[root@c-video-sh-1 services]# jmap -dump:live,format=b,file=dump_001.bin 14
Dumping heap to /home/services/dump_001.bin ...
Heap dump file created
2.3.将dump文件拷贝至本地
- 将dump文件从服务端拷贝至堡垒机。
- 将dump文件从堡垒机拷贝至本地。
上述步骤可以参考本人另一篇博客:通过堡垒机/跳板机实现文件在本地Mac与服务器之间的互传
2.4.通过MAT(Memory Analyzer Tool)分析dump文件
这里暂时不对MAT的按照与使用进行说明。
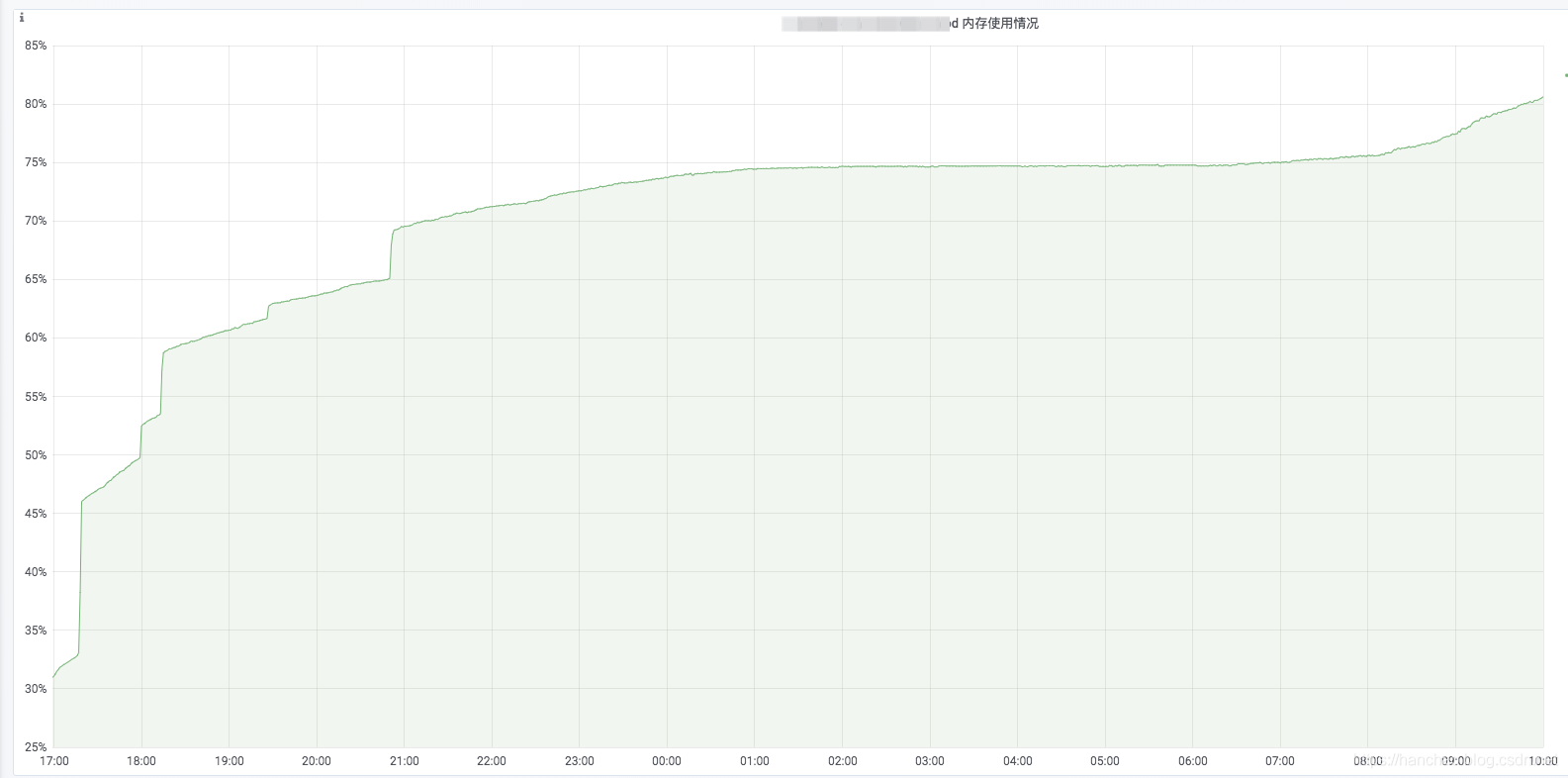
通过MAT打开dump文件,在Overview页面选择打开Leak Suspects,即:内存泄漏预测,如下:
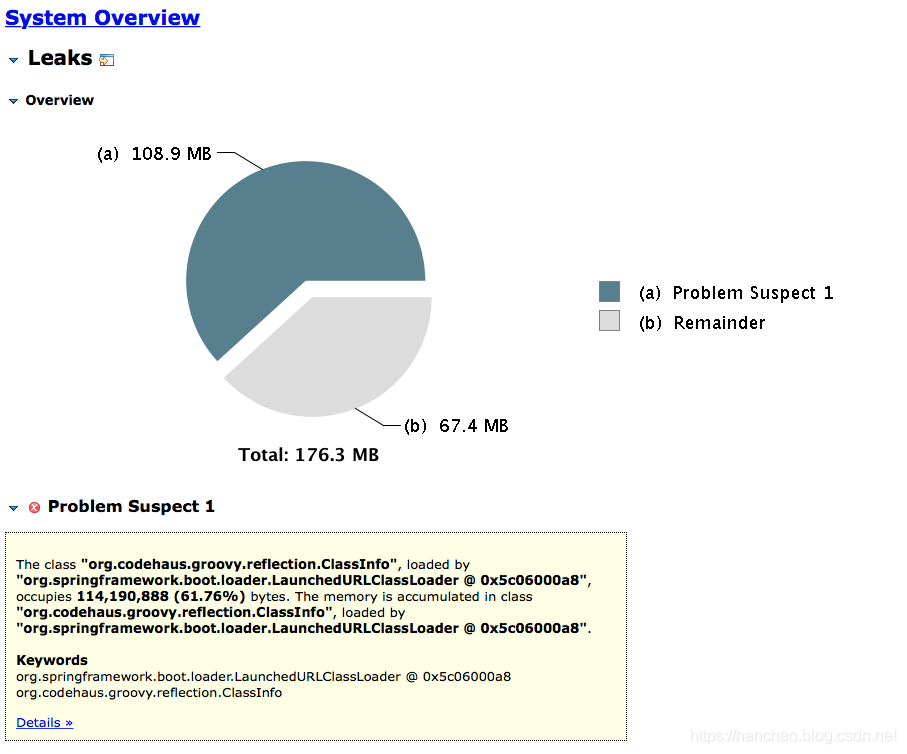
很明显,org.codehaus.groovy.reflection.ClassInfo这个类的实例很可能是造成内存泄漏的原因。
2.5.分析pom.xm依赖关系
我询问了同事,哪里用到了这个类org.codehaus.groovy.reflection.ClassInfo,他跟我说并没有用到。
因此,怀疑是基础服务用到了这个类,类似数据库、框架之类的。
在IDEA中,通过Option + Shift + Command + U快捷键打开依赖关系图。
然后通过Commond + F快速找到groovy包所在,最终发现了依赖groovy所在的包:sharding-sphere。
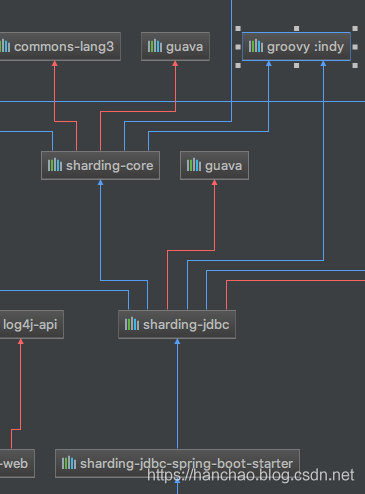
因为依赖groovy包的只有sharding-sphere,所以可以确定是sharding-sphere出了问题,也就是分库分表数据源。
2.6.最终定位问题所在
通过前面的定位,基本可以确定是因为分库分表的数据源配置不正确导致的。
所以询问了同事,为什么要用分库分表数据源,因为他这个项目不涉及分库分表,他说:项目的pom.xml是拷贝的别人的。。。
好吧,继续查询问题所在,发现他虽然依赖了分库分表的数据源,但是他的配置确实错误的。
最终导致的结果就是数据库连接得不到释放,连接上的数据不会自动回收,导致内存越来越大。
2.7.解决问题
2.7.1.实际解决方案
- 删除分库分表依赖,改用druid。
- 删除pom.xml中根本不会用到的很多依赖。
- 排除pom.xml中很多冲突但不影响使用的依赖。
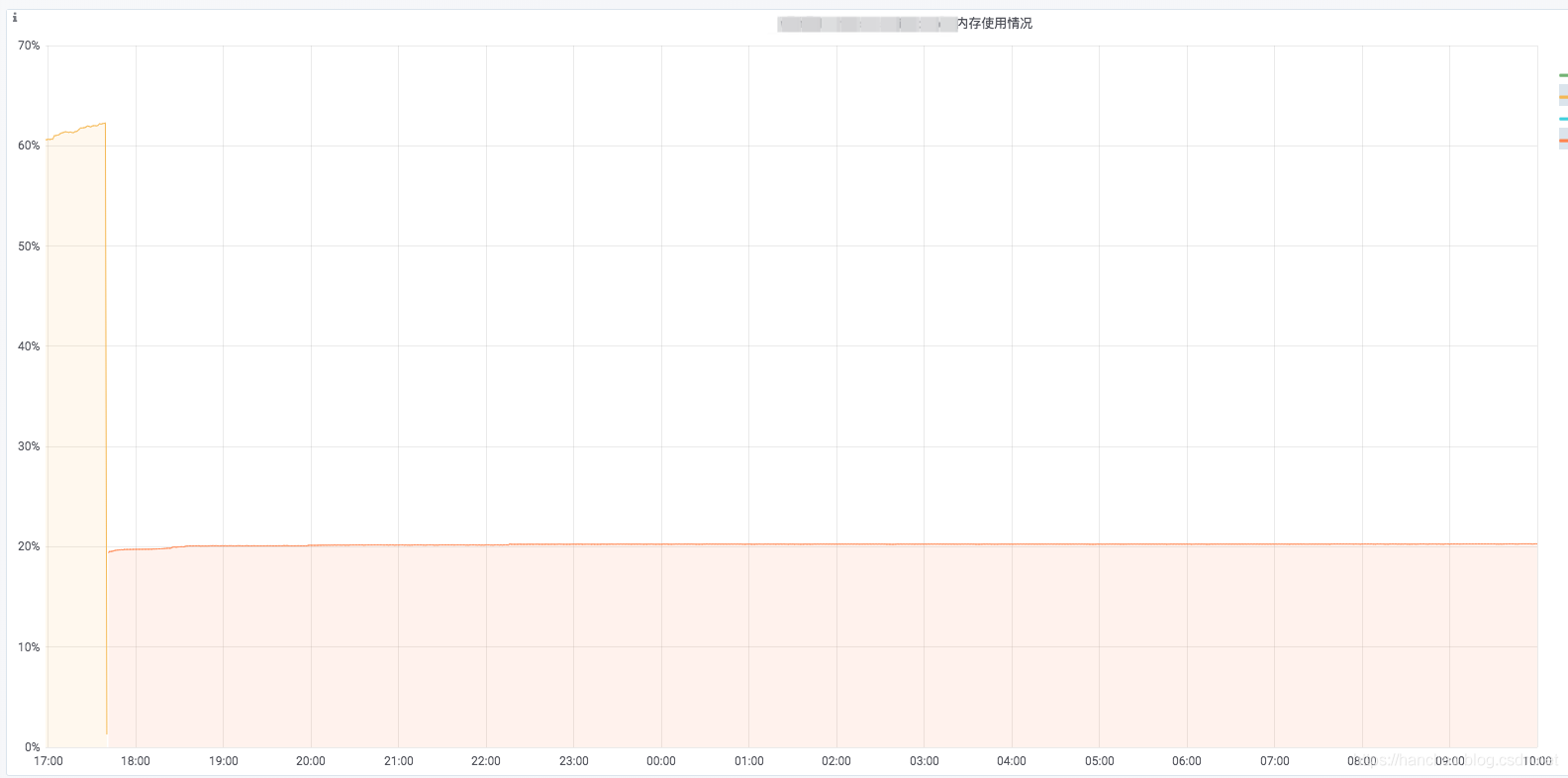
- 重新上线,问题解决:
- 在Spring Boot Admin中,一直保持
UP状态。 - 服务某接口的压测结果:最大QPS上升至
3000左右。 - 在k8s的pod监控,内存使用率维持在
20%不变。
2.7.2其他解决方案
- 还在测试环境对
继续使用分库分表数据源的方案进行了测试,过程就是修正他之前错误的配置。 - 测试之后,发现问题同样解决,与实际解决方案的表现基本一致。
3.总结
- pom.xml中的依赖建议按需配置,不要去拷贝别人的配置,这不是一个好习惯。
- pom.xml中冲突的但是不影响使用的依赖也要及时排除,不要项目能run就放任不管,这不是一个好习惯。
- 配置文件中的每个配置项的作用是什么自己要弄清楚,不要去拷贝别人的配置,这不是一个好习惯。
cs