļ���,��ν�����ļ�ϵͳ��ָϵͳ�Զ������ڴ���������ÿһ������ʹ�õ��ļ�����һ�����ļ��������������ڴ������������ݻ����͵��ڴ��еĻ�����,װ�����������һ���͵������ϡ����������������������,��Ӵ����ļ��ж�ȡ�������뵽�ڴ滺����(����������),Ȼ���ٴӻ���������ؽ������͵�����������(���������)�����������Ĵ�С����C����ϵͳ�����ġ�
ͼ��:
�����ļ�ָ��
�����ļ�ϵͳ��, �ؼ��ĸ�����?���ļ�����ָ�롱?, ���?���ļ�ָ�롱?��ÿ����ʹ�õ��ļ������ڴ��п���һ����Ӧ���ļ���Ϣ��,��������ļ����й���Ϣ(���ļ������֡��ļ�״̬���ļ���ǰλ�õ�)����Щ��Ϣ�DZ�����һ���ṹ������еġ�
�ýṹ����������ϵͳ������,ȡ��Ϊ FILE ��
��:
//vs2013���뻷���ṩ��stdio.hͷ�ļ����ļ���������
struct _iobuf
{
char* _ptr;
int _cnt;
char* _base;
int _f1ag;
int _file;
int _charbuf;
int _bufsiz;
char* _tmpfname;
};
typedef struct _iobuf FILE;
- ��Ȼ��ͬ��C�༭��������Ӧ��FILE���Ͱ���������Ҳ����ȫ��ͬ,���Ӹ����ϴ�ͬС�졣
- ÿ����һ���ļ�ʱ,ϵͳ������ļ�������Զ�����һ��FILE�ṹ�ı���,��������е���Ϣ,ʹ��ʱ���Dz���������Щϸ�ڡ�
- һ�������ͨ��FILEָ����ά�����FILE�ṹ�ı���,����ʹ����������ӱ�ݡ�
��:(����FILE*��ָ�����)
FILE *pf;//�ļ�ָ�����
���� pf ��һ��ָ�� FILE �������ݵ�ָ�����������ʹ pf ָ��ij���ļ����ļ���Ϣ��(��һ���ṹ�����)��ͨ�����ļ���Ϣ���е���Ϣ���ܹ����ʸ��ļ���Ҳ����˵,ͨ���ļ�ָ������ܹ��ҵ������������ļ�
ͼ��:
�ߡ����ļ��ر��ļ�
���Ƕ�֪��,�ļ��ڶ�д֮ǰӦ���������ļ�,��ʹ�ý�����Ӧ���ر��ļ���
�ڱ�д�����ʱ��,�ڴ��ļ���ͬʱ,���᷵��һ�� FILE* ��ָ�����ָ����ļ�,Ҳ�൱�ڽ�����ָ����ļ��Ĺ�ϵ��
ANSIC�涨ʹ�� fopen ���������ļ�,fclose ���ر��ļ���
fopen
//����ԭ��
FILE* fopen(const char* filename, const char* mode);
��������: Open a file.(���ļ�)
��������: Each of these functions returns a pointer to the open file. A null pointer value indicates an error.(����ɹ�,����ָ���ļ���Ϣ����ָ��,�������ʧ��,���ؿ�ָ��NULL)
��������1:filename(�ļ���,ʵ���ϰ���3��������,�����������ļ������ɡ�����ļ�·��δд,��Ĭ�ϱ�·��)
��������2:Type of access permitted(�ļ���ʽ)
�ļ���ʽ��:
| �ļ�ʹ�÷�ʽ | ���� | ���ָ���ļ������� |
| "r"(ֻ��) | Ϊ����������,��һ���Ѿ����ڵ��ı��ļ� | ���� |
| "w"(ֻд) | Ϊ���������,��һ���ı��ļ� | ����һ�����ļ� |
| "a"(��) | ���ı��ļ�β�������� | ���� |
| "rb"(ֻ��) | Ϊ����������,��һ���������ļ� | ���� |
| "wb"(ֻд) | Ϊ���������,��һ���Ľ����ļ� | ����һ�����ļ� |
| "ab"(��) | ��һ���������ļ�β�������� | ���� |
| "r+"(��д) | Ϊ�˶���д,��һ���ı��ļ� | ���� |
| "w+"(��д) | ���˶���д,����һ���µ��ļ� | ����һ�����ļ� |
| "a+"(��д) | ��һ���ļ�,���ļ�β���ж�д | ����һ�����ļ� |
| "rb+"(��д) | Ϊ�˶���д��һ���������ļ� | ���� |
| "wb+"(��д) | Ϊ�˶���д,�½�һ���µĶ������ļ� | ����һ�����ļ� |
| "ab+"(��д) | ��һ���������ļ�,���ļ�β���ж���д | ����һ�����ļ� |
| ע: ��w�� ��ʱ�������ͬ���ļ�,���ļ��е����ݻᱻ���� |
fclose
//����ԭ��
int fclose(FILE* stream);
��������:Closes a stream(fclose) or closes all open streams(_fcloseall).(�ر��ļ�)
��������:fclose returns 0 if the stream is successfully closed._fcloseall returns the total number of streams closed.Both functions return EOF to indicate an error(�ر��ļ��ɹ�����0,�ر��ļ�ʧ�ܷ���EOF(ֵΪ - 1)������)
��������:Pointer to FILE structure(�ļ�ָ��)
?��:
#include <stdio.h>
int main()
{
//���ļ�mysize.txt
//���·��
//..��ʾ��һ��·��
//fopen("../../mysize.txt", "r");
//.��ʾ��ǰ·��
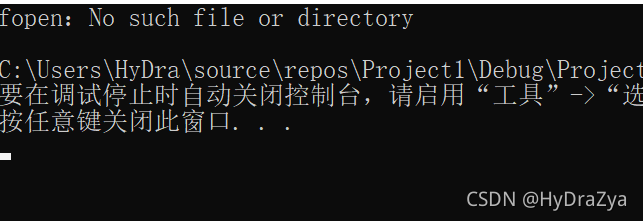
FILE* pf = fopen("mysize.txt", "r");//���·��
if (pf == NULL)
{
perror("fopen");
return 1;
}
//�ɹ�
//���ļ�
fclose(pf);//�ر��ļ�
return 0;
}
?���������½�һ���ļ�:

ִ�н��:?
?
?���Ǵ�ʱ�ٻ��ɾ���·��:
?�ո���������?��r��(ֻ��)�ķ�ʽ�����ļ�,����������������?��w��(ֻд)�ķ�ʽ�����ļ�
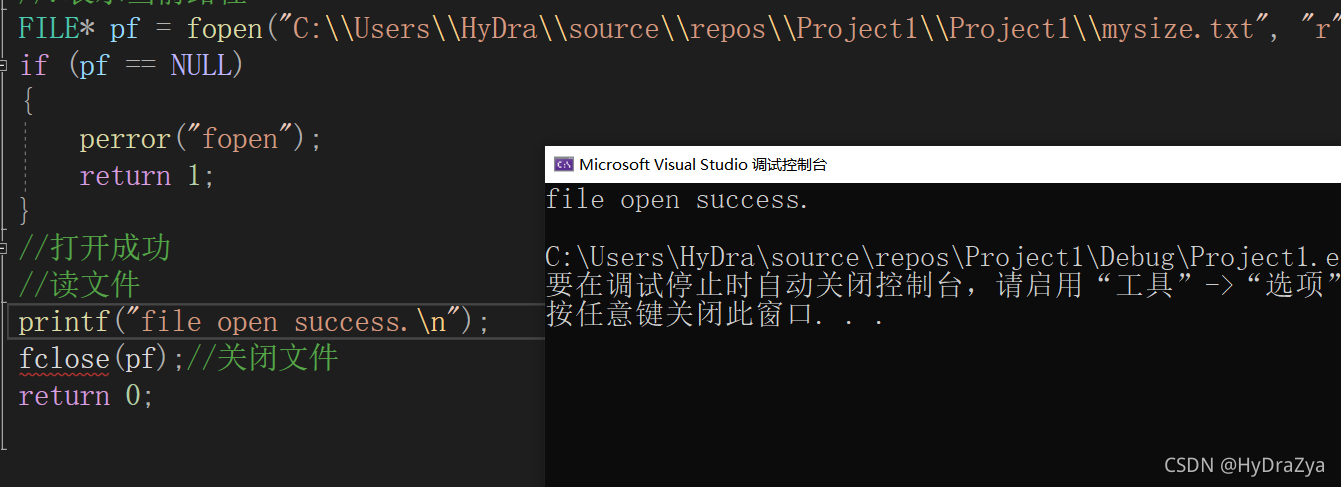
#include <stdio.h>
int main()
{
FILE* pf = fopen("eg.dat", "w");//���·��
if (pf == NULL)
{
perror("fopen");
return 1;
}
//�ɹ�
//���ļ�
printf("file open success.\n");
fclose(pf);//�ر��ļ�
return 0;
}
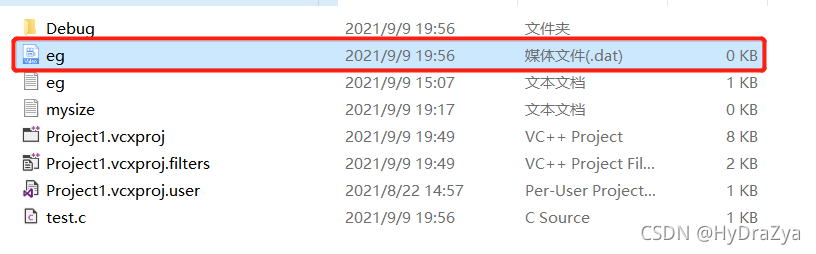
�۲��ļ���,�����½��� eg.dat ��ôһ���ļ� :
�ˡ��ļ�˳���д��
| ���� | ������ | ����(����ֵ) |
| �ַ����뺯�� | fgetc(fp) | ���ļ�ָ�� fp ��ָ����ļ��ĵ�ǰ��ָ��λ�ö�ȡһ���ַ�,��ȡ��ɺ�ָ���Զ�����ָ����һ���ַ� �ɹ�ʱ���ظ��ַ�,��������EOF |
| �ַ�������� | fputc(ch,fp) | ���ַ� ch?д�뵽�ļ�ָ�� fp?��ָ����ļ��ĵ�ǰдָ��λ�� �ɹ��������ַ�����,��������EOF |
| �ı������뺯�� | fgets(str, n, fp) | �� fp ��ָ����ļ��ĵ�ǰ��ָ��λ�ö��� n ���ַ������ַ��� str?�гɹ�ʱ���ظ��ַ�����ַ,��������NULL |
| �ı���������� | fputs(str, fp) | ���ַ��� str д�뵽�ļ�ָ�� fp ��ָ����ļ��ĵ�ǰдָ��λ�� �ɹ�ʱ���ط�0ֵ,��������EOF |
| ��ʽ�����뺯�� | fscanf(fp, ��ʽ�����ַ���,��ַ�б�) | ����ʽ���ƴ��������ĸ�ʽ,�� fp ��ָ����ļ��ж�ȡ����,�͵�ָ���������С� ����������ɹ�,����ʵ��д����ַ� ���������ʧ��,������EOF |
| ��ʽ��������� | fprintf(fp, ��ʽ�����ַ���,����б�) | ������������ƶ�����ʽд�� fp ��ָ����ļ��С� ����������ɹ�,����ʵ�ʶ��������� ��û�ж���������,������0 ���ļ����������ʧ��,������EOF |
| ���������� | size_t fread(buffer, size, count, stream) | ��ȡ [count_num] ������(ÿ�������СΪ?size(��С) ָ�����ֽ���),���������滻����?buffer?(������) ָ��������,�������Ը����������� ����������ֵ�Ƕ�ȡ���������� |
| ��������� | size_t fwrite(buffer, size, count, stream) | ��?buffer?��ָ��������е�����д�뵽������?stream?�� ���ɹ�,�ú�������һ�� size_t ����,��ʾԪ�ص�����,�ö�����һ�������������͡� ���������� count?������ͬ,�����ʾһ������ |
�������������û��ʲô�о�,����ȥ������������ϸ�Ľ���ÿ�������Ĺ�������,�ڴ�֮ǰ��Ҫ�Ƚ���һ������������ʲô��?
��(stream)
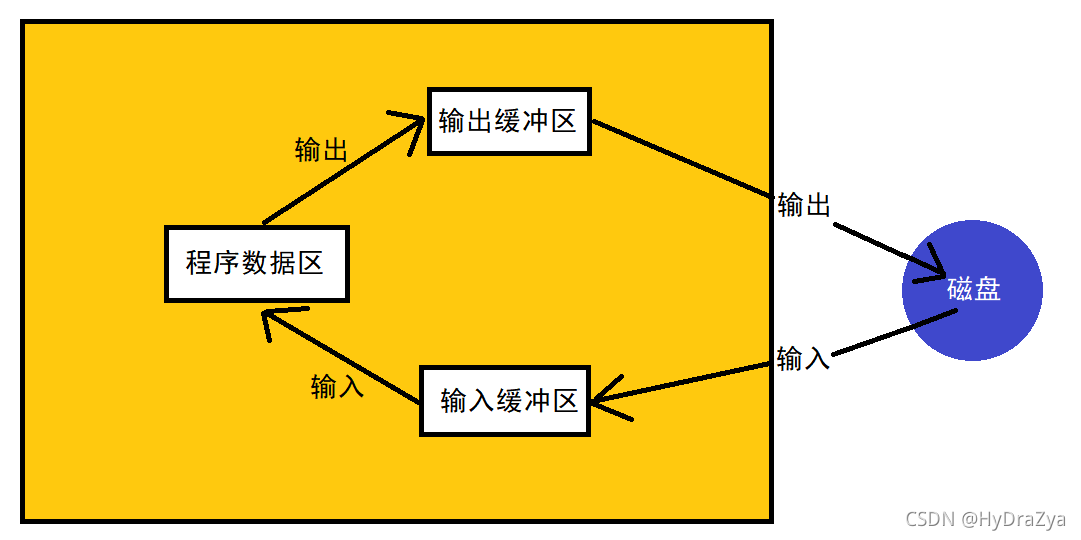
����:������������ݴ��͵Ĺ���, ��������ˮһ����һ��������һ��, ��˳��������������س�Ϊ��(stream), ��������������ʾ����Ϣ��Դ��Ŀ�Ķ˵����������������ʱ, ���ݴ��ļ����������ڴ�, ���������ʱ, ���ݴӼ���������ļ�(���ӡ���������ļ�)���ļ����ɲ���ϵͳ����ͳһ������, ��������Word���ļ�, ����C�����е������������ͨ������ϵͳ���еġ���������һ������ͨ��, ���ݿ��Դ����л���(�й��豸)���������, ��ӳ����������л�����
ͼ��:?
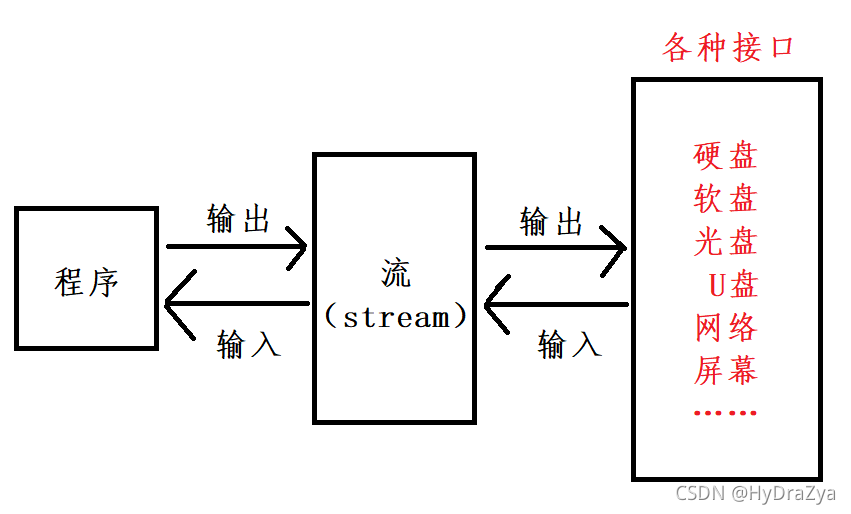
ע:C���Գ���,ֻҪ��������,��Ĭ�ϴ���������,���;�Ϊ FILE*
stdin?--- ��������?--- ����
stdout?--- �������?--- ��Ļ
stderr --- �������� --- ��Ļ
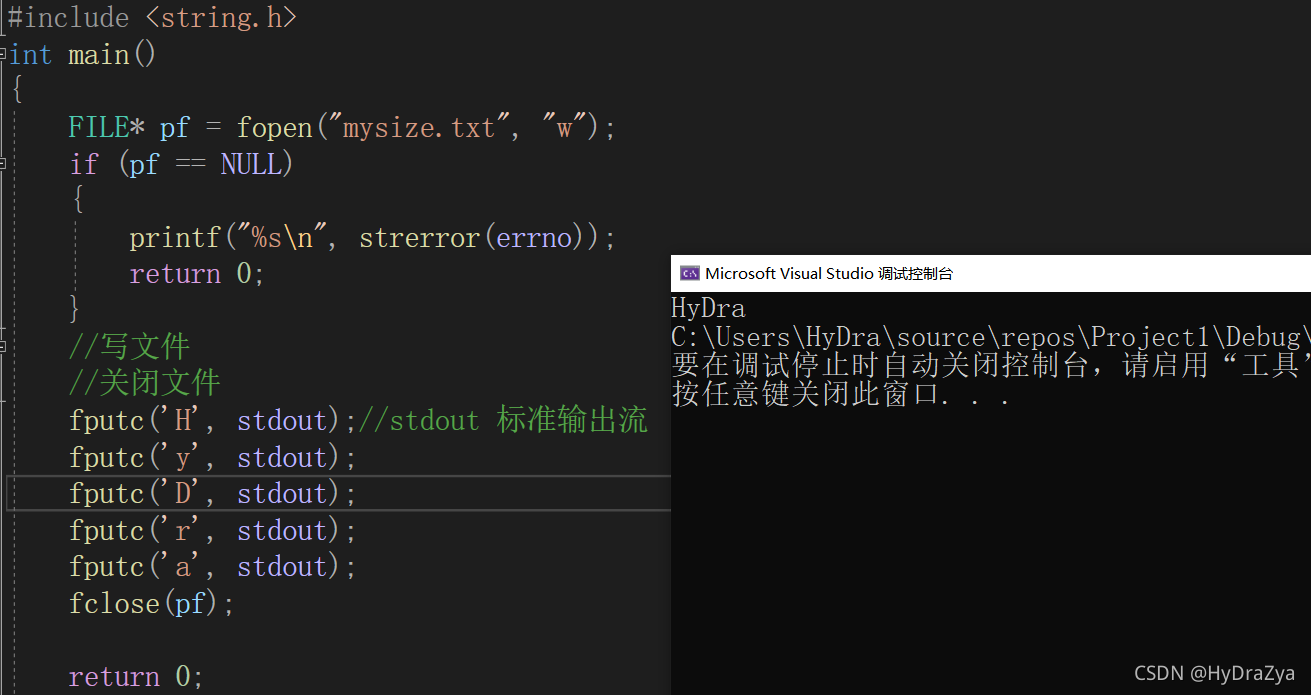
?fputc
��:
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main()
{
FILE* pf = fopen("mysize.txt", "w");
if (pf == NULL)
{
printf("%s\n", strerror(errno));
return 0;
}
//д�ļ�
//�ر��ļ�
fputc('H', stdout);//stdout �������
fputc('y', stdout);
fputc('D', stdout);
fputc('r', stdout);
fputc('a', stdout);
fclose(pf);
return 0;
}
ִ�н��:
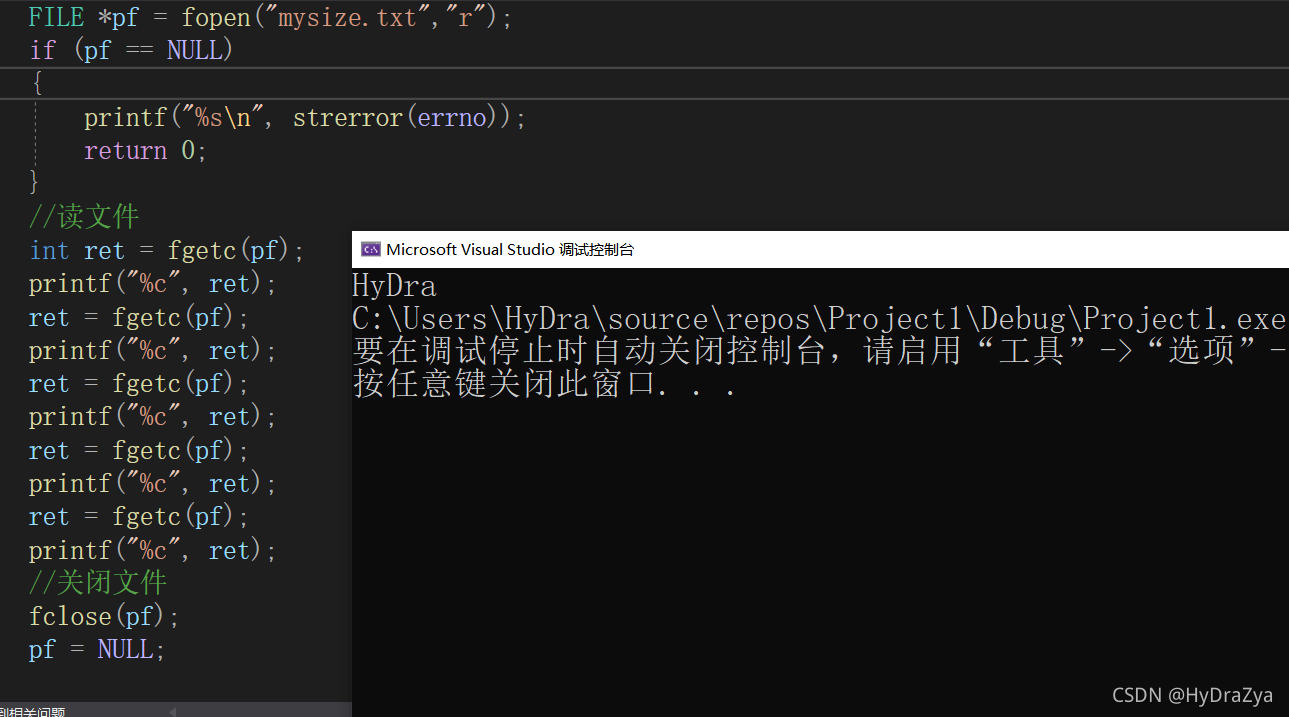
fgetc
��:
#include <stdio.h>
#include <errno.h>
#include <string.h>
int main()
{
FILE *pf = fopen("mysize.txt","r");
if (pf == NULL)
{
printf("%s\n", strerror(errno));
return 0;
}
//���ļ�
int ret = fgetc(pf);
printf("%c", ret);
ret = fgetc(pf);
printf("%c", ret);
ret = fgetc(pf);
printf("%c", ret);
ret = fgetc(pf);
printf("%c", ret);
ret = fgetc(pf);
printf("%c", ret);
//�ر��ļ�
fclose(pf);
pf = NULL;
return 0;
}
ִ�н��:?
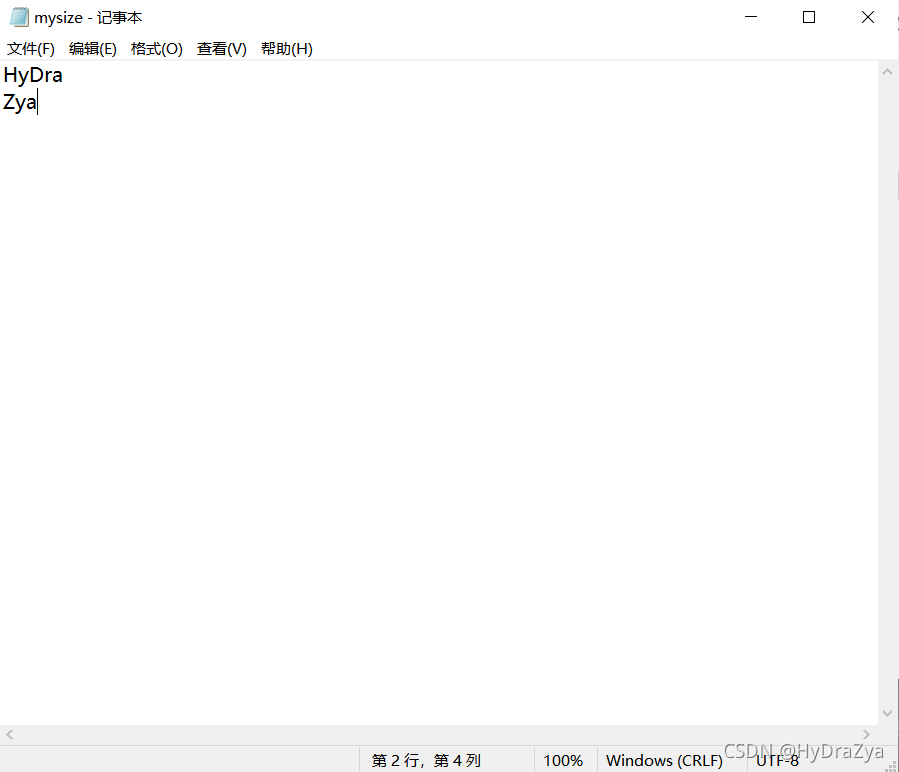
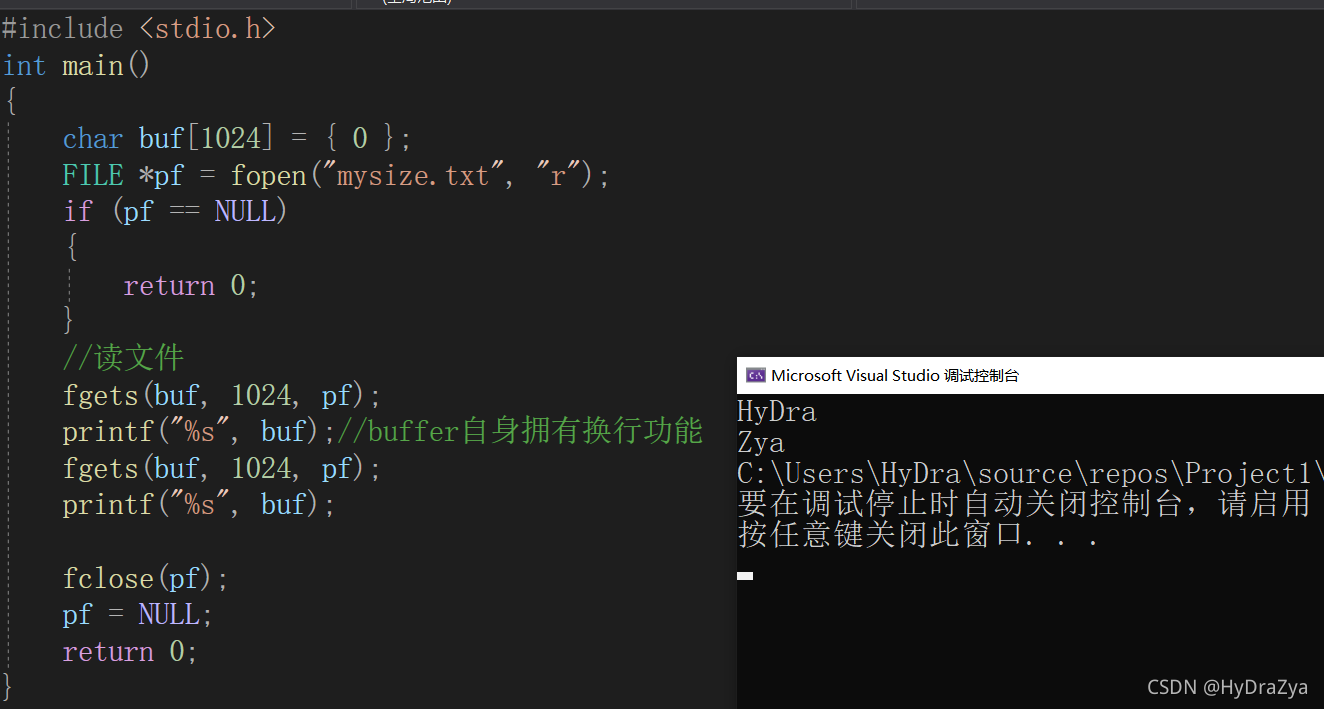
fgets
�ھ���ǰ�������� mysize.txt �ı��ڲ�����һ���ַ�,�����ܹ����õ�չ��Ч��:
��:
#include <stdio.h>
int main()
{
char buf[1024] = { 0 };
FILE *pf = fopen("mysize.txt", "r");
if (pf == NULL)
{
return 0;
}
//���ļ�
fgets(buf, 1024, pf);
printf("%s", buf);//buffer����ӵ�л��й���
fclose(pf);
pf = NULL;
return 0;
}
ִ�н��:
?fputs
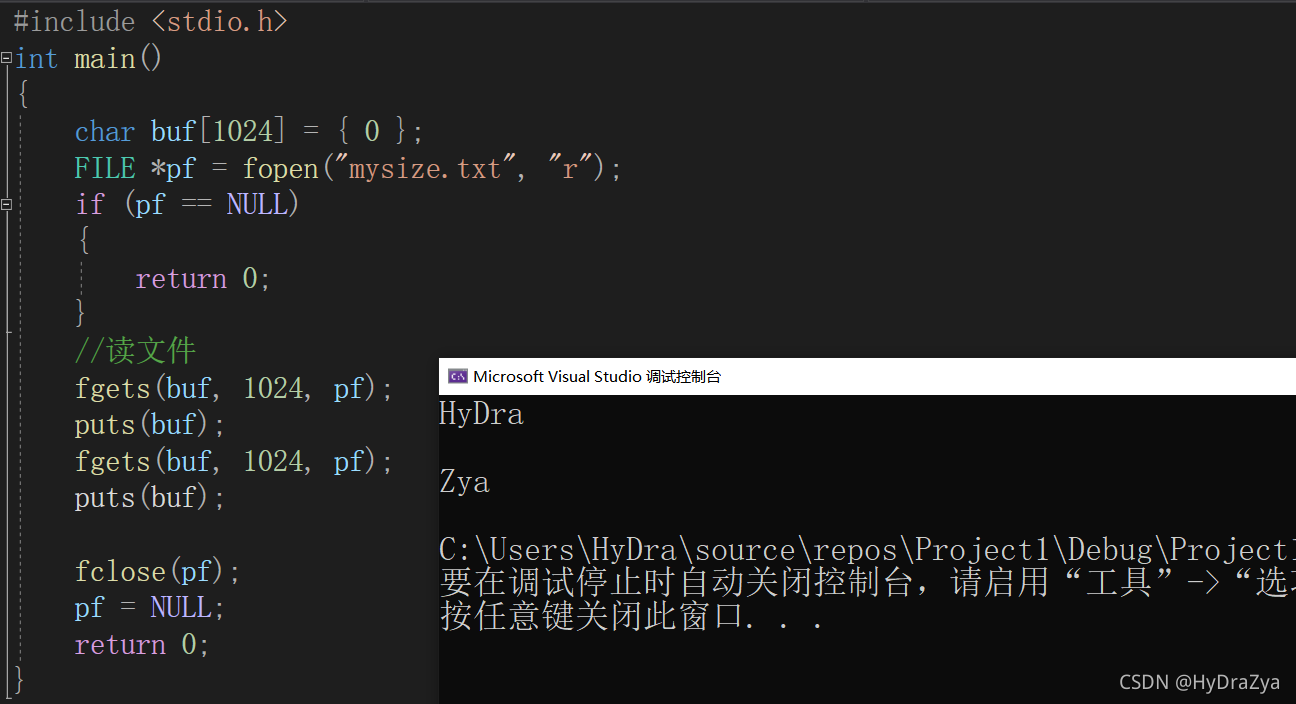
��1:
#include <stdio.h>
int main()
{
char buf[1024] = { 0 };
FILE *pf = fopen("mysize.txt", "r");
if (pf == NULL)
{
return 0;
}
//���ļ�
fgets(buf, 1024, pf);
puts(buf);
fgets(buf, 1024, pf);
puts(buf);
fclose(pf);
pf = NULL;
return 0;
}
ִ�н��:
��2:
#include <stdio.h>
int main()
{
//�Ӽ��̶�ȡһ���ı���Ϣ
char buf[1024] = { 0 };
fgets(buf, 1024, stdin);//�ӱ���������ȡ
fputs(buf, stdout);
//��������д���ȼ�����������д��
gets(buf);
puts(buf);
return 0;
}
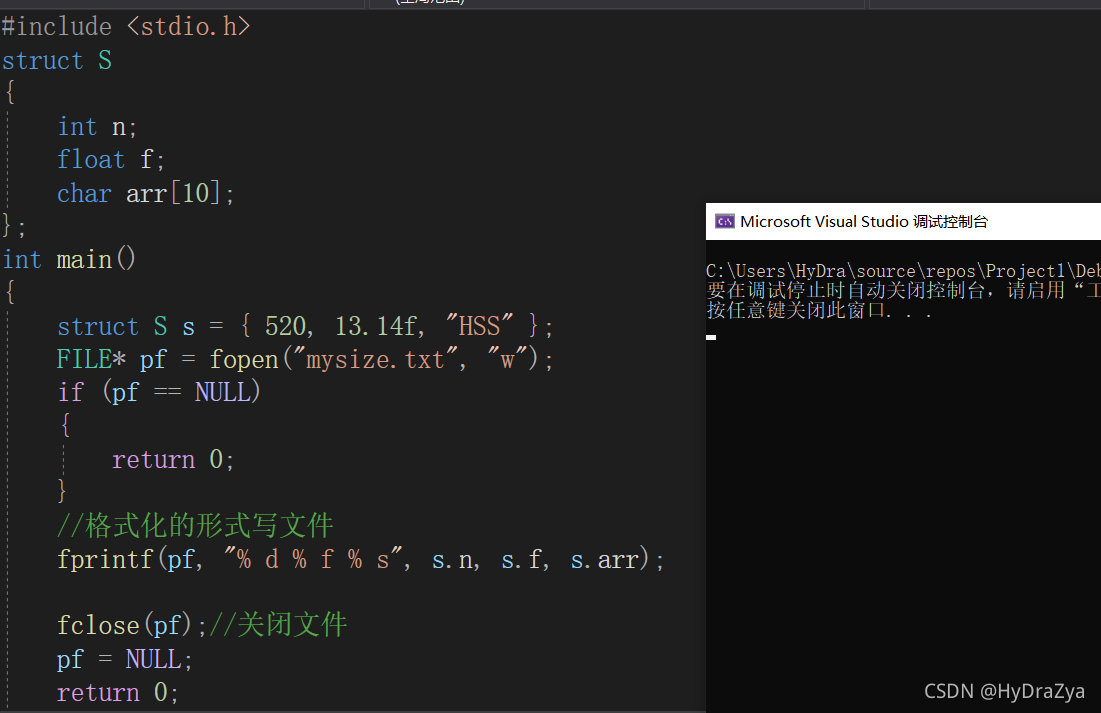
fprintf
��:
#include <stdio.h>
struct S
{
int n;
float f;
char arr[10];
};
int main()
{
struct S s = { 520, 13.14f, "HSS" };
FILE *pf = fopen("mysize.txt", "w");
if (pf == NULL)
{
return 0;
}
//��ʽ������ʽд�ļ�
fprintf(pf, "%d %f %s", s.n, s.f, s.arr);
fclose(pf);//�ر��ļ�
pf = NULL;
return 0;
}
ִ�н��:
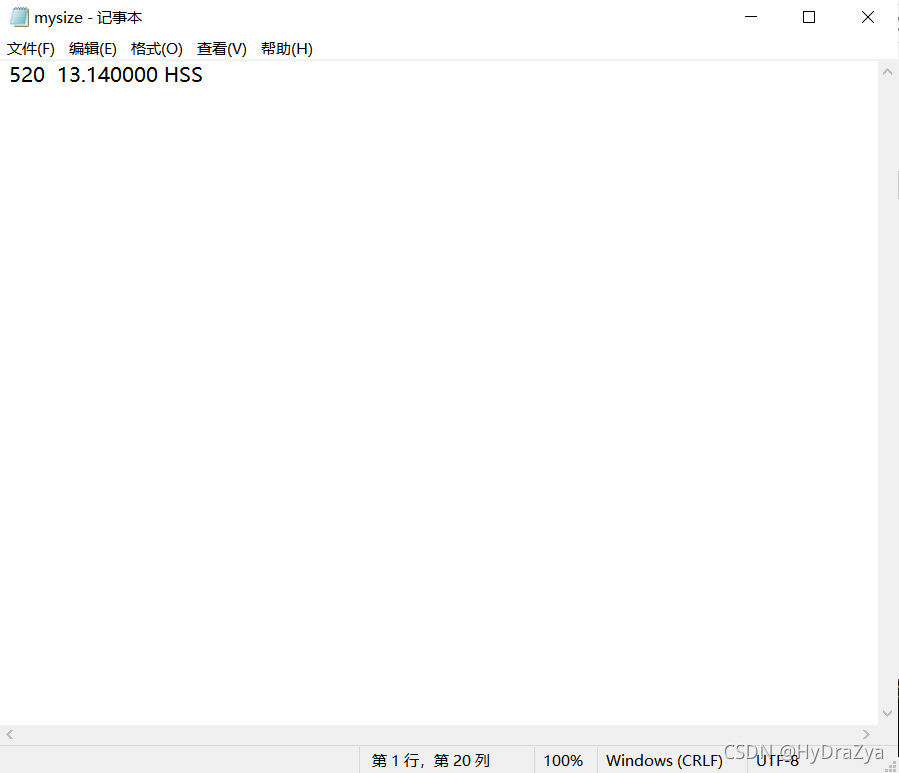
��ʱ������ȥ�鿴 mysize.txt ���±��ͻᷢ������������Ѿ�����ʽ�������滻���˸�д������:
fscanf
��:
#include <stdio.h>
struct S
{
int n;
float f;
char arr[10];
};
int main()
{
struct S s = { 0 };
FILE* pf = fopen("mysize.txt", "r");
if (pf == NULL)
{
return 0;
}
//��ʽ������������
fscanf(pf, "%d %f %s", &(s.n), &(s.f), s.arr);
printf("%d %f %s\n", s.n, s.f, s.arr);
fclose(pf);//�ر��ļ�
pf = NULL;
return 0;
}
ִ�н��:?

�Ա�һ�麯��
scanf / fscanf / sscanf
printf / fprintf / sprintf
��ʱ���ǻ�δ�˽�� sscanf �� sprintf,���������Ƚ��о���˵��:
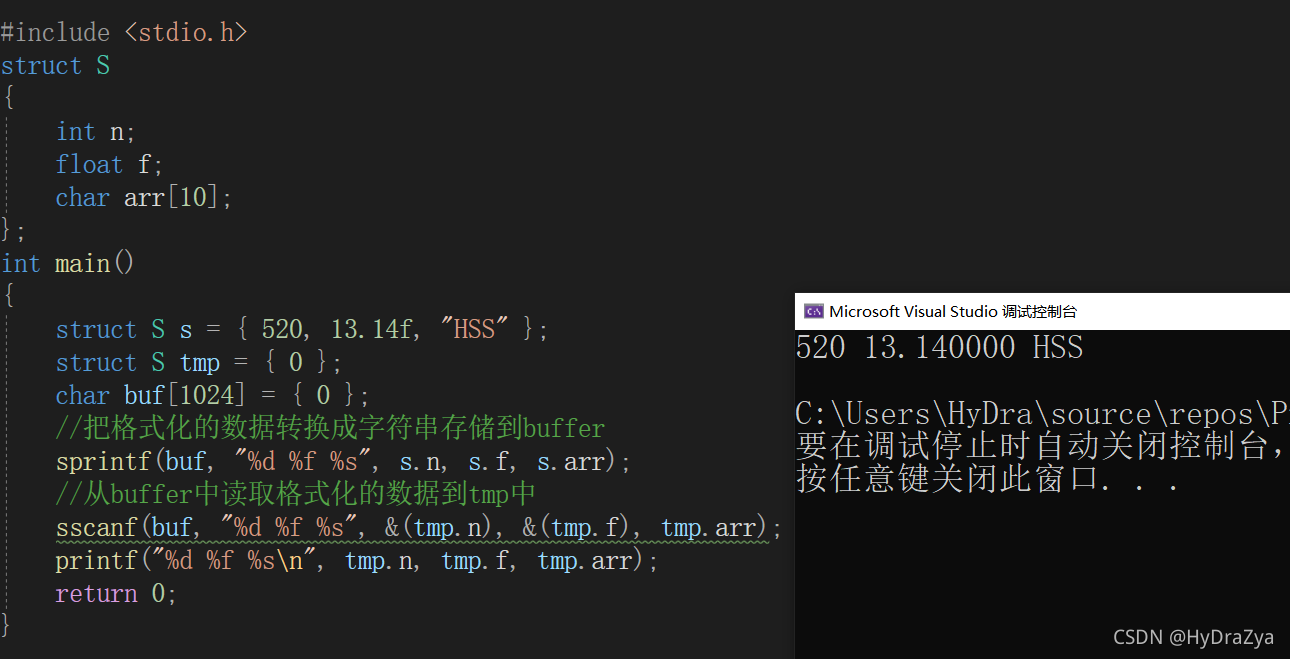
��:
#include <stdio.h>
struct S
{
int n;
float f;
char arr[10];
};
int main()
{
struct S s = { 520, 13.14f, "HSS" };
struct S tmp = { 0 };
char buf[1024] = { 0 };
//�Ѹ�ʽ��������ת�����ַ����洢��buffer
sprintf(buf, "%d %f %s", s.n, s.f, s.arr);
//��buffer�ж�ȡ��ʽ�������ݵ�tmp��
sscanf(buf, "%d %f %s", &(tmp.n), &(tmp.f), tmp.arr);
printf("%d %f %s\n", tmp.n, tmp.f, tmp.arr);
return 0;
}
ִ�н��: