java基础知识
类的定义和声明
- 类的定义:基于面向对象思想,现实生活中具有共同特性的对象的抽象就称之为类。类由类声明和类体构成,类体又由变量和方法构成。
- 声明:访问说明符 class 类名 extends 超类名 implements 接口名
- 类体
- 成员变量:指类的一些属性。格式:访问说明符 数据类型 变量名
- 成员方法:指类创建的对象能做什么。格式:访问说明符 数据类型 方法名(数据类型1 变量名1,数据类型2 变量名2)
方法的重载
- 概念:同一个类中,有两个或者多个重名的方法,但是方法的参数个数、类型、顺序至少有一个不一样,构成方法重载。
- 作用:使用同一个方法名,根据参数的不同,调用不同的方法,实现相似的操作。
类的继承
- 概念:继承就是子类集成父类的特征和行为,使得子类对象具有父类的属性和方法。
- 作用:子类可以继承父类全部的功能,可以增加新属性、新功能。
方法的重写
- 重写的概念:重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。
- 重写的作用:子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
方法的隐藏
- 概念:方法的隐藏与重写类似,重写是子类覆盖父类的对象方法,隐藏就是子类覆盖父类的类方法
接口
-
接口的定义和声明
- 接口的定义:接口就是一个规范。接口就是某个事物对外提供的一些功能的说明。我们还可以利用接口实现多态功能,同时接口也弥补了Java单一继承的弱点,也就是类可以实现多个接口。
- 接口的声明:
public interface Myinterface {
// 定义程序使用的常量的接口,接口中只能有常量。
public static final double price = 1450.00;
public static final int counter = 5;
//接口中所有的方法都没有方法体。
public void add(int x, int y);
public void volume(int x,int y, int z);
}
-
接口的实现
-
接口实现:
//实现接口
public class MyImple implements Myinterface {
@Override
public void add(int x, int y) {
}
@Override
public void volume(int x, int y, int z) {
}
}
-
接口举例:
//实现多个接口
public class MyImple implements Myinterface ,MyInterface2{
@Override
public void add(int x, int y) {
}
@Override
public void volume(int x, int y, int z) {
}
@Override
public void countpp() {
}
}
数组
- 数组的概念:数组其实也是一个容器,可以用来存储固定个数,相同类型的数据,数组中存储的数据叫做元素。
- 数组初始化:
- int[] arr = new int[5];
- int[] arr = new int[5]{1,2,3,4,5};
- int[] arr = {1,2,3,4,5};
Obejct类
- Object类概念:Object类是所有类的父类,任何一个类在定义的时候没有明确的继承一个父类的话,那么他就是Object的子类。
- toString方法:它通常只是为了方便输出,比如System.out.println(xx),括号里面的“xx”如果不是String类型的话,就自动调用xx的toString()方法
- equals方法:equals()用来比较两个对象内容是否一致(内存地址不同)
String类
- length方法:长度
- trim方法:去空格(前后的空格可以去掉,中间的不可以)
- String构造方法:String(byte[] bytes),String(byte[] bytes, int offset, int length)
- indexOf方法:查询xx字符或字符串在这个字符串里的位置
- substring方法:裁剪字符串
- equals方法:比较内容是否一致
String、StringBuffer和StringBuilder使用比较
- String:字符串常量
- StringBuffer:字符缓冲变量,线程安全
- StringBuilder:字符缓冲变量,非线程安全
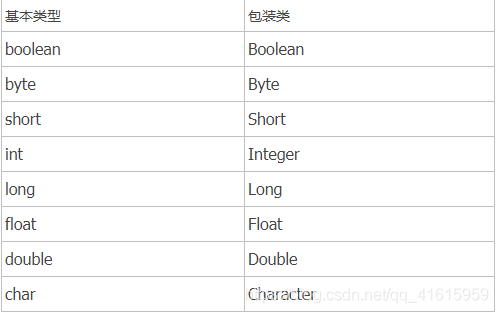
类和数据结构-包装类
- 类概念:在面向对象操作中经常需要将基本数据转换成对象,这种和基本数据类型对应的类统称为包装类(Wrapper Class)
- 类用途:
- 作为和基本数据类型对应的类型存在,方便对象的操作和数值转换;
- 当方法的参数是Object时,不能传入基本数据类型,需要使用包装类。包装类型的初始值为null
- 和基本数据类型对应关系:比基本数据类型安全
包装类的数值转换
容器类
- Collection和Map:
- HashSet:元素不重复、无序、最多只能有一个null
- Vector:基于数组,同步,线程安全
- ArrayList:基于数组,允许null元素,不同步,线程不安全,查找、修改效率高
- LinkedList:基于链表,允许null元素,增加、删除元素效率高
- HashMap:key不重复,线程不安全,可以有一个null作为key
- Hashtable:key不重复,线程安全,key和value不允许null
IO流
public static void main(String[] args) {
File f = new File("D:/abc.txt");
try {
FileInputStream fis = new FileInputStream(f);
byte[] all = new byte[(int)f.length()];
fis.read(all);
for(byte b: all){
System.out.println((char)b);
}
fis.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
File f = new File("d:/abc.txt");
byte[] date = {88,89}
FileOutputStream fos = new FileOutputStream(f);
fos.write(data);
fos.close();
JAVA异常
- 异常的概念:异常是指当程序中某些地方出错时创建的一种特殊的运行时错误对象。程序捕捉到这个异常后,可以编写相应的异常处理代码进行处理。
- 异常的分类:Throwable是java.lang包中一个专门用来处理异常的类,他有两个子类,即Error和Exception
异常的用法
- ArithmeticException 算数运算异常,例如一个整数除以0
- ClassNotFoundException 未找到指定名字的类或接口引起异常
- NullPointerException 空指针异常 程序访问空的未分配内存的对象
- EOFException 文件输入过程中发生异常导致读取非正常结束
- FileNotFoundException 找不到指定路径的文件 可能是path没有配,也可能是文件名写错了
- InterruptedException 线程中断异常,线程操作时可能引发
- IllegalAccessException 试图访问一个非public方法
SQL基础
- 表(Table):由行(Row)和列(Column)组成。每列又称为一个字段,每列的标题成为字段名,一行成为一条数据,一个数据库表由一条或多条记录组成,没有记录的表成为空表。
- 用户(user):所谓用户就是有权限访问数据库的人,同时需要自己登陆账号和密码。一般来说,数据库用户分为:管理员用户和普通用户,前者可对数据库进行修改删除,后者只能进行阅读查看等操作。
- 索引(Index):索引是指根据指定的数据库表列建立起来的顺序,建立索引的目的是为了快速访问数据的途径,并且可以监督表的数据,使其索引所指向的列中的数据不重复。
- 触发器(Trigger):触发器(Trigger):触发器是一个用户定义SQL事务命令的集合,当对一个表进行插入,更改、删除时,这组命令就会自动执行。就好像是我们每天早上设定的闹钟一样,一到那个时间点,闹钟就会响起!
- 视图(View):视图看上去跟表似乎一模一样,但其实是一个虚拟的表,并不是在数据库中实际的存在;视图是通过查询数据库表产生的,它限制了用户能看到和修改的数据,只显示用户所需要的数据信息。
数据库用户
-
创建:create user happy@‘localhost’ identified by ‘veryhappy’;
-
授权:grant all on fx.test to ‘happy’@‘localhost’
-
更改密码:alter user ‘happy’@'localhost’identified by ‘123’
update mysql.user set password=password(‘123456’) where user=‘fanxu’;
flush privileges;
-
删除:drop user happy@‘localhost’
数据库权限
- 数据对象权限
- all on
- alter on
- select on
- update on
- delete on
- insert on
- 系统权限
grant的作用赋予权限,用法举例:
- GRANT CONNECT,RESOURCE TO 用户名;
- GRANT SELECT ON 表名 TO 用户名;
- GRANT SELECT,INSERT,DELETE ON 表名 TO 用户名1,用户名2;
REVOKE的作用是回收权限,用法举例:
- REVOKE CONNECT,RESOURCE FROM 用户名;
- REVOKE SELECT ON 表名 FROM 用户名;
- REVOKE SELECT ,INSERT,DELETE ON 表名 FROM 用户名1,用户名2;
DQL数据查询语句
-
多表查询:多表查询允许你在查询的FROM条件后面跟多个表,然后把表之间的关系在WHERE条件后进行连接。
select A.fee_name from fee_item A,fee_list B where A.fee_id=B.fee_id;
-
外连接:多表查询的外连接技术,可以列出多表查询中其中一个表的全部记录。Oracle在where条件等式的一边加上(+)来表示外连接,(+)放在取全部记录的表的另一边;也可用left join on,right join on 和 full join on 表示。
select A.employee_id ,A.employee_name,B.dep_id from employee_info A,dep_info B where A.dep_id=B.dep_id(+)
select A.employee_id ,A.employee_name,B.dep_id from employee_info A left join dep_info B on A.dep_id=B.dep_id
-
嵌套查询:select查询语句里可以嵌入select查询语句,称为嵌套查询,最多可以嵌套16层,层次过多会影响性能。
select fee_name,fee_sum from (select A.fee_name as fee_name,SUM(b.fee) as fee_sum from fee_item A,fee_detail B WHERE A.fee_id=B.fee_id group by A.fee_name) as fee order by fee_sum
-
子查询:将子查询或in或exists当成where条件的一部分,这样的查询称为子查询。
where中可以包含一个select语句的子查询;where中可以包含in,exists语句
select fee_id from fee_item where fee_id in (select fee_id from fee_list)
select fee_id from fee_item where exists(select fee_id from fee_list)
-
查询排序
- ORDER BY语句根据指定的列对结果集进行排序,ASC指定列按升序排列;DESC按降序排列。ORDER BY默认按升序对记录进行排序,即省略了ASC。
select dep_name,total_num from dep_info order by total_num
#按照部门人数的升序排序
select dep_name,category,total_num from dep_info order by category,total_num desc
#先按照部门类别升序排列,在部门类别相同的情况下,按照部门人数降序排序。
-
查询分组
- SQL无法把正常的列和汇总函数结合在一起,这时就需要GROUP BY子句,它可以对SELECT的结果进行分组后再应用汇总函数。HAVING子句允许将汇总函数作为条件,使用在查询语句中。
#GROUP BY例子:
select fee_id,count(fee) from fee_detail group by fee_id;
select fee_id,sum(fee) from fee_detail where fee>10 group by fee_id;
#HAVING例子:
select fee_id,sum(fee) from fee_detail group by fee_id having sum(fee)>50
优化表查询的方法
- 表的查询顺序(多表查询优化)
- SQL语句中FROM字句中的表名,执行顺序上最先处理的表叫基础表。
- 在FROM字句中包含多个表的情况下,选择记录条数最少的表作为基础表
- 如果3个以上的表连接查询,那就需要选择交叉表作为基础表,交叉表是指那个被其他表所引用的表。
- 用EXISTS代替IN:在许多基于基础表的查询中,为了满足一个条件,往往需要对另一个表进行联接。在这种情况下,使用EXISTS(或NOT EXISTS)通常将提高查询的效率。
#低效
select empno from emp where empno>0 and deptino in (select deptno from dept where loc=‘MELB’)
#高效:
select empno from emp where empno>0 and exists(select ‘X’ from dept where dept.deptno=emp.deptno and loc=‘MELB’)
SQL基础-索引
索引使用原则
- 适合索引的列是出现在where字句中的列,或者连接字句中指定的列。
- 基数较小的列,索引效果很差,没有必要在此列建立索引。
- 使用短索引,如果对长字符串列进行索引,应该指定一个前缀长度,这样能够节省大量索引空间。
- 不要过度使用索引。索引需要额外的磁盘空间,并降低写操作的性能。
DML数据操作语句
- INSERT INTO 表名(字段名,字段名2,…)VALUES(值1,值2,…);
- UPDATE 表名 SET 字段名1=值1 ,… WHERE 条件;
- DELETE FROM 表名 WHERE 条件;
注意:以上数据操作完成后,必须加上事务处理结束的命令COMMIT才能正式生效,如果想撤回这些操作,可以使用命令ROLLBACK复原。
DDL数据定义语句
- 创建表
- create table employee(id varchar(16),name varchar(20),age integer);
- 修改表
- alter table employee add address varchar(100);
- 删除表
Linux常用命令
- pwd查询当前位置
- ls查询当前目录下的文件
- -l 查询所有文件的详细信息
- -a 查询所有文件(包括隐藏文件)
- -R 查询目录下所有的文件(包括目录里的文件)
- cd切换当前目录
- cat查看文件文本内容(适用于短文本)
- more分屏查看文件文本内容,空格下一屏,CTRL+B上一屏,=输出当前行的行号,q退出more(适用于长文本)
- df查看文件系统磁盘使用情况
- chmod 改变文件的权限 例如chmod u+x chmod 751 u用户 g组 o其他用户
- ps -u 用户名
- mkdir 目录名
- cp file1 file2 将file1复制成file2
- cp -r dir1 dir2
- mv file1 file2 将file1重命名为file2
- mv file1 dir 将file1移动到dir下名字仍然为file1
- rm -r 删除目录
- rm -f 无提示删除
- rm -rf * 删库跑路专用代码
- find文件查找
- find . -name hello 寻找当前目录及所有的子目录内叫hello的文档
- find . ctime +7 找出7天内未被更动的文档
- find . -size +2000c 找出大小超过2000bytes的文档
- find /tmp -user b1234567 在/tmp下归属用户b1234567的文档
- find . -name test* 查找当前目录及其子目录文件名前4位为test的文件名
- tar归档命令
- -c新建一个压缩文档,即打包
- -x解压文件
- -t查看压缩文档里的所有内容
- -r向压缩文档里追加文件
- -u更新原压缩包中的文件
- 辅助选项:
- -z:是否同时具有gzip的属性?即是否需要用gzip压缩或解压?一般格式为xxx.tar.gz或xx.tgz
- -v:显示操作过程!这个参数很常用
- -f使用文档名,注意,在f之后要立刻接文档名,不要再加其他参数!
- 例子:
- tar cvf 123.tar 111 222 将111和222打包成123.tar
tar tvf 123.tar 查看123.tar中归档的文件
tar czvf 123.tar.gz 111 将111打包并压缩成 123.tar.gz
加密算法
- MD5:不可逆:例如某些已经存入数据库中的密码。当需要验证密码的时候,用户输入密码,经过加密后,和数据库中已经存过的应该是一样的。
cs