源码见:https://github.com/hiszm/hadoop-train
Hadoop概述
http://hadoop.apache.org/

The Apache? Hadoop? project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Modules
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS?): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
- Hadoop Ozone: An object store for Hadoop.
翻译翻译
-
分布式文件系统:HDFS用于将文件分布式存储载很多的服务器上
-
分布式计算框架:MapReduce实现在很多机器分布式并行计算
-
分布式资源调度框架:YARN实现集群资源管理以及作业的调度
Hadoop核心组件之HDFS.
起源
特点
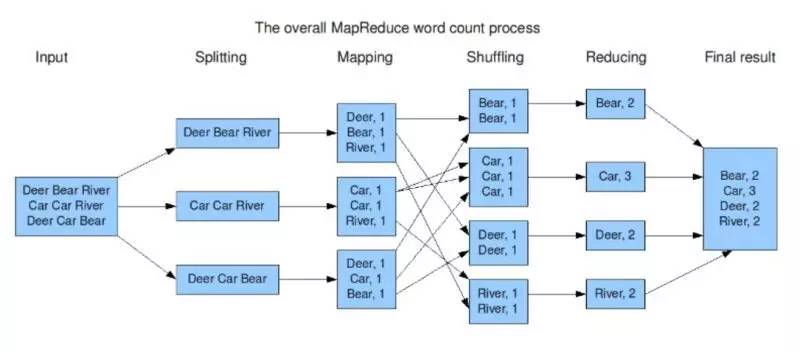
Hadoop核心组件之MapReduce
起源
- 源于Google的MapRedece的论文
- 是Google MapReduce的克隆版
特点
Hadoop核心组件之YARN
- Yet Another Resource Negotiator
- 负责整个集群资源的管理和调度
特点: - 扩展
- 容错
- 多框架资源统一调度

Hadoop优势
- 数据存储:数据块多副本
- 数据计算:重新调度作业计算
- 机器扩展:可以线性扩展机器,集群可以包含上千节点
- 成本降低:去IoE
- 生态圈成熟
Hadoop发展史
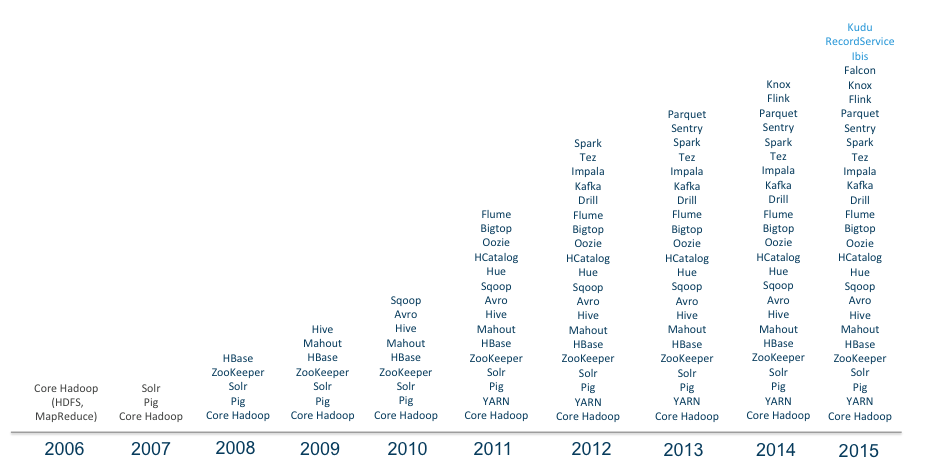
Hadoop生态圈

特点
Hadoop发行版选型
-
Apache社区版本
- 优点:完全开源免费。社区活跃文档、资料详实
- 缺点:复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。
复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
-
第三方发行版本(如CDH,HDP,MapR等)
- 优点:基于Apache协议,100%开源。版本管理清晰。比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 缺点:部分不开源
OOTB环境的使用
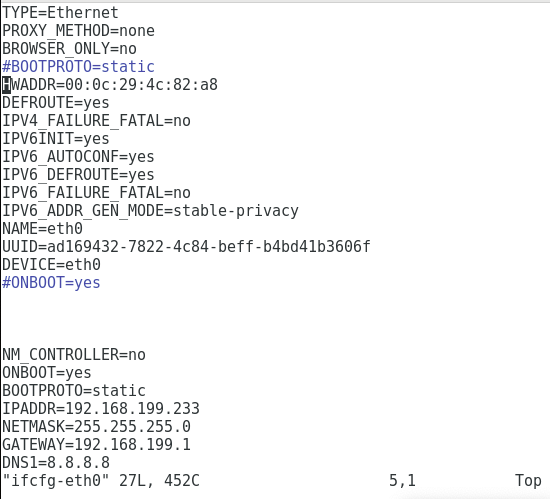
//切换到root
$ sudo -i
# cd /etc/sysconfig/network-scripts/
# ls
//删除
# rm -f ifcfg-lo
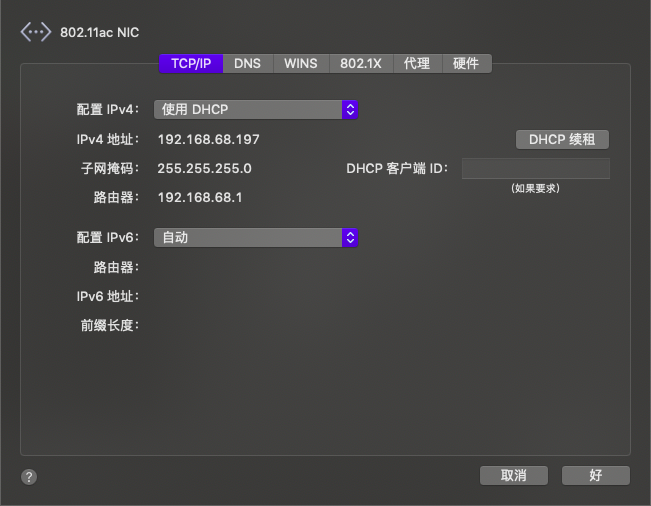
PING baidu.com (220.181.38.148) 56(84) bytes of data.
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=1 ttl=46 time=42.7 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=2 ttl=46 time=42.0 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=3 ttl=46 time=45.0 ms
64 bytes from 220.181.38.148 (220.181.38.148): icmp_seq=4 ttl=46 time=44.4 ms

cs