什么是框架:就是一个集成了很多功能,并且具有很强的通用性的一个项目模板
如何学习框架: 专门学习框架封装的各种功能的详细用法
什么是scrapy :爬虫中封装好的一个明星框架。
功能: 学习计划.高性能持久化存储,异步的数据下载,高性能的数据解析,分布式
scrapy 框架的基本使用 :环境安装:-mac或者linux? pip install scrapy
??????????????????????????????? -win? pip install wheel
??????????????????????????????? -下载twisted:
??????????????????????????????? -安装twisted:
??????????????????????????????? -pip install pywin32
??????????????????????????????? -pip install pywin32
??????????????????????????????? 测试 : 终端 输入 scrapy 没报错 说明安装成功
??????????????????? -创建一个工程: scrapy startproject 工程的名称
??????????????????? -cd 工程名称
??????????????????? 再 scrapy genspider? 爬虫文件名字随便写? + url? 例如:scrapy genspider first www.xxx.com
??????????????????? scrapy.cfg 配置文件? 目前用不到?? spiders 爬虫文件夹或者为爬虫目录????? 里面一定要放入一个 爬虫源文件
??????????????????? pipelines.py 配置? settings.py工程的配置文件 经常使用
??????????????????? - 在spiders子目录 建立py文件? 在里面写爬虫代码? :
???????????????????? 再 scrapy genspider? 爬虫文件名字随便写? + url? 例如:scrapy genspider first www.xxx.com
??????????????????????? - spiders? genspider? spiderName(就是py文件的名称随便起的) +起始的url
??????????????????? - 执行工程:
??????????????????????? scrapy crawl py文件名称????????????????????????????????????????? clear清屏幕
??????????????????? 干扰数据清除 : scrapy crawl py文件名称 --nolog
-- 数据解析? :糗百案例yiubaiPro
-- 持久化存储:
??????? --基于终端指令:scrapy crawl py名字 -o 自定义保存的文件名? 例如:scrapy crawl qiubai0 -o qiubai.csv
??????????? - 要求:只可以将parse方法的返回值存储到本地的文件中? 不可以存到数据库? parse就是def parse(self, response)
??????????? - 注意: 持久化对应的文本文件类型只能是:('json', 'jsonlines', 'jl', 'csv', 'xml', 'marshal', 'pickle')
??????????? - 指令: scrapy crawl py名字 -o 自定义保存的文件名? 例如:scrapy crawl qiubai -o qiubai.csv
??????????? - 好处: 简洁 高效 便捷
??????????? - 缺点: 局限性比较强(数据只能保存到指定文件格式中)
?? 重 要点? --基于管道:
? ? ? ? ? ? ? ? ? ? ?- 编码流程:
? ? ? ? ? ? ? ? ? ? ? ? ?- 数据解析
? ? ? ? ? ? ? ? ? ? ? ? ?- 在item类中定义相关属性
? ? ? ? ? ? ? ? ? ? ? ? ?- 将解析的数据封装存储到item类型的对象中
? ? ? ? ? ? ? ? ? ? ? ???- 将item类型的对象提交给管道进行持久化存储的操作??? pipelines.py 翻译就是管道的意思
? ? ? ? ? ? ? ? ? ? ? ? ?- 在管道类的process_item中要将其接收到的item对象中存储的数据进行持久化存储操作
? ? ? ? ? ? ? ? ? ? ? ? ?- 在配置文件中开启管道
? ? ? ? ? ? ? ? ? ? ? ? ?- 优点 : 通用性强。 存数据库什么的
# 基于终端存储 方式
import scrapy
class QiubaiSpider(scrapy.Spider):
name = 'qiubai'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.qiushibaike.com/text/']
def parse(self, response):
# 解析:作者的名称+段子内容
div_list = response.xpath('//div[@class="col1 old-style-col1"]/div')
for div in div_list:
# author content 不是返回值 是局部变量
all_data = [] # 存储所有解析到的数据
# author = div.xpath('./div[学习计划]/a[2]/h2/text()')[0].extract() # [0] 列表长度
author = div.xpath('./div[学习计划]/a[2]/h2/text()').extract_first()
# [0] 列表长度 一定要确定 该列表中只有一个列表元素才可以用extract_first() 将列表中第0个元素变成字符串
# 所有 xpath取回的都是列表 , 但是列表一定是Selector类型对象
# extract 可以将Selector 对象中data参数储存的字符串提取出来
content = div.xpath('./a[学习计划]/div/span//text()').extract()
# 现在本身就是列表 但是列表也能调用.extract() 但返回的是一个列表
# 列表调用.extract()之后,则表示将列表中每个Selector对象中的data对应的字符串提取出来
content = ''.join(content) # 列表转成字符串
# print(author, content)
dic = {
'author': author,
'content': content
}
all_data.append(dic)
return all_data
??? - 面试题 :将爬取的数据一份进行存储一份存入数据库,如何实现? 通过管道
??????????? - 将管道文件中一个管道类对应的是将数据存储到一个平台
??????????? - 爬虫文件提交的item只会给管道中的第一个被执行的管道类接收
??????????? - process_item中的reture item表示将item传递给下一个即将被执行的管道类
?- 基于Spider的全站数据爬取 : 全站数据爬取就是:
??? - 就是将全网站中某板块下的全部页码对应得页面数据进行爬取
??? - 爬取校花网中得照片名称
??? - 实现方式:
??????????? - 将所有页面的url添加到 srart_urls列表当中 (不推荐使用)
??????????? - 自行手动进行请求发送(推荐)
??????????????? - 手动请求发送 :
??????????????????? - yield yield scrapy.Request(url=new_url, callback=self.parse) :callback :专门用于数据解析的
?-- 五大核心组件: 引擎 ,管道 ,引擎 ,下载器 ,spider ---》互联网
??? - spider --》引擎--》调度器--》过滤器
??? - spider --》引擎--》调度器--》队列
-- 请求传参:应用的非常广
??????? --使用场景: 如果爬取解析的数据不在同一张页面中。(深度爬取)
??????? --需求 :爬取boos的直聘的岗位名称和岗位描述
??????? --我们爬取的解析数据不在同一个页面 就要用 请求传参
--图片爬取之ImagesPipeline?? 这是一个管道类? 专门用于图片数据爬取? 之前学的 都是用于字符串爬取?
??? - 基于scrapy爬取字符串类型的数据爬取和爬取图片类型的数据区别:
??????? - 字符串:只需要基于xpath进行解析 且提交管道进行持久化存储
??????? - 图片类型:我们只可以通过xpath解析图片src的属性值.单独的对图片地址发起请求获取图片二进制类型的数据
??? - ImagesPipeline :
??????? - 只需要将img的 属性值 src进行解析,提交给管道,管道就会对图片的src进行请求发送获取图片的二进制类型数据,且还会帮我们持久化存储
??? - 需求: 爬取站长素材中的高清图片
??? - 使用流程:
??????? - 数据解析: 图片的地址
??????? - 将存储图片地址的item提交到制定的管道类
??????? - 在管道文件中制定一个基于ImagesPipeline的一个管道类
??????????? - get_media_resquest()
??????????? _ file_path()
??????????? - item_completed
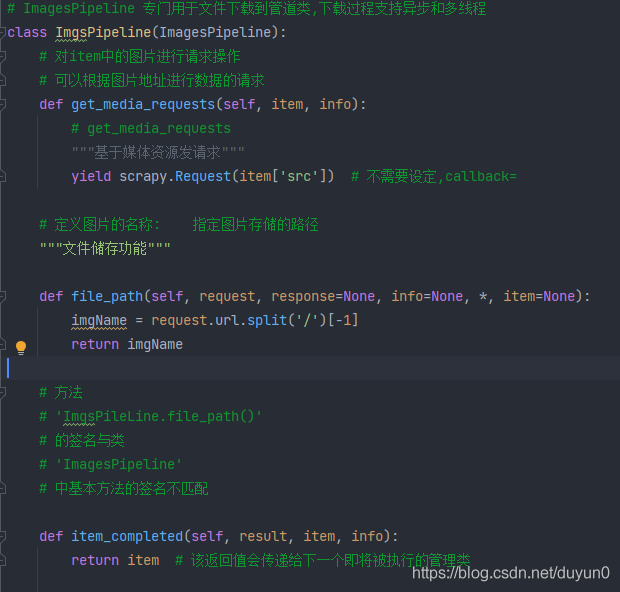
??????? - 在配置文件中操作:
??????????? - 制定图片存放目录: IMAGES_STORE = './img_Jg'
??????????? - 制定开启的管道:自定制的管道类
- 中间件:--->引擎和下载器之间:? middlewares(中间件py文件)
??????????????? - 位置: 下载中间件
??????????????? - 作用: 批量拦截到整个工程中所有的请求和对象
??????????????? - 拦截请求:
??????????????????? - 进行UA伪装(与配置文件中的不同):写在:process_request
??????????????????? - 代理ip的设定? :写在:process_exception :return request
??????????????? - 拦截响应:
??????????????????? - 篡改响应数据,响应对象
??????????????????? - 需求: 爬取网易新闻中的新闻数据(爬取新闻的标题和新闻的内容)
??????????????????? = 1.通过网易新闻的首页解析出五大板块对应的详情页的url (没有动态加载)
??????????????????? - 2.每一个板块对应的新闻标题都是动态加载出来的(动态加载)
??????????????????? - 3.通过解析出每一条新闻详情页的url获取详情页的页面源码,解析出新闻内容
??????? --->引擎和spider之间:爬虫中间件(应用场景太少)
- CrawlSpider:类,Spider的子类 继承父类所有的功能并且派生出自己的功能
??????? - 全站数据爬取的方式:
??????????? - spider:手动请求发送
??????????? - 基于CrawlSpider:已经封装好全站爬取的包
??? - CrawlSpider的具体使用:
??????? - 创建一个工程:
??????? - 创建的爬虫文件(CrawlSpider):
??????????? 创建指令: - scrapy genspider -t crawl 名称? 加url? 例如:sunPro>scrapy genspider -t crawl sun www.xxx.com
???????????? - 链接提取器:
???????????????????? - 作用:根据指定的规则(allow=r'正则表达式')进行连接的提取
???????????? - 规则解析器:
???????????????????? - 作用: 将链接提取器取到的链接进行指定规则(callback='parse_item')的解析

??????????? - 需求 :
??????????????? - 爬取sun网站中的编号、新闻标题、新闻的内容、编号
??????????????? - 分析: 爬取的数据不在同一张页面中。
??????????????? - 1.使用链接提取器提取出页面所有链接
??????????????? - 2.让链接提取器提取详情页的链接? (用两次)
cs