?? 大家好,由于前天熬夜写完第一篇博客,然后昨天又是没休息好,昨天也就不想更新博客,就只是看了会资料就早点休息了,今天补上我这两天的所学,先记录一笔。我发现有时候我看的话会比较敷衍,而如果我写出来(无论写到笔记本中还是博客中,我都有不同的感觉)就会有不同的想法,我看书或者看资料有时候感觉就是有一种惰性,得过且过的感觉,有时候一个知识想不通道不明,想了一会儿,就会找借口给自己说这个知识不重要,不需要太纠结了,还是去看下一个吧,然后就如此往复下去,学习就会有漏洞,所以这更加坚定了我写博客来记录的想法。
???上一篇博客我记录了python的相关基础编程知识,包括数据类型啊,变量啊,正则表达式啊等等,感觉这些基础也没什么好说的,所以说我写的也不是很详细,最近两天我写了个小爬虫并且接触了python的oop编程,感觉今天还是有很多写的,首先这个小爬虫算是对正则表达式的一个小应用,爬虫的基本原理我感觉就是用python中的库或者第三方库的先抓取网页源代码,解析出地址,然后在解析出的地址中用正则表达式筛选出我们想要的内容,比如我写的就是一个简单的抓取网页的图片信息。
一:爬虫
?? 写爬虫的话刚开始要先清楚步骤,然后把思维逻辑理清楚,再来写代码,感觉最后写代码只是思维的映射,最主要还是自己先搞清楚逻辑,闲话少说,接下来我们就进入正题。我在网上看到的一个csdn大牛的写爬虫心得是这样讲的,一段自动抓取互联网信息的程序称为爬虫,主要组成:爬虫调度器、URL管理器、网页下载器、网页解析器
(1)爬虫调度器:程序的入口,主要负责爬虫程序的控制
(2)URL管理器: 1、添加新的URL到代爬取集合
??????????????????????????????? 2、判断待添加URL是否已存在
??????????????????????????????? 3、判断是否还有待爬取的URL,将URL从待爬取集合移动到已爬取集合
??????????????????????????????? URL存储方式:Python内存即set()集合,关系数据库、缓存数据库
(3)网页下载器:根据URL获取网页内容,实现由有urllib2和request
(4)网页解析器:从网页中提取出有价值的数据,实现方法有:正则表达式、html.parser、BeautifulSoup、lxml等等
当然此处说的这么多点我下面的那个小爬虫没有涉及那么多或者说是我的没有大牛这么规范,我刚开始的思路是这样的:首先我想到要用正则表达式筛选我要的信息,所以刚开始肯定要调用模块re,然后获取网页信息我们需要一个urllib模块(我这里写的是一个python2的爬虫,用的是urllib),然后我的主体模块是函数式写法(后面才慢慢来oop),首先我先写一个网页获取函数,当然也需要先给一个网页地址变量,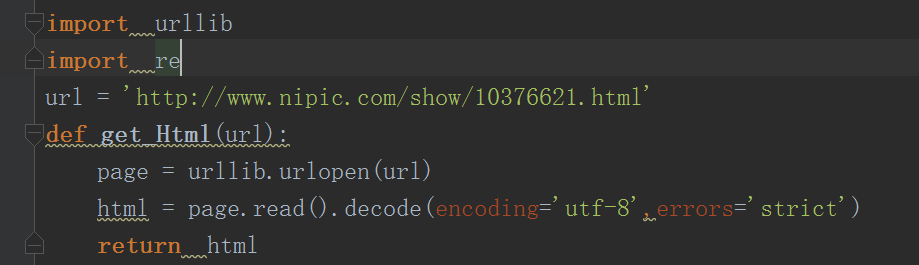
此处就是爬虫的一部分,上面两个是两个模块,下面url变量是网页地址变量,我是随便打开的一个网页取的地址,此处大家可以随意发挥,然后下面就是网页获取函数,这个函数有一个参数,就是url,网页地址,然后第一句就是调用urllib的一个函数urlopen打开这个网页并且存储在变量page中,然后下面就是一个文件读取操作,page(相当于文件名).read(文件读取函数,读取文件中的数据).decode(读取的格式转换),此处是转换成utf-8,至于utf-8格式,我还是百度一下翻译内容吧
大致也就是转换能够适合人懂的格式吧,然后用这个文件操作获取到整个网页的信息了之后就把信息存储到变量html中,最后将获取到的信息返回出去。
到此处就相当于简单粗略的将一个网页的信息爬取出来了,这其实也可以算得上是一个爬虫,最原始的爬虫吧,就只有获取整个网页信息的能力,不细分不修改,功能就是获取网页,如果此处print到控制台的话就是一大串html代码,如果没接触过html的,看到这样的信息肯定是有点蒙的,那么接下来我们就要进行下一个函数(对网页信息进行分析并且用正则表达式筛选出我们需要的内容)

?
?这个函数就是将获取到的html源码进行解析并且用正则表达式筛选出我们需要的,此处我们需要获取整个网页的图片,那么我们就先定义一个正则表达式,格式一般是变量名=r'正则表达式',此处我是需要取到图片,所以我就先写.gif(此处最开始我写的是jpg,一直没发现,后来试了好久,改了好久才发现是gif,简直就很难受啊,哎,感觉如果学习的时候有个人在一旁指导那该是多么幸福的事,不过感觉自学的感觉更爽,自己掉过的每一个坑都是自己人生当中的一大笔财富)至于为什么是用gif格式呢,目前我也不太清楚,还是希望各位园里大佬多多指教,小白洗耳恭听,我们要匹配到后缀都是gif的话那就是要用到\符号,这个符号我上一篇说到了,是将所有字符转换为普通字符,然后搜索时就会按照.gif找,然后前面匹配名字的话我用的是.+?意思也就是匹配所有名字,意思就是匹配所有后缀是.gif格式的文件,前面名称可以随意,但是最少要出现一次,此处也可以将+换成*,那样就是名称最少出现一次,前面src=就是html代码中的地址声明格式之类的,了解html的都清楚每个图片标签语句都要用src=图片路径来将图片放置在网页里面,此处我们就将筛选条件写好了,下面我们就用re里面的一个编译函数编译一下,re.compile()就是编译这个正则表达式,意思就是将正则表达式编译进代码,到后面调用筛选时更快,然后就是findall()函数,贪婪搜索,用来在html代码中搜索出所有符合我们定义条件的内容,到此我们就算是将整个网页分析抓取筛选工作搞完了,简单吧,我觉得刚开始可能有点难理解,但是仔细一想还是挺简单的,主要是把这种流程想清楚,抓取到了我们想要的内容之后接下来我们就要将其保存起来,下面就是用一个for循环将将我们筛选到的内容保存,此处我们又要用到一个urllib里面的函数urlretrieve,这个函数就是将内容保存到本地,默认是保存到项目下,当然此处还是可以放到另外的部分,不过我没有尝试,最下面还有两个语句搞忘记说了
也就是用这个两个函数,没什么说的,到此小爬虫就完了,此处我用的是python2.7.
二:文件操作
???? 文件操作这块的话感觉有点像c语言的文件操作,但是感觉还是最开始那种思想,python写法永远比c语言简单。
深拷贝和浅拷贝:此处两个定义大致可以这么理解,浅拷贝是对引用的拷贝,深拷贝是对对象资源的拷贝,浅拷贝是不完全独立于之前的“父亲”,深拷贝则是完全脱离,不管之后父文件有什么改变,子文件都不会随之改变,说到此处肯定有一些跟我一样的小白不太懂,还是上代码截图比较明了,
?
大致就是上面这样,小白弄得有点乱,不好意思各位了,这是浅拷贝,深拷贝就是父文件怎么变,子文件都不会变。
接下来就是文件读写部分了:
文件打开函数就是open或者也可以用file类,一般来说我还是比较喜欢用open,此处也就只记录open算了(深夜感觉想睡觉,哈哈,偷个懒),open(filename,mode),大致就是这两个参数,第一个不用就是文件名,第二个就是打开模式,大致就是如下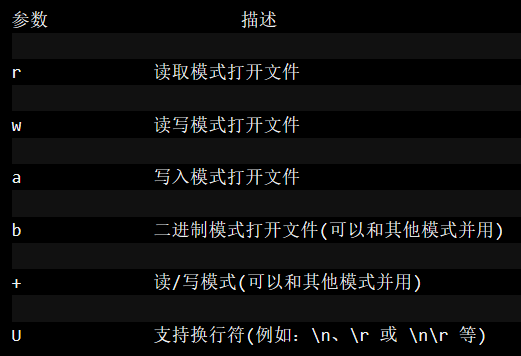
这些大致就是mode的种类,当然此处说出来还是挺简单的,还是要具体自己使用的时候慢慢体会其中的韵味,其中还有一些文件操作的函数我也就一一列举出来



上面就是在找的比较全的文件操作的方法,当然如果要真正掌握这些还是要结合具体慢慢用,实践才是唯一真理,我此处也是为了早点上床睡觉偷懒而为,希望各位不要喷我。我就举个例子来简单说下一些注意事项,open方法可以返回一个迭代数据,然后write和writelines在写入前是否清除文件中的原来的数据,取决于模式,一般w模式就是清除原来的数据,还有seek(偏移量,选项)选项为0时,表示将指针指向从文件头部到偏移量的字节处,选项等于1时,表示将文件指针指向从文件当前位置,向后移动偏移量字节,选项为2时,表示将文件指针指向从文件尾部,向前移动偏移量字节。下面举一两个小例子解释一下文件操作吧。
第一个小例子是将文件一的数据“hello”拷贝到文件二中:
?? 新建了两个文本,一个1.txt,里面有一些数据,其中有几个hello,2.txt中有几个lixun,我们就将一中的hello拷贝到2.txt文件中替换掉lixun,代码如下
???? fp1 = file(“1.txt”,"r")
???? fp2 = file("2.txt","w")
???? for s in fp1.readlines():
????????????? fp2.write(s.replace("hello","lixun"))
?? fp1.close()
? fp2.close()
至此就完成了操作,
我们将第一个例子升级一下,将1.txt中的hello换成lixun
fp1 = file(“1.txt”,“r+”)
s??? =?fp1.read()
fp1.seek(0,0)
fp1.write(s.replace("lixun","hello"))
fp1.close
接下来就是socket编程了:
socket网络通信我也是在网上找的资料慢慢看,然后按照一些大佬写的代码参悟,
主要思想也是调用模块(socket)然后就是分服务器端程序跟客户端程序,其实说起来高大上,真正搞懂了也就是一个通信模式,就跟单片机中的通信模块一样的,
客户端模块代码就是import socket
s=socket.socket()
host=socket.gethostname()
port=1234
s.bind((host,port))
s.listen(5)
while True:
??? s,addr=s.accept()
??? print ("Got connect from %s:%s" % addr)
??? s.send("Thank you for connecting")
??? s.close()
服务器端模块:
import socket
s=socket.socket()
host=socket.gethostname()
port=1234
s.connect((host,port))
print s.recv(1024)
这大致就是一个简单的socket通信编程,也就相当于两台机器之间的通信,具体代码也比较简单,也就不细讲了
接下来再放一个我理解了的socket的代码吧
客户端:
import socket
import sys
#创建socket函数
try:
s = socket.socket(socket.AF_INET,socket.sock_STREAM)
except socket.error,msg:
print 'Falied to create socket.Error code:'+str(msg[0])+',Error message:'+msg[1]
sys.exit();
print 'Socket Created'
#连接服务器
host = 'www.google.com'
port = 80
try:
remote_ip = socket.gethostbyname(host)
except socket.gaierror:
print 'Hostname could not be resolved.Exiting'
sys.exit()
print 'Ip address of'+host+'is'+remote_ip
#连接到服务器
s.connect((remote_ip,port))
print 'Socket Connected to'+host+'on ip'+remote_ip
#发送数据到服务器
message = "GET / HTTP/1.1\r\n\r\n"
try:
s.sendall(message)
except socket.error:
print 'Send failed'
sys.exit()
print 'Message send successfully'
#接收数据
reply = s.recv(4096)
print reply
s.close()
服务器端:
#绑定socket
import socket
import sys
from thread import *
HOST = ''
PORT = 8888
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
print 'Socket created'
try:
s.bind((HOST,PORT))
except socket.error,msg:
print 'Bind failed.Error Code:'+str(msg[0])+'Message'+msg[1]
sys.exit()
print 'Socket bind complete'
#监听连接
s.listen(10)
print 'Socket now listening'
def clientthread(conn):
conn.send('Welcome to the sever.Type something and hit enter\n')
while True:
data= conn.recv(1024)
reply = 'OK...'+data
if not data:
break
conn.sendall(reply)
conn.close()
while 1:
conn,addr = s.accept()
print 'Connected with'+addr[0]+':'+str(addr[1])
start_new_thread(clientthread,(conn,))
s.close()
这里面新知识可能就是那个线程问题,有过一些代码基础的同学应该对线程概念不陌生。这一块我也只是了解了一下,因为下个月二十几号就要用socket通信,所以也就没时间深究其原理及其细节
下面就是oop编程了
四:oop编程
oop编程是我要在choregraphe软件里面写盒子要用到的部分,所以这部分我还是打算慢慢来搞,,感觉python的oop写法还是跟c++和c#有所不同,至少c#里面我还没遇到过要用什么self,可能我学
不深吧,有些奥义还没有接触到,各位大佬莫怪,当然,python的面向对象编程书写起来还是挺方便的,
创建类就是class className():,这样就创建了一个类,跟c#还是挺像的,
,然后里面还可以加'class documentation string'#类文档字符串,然后基本上类里面都会有一个构造函数def _name_(self,canshu1,canshu2):这就大致是构造函数的写法,函数名称必须是
——_name_中间是名称,开始和结尾都必须有_下划线,括号中的参数,最开始必须是self,至于为什么,我目前尚未究其缘由,刚刚写着的时候突然发现自己还是没太明白其中奥义,所以感觉今天还是先别说,留着
下一篇理解摸清楚了再来细讲吧。
我是小白随风狼人小白,我为自己代言,哈哈,晚安,各位大牛
cs