当前位置 博文首页 > xpj8888的博客:第二周 机器学习(ML)策略(2):2.8 多任务学
xpj8888的博客:第二周 机器学习(ML)策略(2):2.8 多任务学
作者:[db:作者]
时间:2021-08-23 19:12
?
目录
?
第一章、简介
第二章、多任务学习
2.1、多任务学习的定义
2.2、汽车图片识别(多任务学习的举例)
2.3、多任务学习的意义
2.4、任务学习更有意义的场合
2.5、小结
第一章、简介
?
- 本文基于吴恩达人工智能课程做学习笔记、并融入自己的见解(若打不开请复制到浏览器中打开)https://study.163.com/courses-search?keyword=吴恩达。
- 本文第二章将介绍 多任务学习的定义、多任务学习的举例、多任务学习的意义等等。
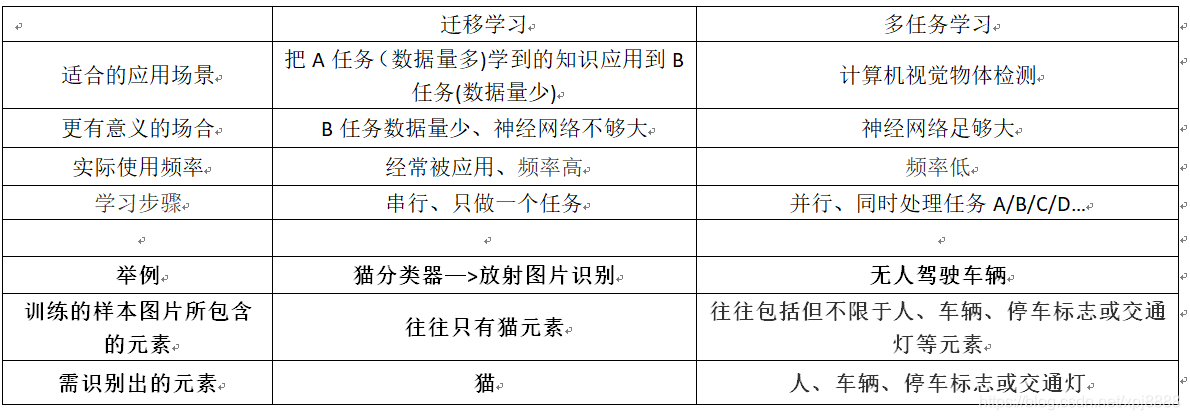
- 对本文的总结:
第二章、多任务学习
?
2.1、多任务学习的定义
?
- 在迁移学习中,你的学习步骤是串行的,因为你从任务A 里学到低层次特征之后,然后才应用迁移到任务B。
- 在多任务学习中,你是同时开始学习的,试图让单个神经网络同时做几件事情,然后希望这里每个任务都能帮到其他所有任务。
?
2.2、汽车图片识别(多任务学习的举例)
?
- 我们来看一个例子,假设你在研发无人驾驶车辆,那么你的无人驾驶车可能需要同时检测不同的物体,比如检测行人、车辆、停车标志、交通灯以及各种其他东西。
- 比如在左边这个例子中,图像里有个停车标志,然后图像中有辆车,但没有行人也没有交通灯。
- 如果这是输入图像
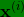 (如图2-1的A所示),那么这里不再是一个标签
(如图2-1的A所示),那么这里不再是一个标签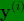 ,而是有 4 个标签(如图2-1的B所示),在这个例子中没有行人、有一辆车、有一个停车标志、没有交通灯,然后如果你尝试检测其他物体,也许的维数会更高,现在我们就先用 4个吧,所以是个?4?1的向量(这4个输出分别对应了人、车辆、停车标志或交通灯)。
,而是有 4 个标签(如图2-1的B所示),在这个例子中没有行人、有一辆车、有一个停车标志、没有交通灯,然后如果你尝试检测其他物体,也许的维数会更高,现在我们就先用 4个吧,所以是个?4?1的向量(这4个输出分别对应了人、车辆、停车标志或交通灯)。 - 如果你从整体来看这个训练集标签,和以前类似,我们将训练集的标签水平堆叠起来,像这样
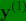 一直到
一直到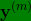 (如图2-1的C所示),不过现在是4?1向量,所以这些都是竖向的列向量,所以这个矩阵Y现在变成?4?m矩阵
(如图2-1的C所示),不过现在是4?1向量,所以这些都是竖向的列向量,所以这个矩阵Y现在变成?4?m矩阵![\mathbf{Y}=\left [ \mathbf{y}^{(1)} \mathbf{y}^{(2)}\cdots \mathbf{y}^{(m)}\right ]](http://style.iis7.com/uploads/2021/08/18521639038.gif)
?
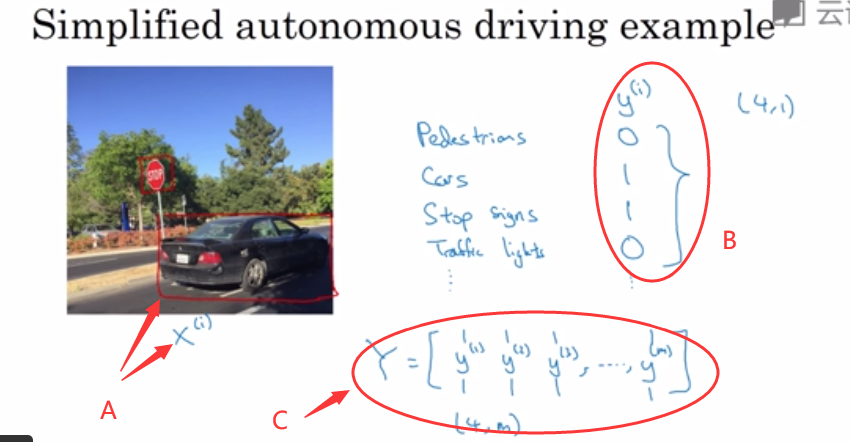
图 2-1
?
- 那么你现在可以做的是训练一个神经网络来预测这些
 ?值,你就得到这样的神经网络,输入x输出是一个四维向量?
?值,你就得到这样的神经网络,输入x输出是一个四维向量? 。
。 - 请注意,这里输出我画了四个输出节点(如图2-2所示),所以第一个节点就是我们想预测图中有没有行人,第二个输出节点预测的是有没有车,第三个节点预测有没有停车标志,第四个节点预测有没有交通灯,所以这里是四维的。
- 要训练这个神经网络,你现在需要定义神经网络的损失函数,对于一个输出是个4维向量,对于整个训练集的平均损失,就是
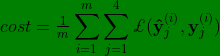 ?其中,从1到m就是表示输入样本序列,从 j=1 到 4 求和表示单个预测(即某个样本)的损失,所以这就是对行人、车、停车标志、交通灯四个分量的求和,而这个标志
?其中,从1到m就是表示输入样本序列,从 j=1 到 4 求和表示单个预测(即某个样本)的损失,所以这就是对行人、车、停车标志、交通灯四个分量的求和,而这个标志 ?指的是 logistic 损失,把它展开之后表达式为
?指的是 logistic 损失,把它展开之后表达式为![\bg_green \bg_green cost = \tfrac{1}{m} \sum_{i=1}^{m} \sum_{j=1}^{4} \pounds(\mathbf{\hat{y}}_{j}^{(i)},\mathbf{y}_{j}^{(i)}) = \tfrac{1}{m} \sum_{i=1}^{m} \sum_{j=1}^{4} [-\mathbf{y}_{j}^{(i)}*log(\mathbf{\hat{y}}_{j}^{(i)}) - (1-\mathbf{?{y}}_{j}^{(i)}) * log(1-\mathbf{\hat{y}}_{j}^{(i)})]](http://style.iis7.com/uploads/2021/08/18522139044.gif) 。
。
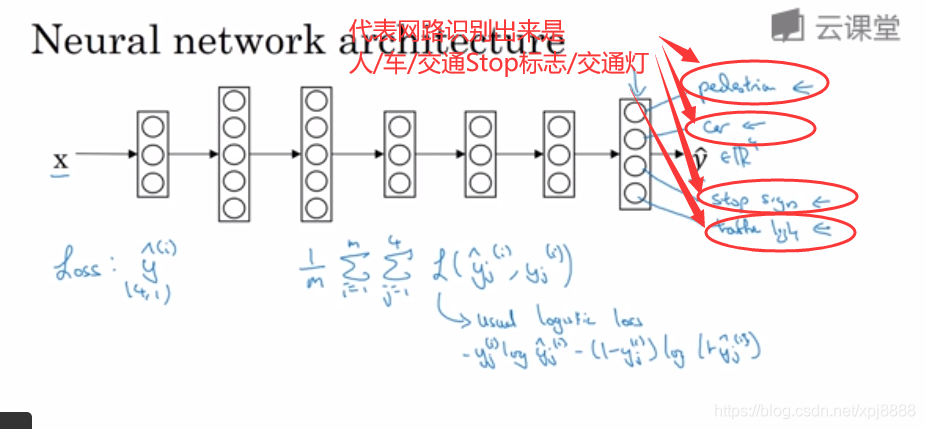
图2-2
- 和之前分类猫的例子主要区别在于,现在你要对 j=1 到 4 求和。
- 这与 softmax 回归的主要区别在于,softmax 将单个标签分配给单个样本,而这张图可以有很多不同的标签,所以不是说每张图都只是一张行人图片,或每张图都只是有一个汽车图片,或每张图都只是有一个,或每张图都只是有一个交通灯图片。
- 你要知道每张照片是否有行人、汽车、停车标志或交通灯,多个物体可能同时出现在一张图里。
- 实际上,在上一张幻灯片中,那张图特征是同时有车和停车标志,但没有行人和交通灯。所以,你不是只给图片一个标签,而是需要遍历不同类型,然后看看每个类型,看看哪类物体有没有出现在图中,所以我就说在这个场合,一张图可以有多个标签。
- 如果你训练了一个神经网络,试图最小化这个成本函数,你做的就是多任务学习,因为你现在做的是建立单个神经网络,观察每张图,然后解决四个问题,系统试图告诉你 每张图里面有没有人、汽车、停车标志或交通灯这四个物体。
- 另外,你也可以训练四个不同的神经网络,而不是训练一个网络做四件事情,但神经网络一些早期特征,在识别不同物体时都会用到。然后你发现,训练一个神经网络做四件事情,会比训练四个完全独立的神经网络分别做四件事性能要更好,这就是多任务学习的力量。
- 另一个细节,到目前为止我是这么描述算法的,好像每张图都有全部标签,事实证明多任务学习,也可以处理图像只有部分物体被标记的情况。
- 假如人工对训练的样本最标记,标记某张图片是否有人/车/stop标志/交通等等。假如第一个训练样本里面有一个行人,但他们没有标记是否有停车标志或是否有车,或者是否有交通灯;也许第二个例子中,标记有行人和有车,但没有标记是否有停车标志,也没有标记是否有交通灯等等。也许有些样本都有标记,但也许有些样本,他们只标记了有没有车,然后还有一些是问号(如图2-3所示),即使是这样的数据集,你也可以在上面训练算法同时做四个任务,即使一些图像,只有一小部分标签,其他是问号或者不管是什么。
- 然后你训练算法的方式,即使这里有些标签是问号或者没有标记,这就是对 j 从 1 到 4 求和,你就只对带 0 和 1 标签的j值求和即可。所以当有问号的时候,你就在求和时忽略那个项,这样只对有标签的值求和,于是你就能利用这样的数据集。
?
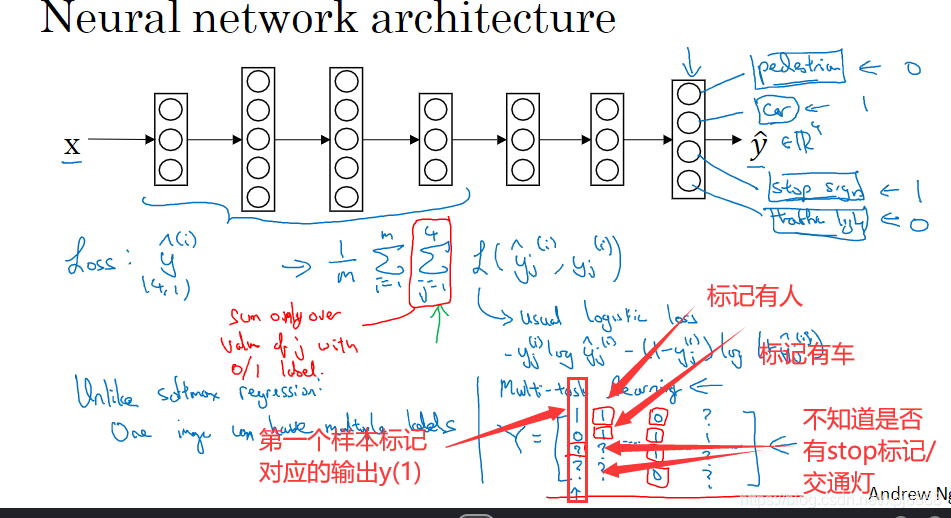
图2-3
?
?
2.3、多任务学习的意义
- 那么多任务学习什么时候有意义呢?当三件事为真时,它就是有意义的。
- 第一,如果你训练的一组任务,可以共用低层次特征,对于无人驾驶的例子,同时识别交通灯、汽车和行人是有道理的,这些物体有相似的特征,也许能帮你识别停车标志,因为这些都是道路上的特征。
- 第二,这个准则没有那么绝对,所以不一定是对的,但我从很多成功的多任务学习案例中看到,如果每个任务的数据量很接近,你还记得迁移学习时,你从A 任务学到知识然后迁移到B任务。如果任务 A 有 1 百万个样本,任务 B 只有 1000 个样本,那么你从这 1 百万个样本学到的知识,真的可以帮你增强对更小数据集任务 B 的训练。
- 那么多任务学习又怎么样呢?在多任务学习中,你通常有更多任务而不仅仅是两个,所以也许你有以前我们的4个任务,但比如说你要完成 100 个任务,而你要做多任务学习,尝试同时识别 100 种不同类型的物体,你可能会发现每个任务大概有 1000 个样本,所以如果你专注加强单个任务的性能,比如我们专注加强第 100 个任务的表现,我们用 A100表示。
- 如果你试图单独去做这个最后的任务,你只有 1000 个样本去训练这个任务,这是 100 项任务之一,而通过在其他 99 项任务的训练,这些加起来可以一共有99000个样本,这可能大幅提升算法性能,可以提供很多知识来增强这个任务的性能,不然对于任务 A100只有 1000 个样本的训练集,效果可能会很差。
- 如果有对称性,这其他 99 个任务也许能提供一些数据,或提供一些知识,来帮到这 100 个任务中的每一个任务。
- 第二点不是绝对正确的准则,但我通常会看的是,如果你专注于单项任务,如果想要从多任务学习得到很大性能提升,那么其他任务加起来,必须要有比单个任务大得多的数据量。要满足这个条件其中一种方法是,让每个任务中的数据量很相近。
- 但关键在于,如果对于单个任务你已经有 1000 个样本了,那么对于所有其他任务,你最好有超过 1000 个样本,这样其他任务的知识才能帮你改善这个任务的性能。
?
2.4、任务学习更有意义的场合
- 最后多任务学习往往在以下场合更有意义――当你可以训练一个足够大的神经网络,同时做好所有的工作,这样的场景更有意义。
- 多任务学习的替代方法是,为每个任务训练一个单独的神经网络,即不是训练单个神经网络同时处理行人 汽车 停车标志和,交通灯检测。你可以训练,一个用于行人检测的神经网络,一个用于汽车检测的神经网络,一个用于停车标志检测的神经网络,和一个用于交通信号灯检测的神经网络(神经网络不够大是,可以试试替代方法,因为这种方法适合单个任务)。
- 那么研究员 Rich Carona 几年前发现的是什么呢?多任务学习会降低性能的唯一情况,和训练单个神经网络相比性能更低的情况,就是你的神经网络还不够大。
- 但如果你可以训练一个足够大的神经网络,那么多任务学习肯定不会或者很少会降低性能,我们都希望它可以提升性能,比单独训练神经网络来单独完成各个任务性能要更好,所以这就是多任务学习(网络足够大,建议用多任务学习)。
- 在实践中 多任务学习的使用频率要低于迁移学习,我看到很多迁移学习的应用――即你需要解决一个问题,但你的训练数据很少,可以考虑用迁移学习。所以你需要找一个数据很多的相关问题来预先学习,并将知识迁移到这个新问题上。
- 但多任务学习比较少见,就是你需要同时处理很多任务都要做好,你可以同时训练所有这些任务,也许计算机视觉是一个例子,在物体检测中我们看到更多使用多任务学习的应用,其中一个神经网络尝试检测一大堆物体,比分别训练不同的神经网络检测物体更好,但平均来说,目前迁移学习使用频率更高,比多任务学习频率要高,但两者都可以成为你的强力工具。
2.5、小结
- 所以总结一下,多任务学习能让你训练一个神经网络来执行多任务,这可以给你更高的性能,比单独完成各个任务更高的性能。
- 但要注意,实际上迁移学习比多任务学习使用频率更高,我看到很多任务都是用迁移学习。
- 如果你想解决一个机器学习问题,但你的数据集相对较小,那么迁移学习真的能帮到你,就是如果你找到一个相关问题,其中数据量要大得多,你就能以它为基础训练你的神经网络,然后迁移到这个数据量很少的任务上来。
- 今天我们学到了很多和迁移学习有关的问题,还有一些迁移学习和多任务学习的应用,但多任务学习我觉得使用频率比迁移学习要少得多,也许其中一个例外是计算机视觉物体检测,在那些任务中,人们经常训练一个神经网络同时检测很多不同物体,这比训练单独的神经网络,来检测视觉物体要更好。
- 但平均而言,我认为即使迁移学习和多任务学习工作方式类似。
- 实际上,我看到用迁移学习比多任务学习要更多,我觉得这是因为你很难找到那么多相似且数据量对等的任务可以用单一神经网络训练。
- 再次,在计算机视觉领域,物体检测这个例子是最显著的例外情况,所以这就是多任务学习。
- 多任务学习和迁移学习,都是你的工具包中的重要工具。
- 最后,我想继续讨论端到端深度学习,所以我们来看下一个视频来讨论端到端学习。
cs