1. ǰ��
���Ŵ�Ҷ� ZooKeeper Ӧ�ò���İ��������������˽� ZooKeeper ������ɶ�ò�?�������/���Թ���������������� ZooKeeper ����ʶ,���ܻش�ʲô�ز���?
�����Լ���˵��!�ұ�������ʹ�� Dubbo �����ֲ�ʽ��Ŀ��ʱ��,ʹ���� ZooKeeper ��Ϊע�����ġ�Ϊ�˱�֤�ֲ�ʽϵͳ�ܹ�ͬ������ij����Դ,�һ�ʹ�� ZooKeeper �����ֲ�ʽ��������,����ѧϰ Kafka ��ʱ��,֪�� Kafka �ܶ�ܵ�ʵ�������� ZooKeeper��
ǰ����,�ܽ���Ŀ�����ʱ��,��ͻȻ���Լ� ZooKeeper �����Ǹ�ʲô����?���˰���,�Ժ���ֻ�Ǽ��ܸ��ֳ����仰:
- ZooKeeper ���Ա�����ע�����ġ��ֲ�ʽ��;
- ZooKeeper �� Hadoop ��̬ϵͳ��һԱ;
- ���� ZooKeeper ��Ⱥ��ʱ��,ʹ�õķ��������������̨��
�ɴ˿ɼ�,�Ҷ��� ZooKeeper �����������ͣ�����˱��档
����,ͨ������,ϣ�����������ϸ���˽�һ�� ZooKeeper �����û��ѧ�� ZooKeeper ,��ô���Ľ���������� ZooKeeper ���ŵĵ��ש��������Ѿ��Ӵ��� ZooKeeper ,��ô���Ľ�����ع�һ�� ZooKeeper ��һЩ�������
����,���IJ�����漰�� ZooKeeper ��һЩ����,��������»���ܵ� ZooKeeper ���������ʹ���Լ�ʹ�� Apache Curator ��Ϊ ZooKeeper �Ŀͻ��ˡ�
����������κ���Ҫ���ƺ����Ƶĵط�,��ӭ��������ָ��,��ͬ����!
?
�Ƽ��Ķ�
Ϊʲô����ij���Ա�ɳ����֮��?����Alibaba��Java�ɳ��ʼǡ��Ҷ���!_��С�εIJ���-CSDN����?blog.csdn.net
2020����35K��н��MySQL���Աʼǽ���:����+�Ż�+��+����ѯ+����
�Ƽ��ۿ�
���������⼯���:��������+��Ѷ����+֧��������+ƴ������+�ֽ�����+�Ա�����_�������� (�b-�b)�ĥ� �ɱ�~-bilibili?www.bilibili.com
?
������!Bվ��ȫ����ײ����:TCP��Sockt���������֡��Ĵλ��֡�NIO��Epoll����·����(����Դ�롢��ͼ)?www.bilibili.com
?
��������ܹ�ʦ�����ϸ����springԴ��(�����������Ϻ�Դ��)?www.bilibili.com
?
Java�ܹ�ʦ�ػ��������֪ʶ��:���̡߳�JVM�����ģʽ��MySQL��Redis��ZooKeeper?www.bilibili.com
?
���δ������ȫ�°汾!Tomcat��TCP/IP��IO���ֲ�ʽ����ܹ�ȫ��?www.bilibili.com
2. ZooKeeper ����
2.1. ZooKeeper ����
��ʽ���� ZooKeeper ֮ǰ,������������ ZooKeeper ������,��ͦ����˼�ġ�
�����������ժ�ԡ��� Paxos �� ZooKeeper �������µ�һ��,�Ƽ�����Ķ�һ��:
ZooKeeper ������Դ���Ż��о�Ժ��һ���о�С�顣�ڵ�ʱ,�о���Ա����,���Ż��ڲ��ܶ����ϵͳ��������Ҫ����һ�����Ƶ�ϵͳ�����зֲ�ʽЭ��,������Щϵͳ���������ڷֲ�ʽ�������⡣����,�Ż��Ŀ�����Ա����ͼ����һ��ͨ�õ���������ķֲ�ʽЭ�����,�Ա��ÿ�����Ա�����������ڴ���ҵ�����ϡ�
���ڡ�ZooKeeper�������Ŀ������,��ʵҲ��һ��Ȥ�š����������,���ǵ�֮ǰ�ڲ��ܶ���Ŀ����ʹ�ö����������������(���������� Pig ��Ŀ),�Ż��Ĺ���ʦϣ���������ĿҲȡһ����������֡�ʱ���о�Ժ����ϯ��ѧ�� RaghuRamakrishnan ����Ц��˵:����������ȥ,��������ͱ�ɶ�����!���˻�һ��,��ҷױ�ʾ�ͽж�������Ա��һһһ��Ϊ�����Զ��������ķֲ�ʽ�������һ��,�Ż��������ֲ�ʽϵͳ����ȥ����һ�����͵Ķ�����,�� ZooKeeper ����Ҫ�������зֲ�ʽ������Э��һһ����,ZooKeeper ������Ҳ���ɴ˵����ˡ�
2.2. ZooKeeper ����
ZooKeeper ��һ����Դ���ֲ�ʽЭ������,�������Ŀ���ǽ���Щ���������׳����ķֲ�ʽһ���Է����װ����,����һ����Ч�ɿ���ԭ�O,����һϵ�м����õĽӿ��ṩ���û�ʹ�á�
ԭ��:?����ϵͳ�������������ﷶ�롣����������ָ����ɵ�,�������һ�����ܵ�һ�����̡����в��ɷָ��ԡ���ԭ���ִ�б�����������,��ִ�й����в��������жϡ�
ZooKeeper Ϊ�����ṩ�˸߿��á������ܡ��ȶ��ķֲ�ʽ����һ���Խ������,ͨ��������ʵ���������ݷ���/���ġ����ؾ��⡢�������ֲ�ʽЭ��/֪ͨ����Ⱥ������Master ѡ�١��ֲ�ʽ���ͷֲ�ʽ���еȹ��ܡ�
����,ZooKeeper �����ݱ������ڴ���,�����Ƿdz����ġ� �ڡ��������ڡ�д����Ӧ�ó���������ظ�����,��Ϊ��д���ᵼ�����еķ�������ͬ��״̬��(���������ڡ�д����Э������ĵ��ͳ���)��
2.3. ZooKeeper �ص�
- ˳��һ����: ��ͬһ�ͻ��˷������������,���ս����ϸ�ذ���˳��Ӧ�õ� ZooKeeper ��ȥ��
- ԭ����:?������������Ĵ��������������Ⱥ�����л����ϵ�Ӧ�������һ�µ�,Ҳ����˵,Ҫô������Ⱥ�����еĻ������ɹ�Ӧ����ijһ������,Ҫô��û��Ӧ�á�
- ��һϵͳӳ��?:?���ۿͻ���������һ�� ZooKeeper ��������,�俴���ķ��������ģ�Ͷ���һ�µġ�
- �ɿ���: һ��һ�θ�������Ӧ��,���ĵĽ���ͻᱻ�־û�,ֱ������һ�θ��ĸ��ǡ�
2.4. ZooKeeper ����Ӧ�ó���
ZooKeeper ������,���ǽ��ܵ�ʹ����ͨ��������ʵ���������ݷ���/���ġ����ؾ��⡢�������ֲ�ʽЭ��/֪ͨ����Ⱥ������Master ѡ�١��ֲ�ʽ���ͷֲ�ʽ���еȹ��ܡ�
����ѡ 3 �����͵�Ӧ�ó�����ר��˵˵:
- �ֲ�ʽ�� : ͨ������Ψһ�ڵ��÷ֲ�ʽ��,���������һ��ִ������ش�������ǹҵ�֮����ͷ�����
- �������� :����ͨ�� ZooKeeper ��˳��ڵ�����ȫ��Ψһ ID
- ���ݷ���/���� :ͨ��?Watcher ����?���Ժܷ����ʵ�����ݷ���/���ġ����㽫���ݷ����� ZooKeeper �������Ľڵ���,����������ͨ������ ZooKeeper �Ͻڵ�ı仯��ʵ�����õĶ�̬���¡�
ʵ����,��Щ���ܵ�ʵ�ֻ����������� ZooKeeper ���Ա������ݵĹ���,���� ZooKeeper ���ʺϱ����������,��һ����Ҫע�⡣
2.5. ����Щ�����Ŀ�Դ��Ŀ�õ��� ZooKeeper?
- Kafka : ZooKeeper ��ҪΪ Kafka �ṩ Broker �� Topic ��ע���Լ���� Partition �ĸ��ؾ���ȹ��ܡ�
- Hbase : ZooKeeper Ϊ Hbase �ṩȷ��������Ⱥֻ��һ�� Master �Լ�������ṩ regionserver ״̬��Ϣ(�Ƿ�����)�ȹ��ܡ�
- Hadoop : ZooKeeper Ϊ Namenode �ṩ�߿���֧�֡�
3. ZooKeeper ��Ҫ������
����:�ó�С����,��������ݷdz���ҪŶ!
3.1. Data model(����ģ��)
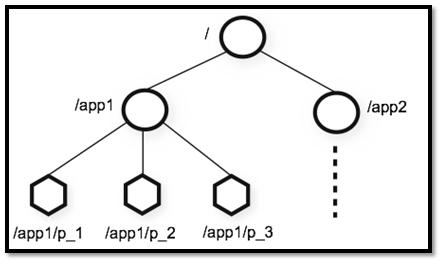
ZooKeeper ����ģ�Ͳ��ò�λ��Ķ�����νṹ,ÿ���ڵ��϶����Դ洢����,��Щ���ݿ��������֡��ַ��������Ƕ��������С����ҡ�ÿ���ڵ㻹����ӵ�� N ���ӽڵ�,���ϲ��Ǹ��ڵ��ԡ�/����������ÿ�����ݽڵ��� ZooKeeper �б���Ϊ?znode,���� ZooKeeper �����ݵ���С��Ԫ������,ÿ�� znode ��һ��Ψһ��·����ʶ��
ǿ��һ��:ZooKeeper ��Ҫ������Э�������,�����������洢ҵ�����ݵ�,���Բ�Ҫ�űȽϴ�������� znode ��,ZooKeeper ������������ÿ���������ݴ�С����� 1M��
����ͼ���Ը�ֱ�۵ؿ���:ZooKeeper �ڵ�·����ʶ��ʽ�� Unix �ļ�ϵͳ·���dz�����,������һϵ��ʹ��б��"/"���зָ��·����ʾ,������Ա����������ڵ���д������,Ҳ�����ڽڵ����洴���ӽڵ㡣��Щ�������Ǻ��涼����ܵ���
?
3.2. znode(���ݽڵ�)
������ ZooKeeper ��������ģ��֮��,����֪��ÿ�����ݽڵ��� ZooKeeper �б���Ϊ?znode,���� ZooKeeper �����ݵ���С��Ԫ����Ҫ��ŵ����ݾͷ�������,����ʹ�� ZooKeeper �����о�����Ҫ�Ӵ�����һ�����
3.2.1. znode 4������
����ͨ���ǽ� znode ��Ϊ 4 ����:
- �־�(PERSISTENT)�ڵ� :һ��������һֱ���ڼ�ʹ ZooKeeper ��Ⱥ崻�,ֱ������ɾ����
- ��ʱ(EPHEMERAL)�ڵ� :��ʱ�ڵ�������������� �ͻ��˻Ự(session) ��,�Ự��ʧ��ڵ���ʧ ������,��ʱ�ڵ�ֻ����Ҷ�ӽڵ� ,���ܴ����ӽڵ㡣
- �־�˳��(PERSISTENT_SEQUENTIAL)�ڵ� :���˾��г־�(PERSISTENT)�ڵ������֮��, �ӽڵ�����ƻ�����˳���ԡ����� /node1/app0000000001 ��/node1/app0000000002 ��
- ��ʱ˳��(EPHEMERAL_SEQUENTIAL)�ڵ� :���˾߱���ʱ(EPHEMERAL)�ڵ������֮��,�ӽڵ�����ƻ�����˳���ԡ�
3.2.2. znode ���ݽṹ
ÿ�� znode �� 2 �������:
- stat :״̬��Ϣ
- data : �ڵ��ŵ����ݵľ�������
������ʾ,��ͨ�� get ��������ȡ ��Ŀ¼�µ� dubbo �ڵ�����ݡ�(get �������������ܵ�)��
[zk: 127.0.0.1:2181(CONNECTED) 6] get /dubbo
# �����ݽڵ��������������Ϊ��
null
# �����Ǹ����ݽڵ��һЩ״̬��Ϣ,��ʵ���� Stat ����ĸ�ʽ�����
cZxid = 0x2
ctime = Tue Nov 27 11:05:34 CST 2018
mZxid = 0x2
mtime = Tue Nov 27 11:05:34 CST 2018
pZxid = 0x3
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
Stat ���а�����һ�����ݽڵ������״̬��Ϣ���ֶ�,�������� ID-cZxid���ڵ㴴��ʱ��-ctime ���ӽڵ����-numChildren �ȵȡ�
������������һ��ÿ�� znode ״̬��Ϣ������������ʲô��!(�����������Դ�ڡ��� Paxos �� ZooKeeper �ֲ�ʽһ����ԭ����ʵ����,��Ϊ Guide ȷʵҲ�����ر����,Ҫѧ��ο����ϵ���! ) :

?
3.3. �汾(version)
��ǰ�������Ѿ��ᵽ,��Ӧ��ÿ�� znode,ZooKeeper ����Ϊ��ά��һ������?Stat?�����ݽṹ,Stat �м�¼����� znode ��������صİ汾:
- dataVersion :��ǰ znode �ڵ�İ汾��
- cversion : ��ǰ znode �ӽڵ�İ汾
- aclVersion : ��ǰ znode �� ACL �İ汾��
3.4. ACL(Ȩ����)
ZooKeeper ���� ACL(AccessControlLists)����������Ȩ����,������ UNIX �ļ�ϵͳ��Ȩ���ơ�
���� znode ������Ȩ��,ZooKeeper �ṩ������ 5 ��:
- CREATE : �ܴ����ӽڵ�
- READ :�ܻ�ȡ�ڵ����ݺ��г����ӽڵ�
- WRITE : ������/���½ڵ�����
- DELETE : ��ɾ���ӽڵ�
- ADMIN : �����ýڵ� ACL ��Ȩ��
����������Ҫע�����,CREATE �� DELETE ������Ȩ������� �ӽڵ� ��Ȩ���ơ�
����������֤,�ṩ�����¼��ַ�ʽ:
- world : Ĭ�Ϸ�ʽ,�����û��������������ʡ�
- auth :��ʹ���κ� id,�����κ�����֤���û���
- digest :�û���:������֤��ʽ:?username:password?��
- ip : ��ָ�� ip �������ơ�
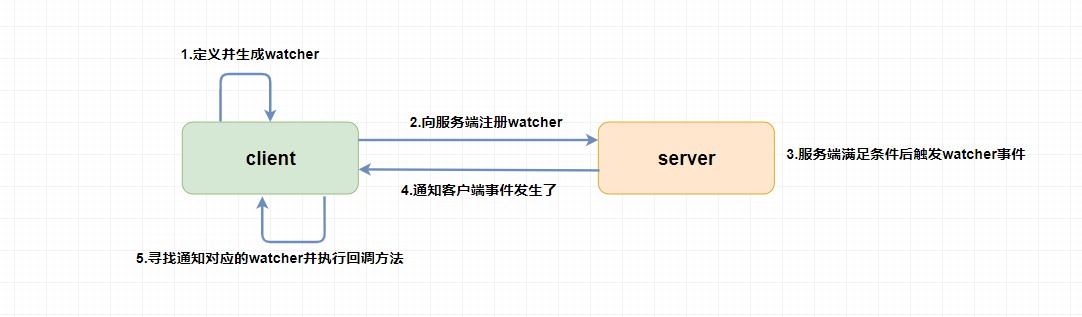
3.5. Watcher(�¼�������)
Watcher(�¼�������),�� ZooKeeper �е�һ������Ҫ�����ԡ�ZooKeeper �����û���ָ���ڵ���ע��һЩ Watcher,������һЩ�ض��¼�������ʱ��,ZooKeeper ����˻Ὣ�¼�֪ͨ������Ȥ�Ŀͻ�����ȥ,�û����� ZooKeeper ʵ�ֲַ�ʽЭ���������Ҫ���ԡ�
?
����:�dz����õ�һ������,���ܳ�С�����Ǻ���,�����õ� ZooKeeper �����벻�� Watcher(�¼�������)���ơ�
3.6. �Ự(Session)
Session ���Կ����� ZooKeeper ��������ͻ��˵�֮���һ�� TCP ������,ͨ���������,�ͻ����ܹ�ͨ����������������������Ч�ĻỰ,Ҳ�ܹ��� ZooKeeper ������������������Ӧ,ͬʱ���ܹ�ͨ�������ӽ������Է������� Watcher �¼�֪ͨ��
Session ��һ�����Խ���:sessionTimeout ,sessionTimeout �����Ự�ij�ʱʱ�䡣�����ڷ�����ѹ��̫��������ϻ��ǿͻ��������Ͽ����ӵȸ���ԭ���¿ͻ������ӶϿ�ʱ,ֻҪ��sessionTimeout�涨��ʱ�����ܹ����������ϼ�Ⱥ������һ̨������,��ô֮ǰ�����ĻỰ��Ȼ��Ч��
����,��Ϊ�ͻ��˴����Ự֮ǰ,��������Ȼ�Ϊÿ���ͻ��˶�����һ�� sessionID������ sessionID�� ZooKeeper �Ự��һ����Ҫ��ʶ,������Ự��ص����л��ƶ��ǻ������ sessionID ��,���,��������̨������Ϊ�ͻ��˷���� sessionID,����ر�֤ȫ��Ψһ��
�Ƽ��Ķ�
Ϊʲô����ij���Ա�ɳ����֮��?����Alibaba��Java�ɳ��ʼǡ��Ҷ���!_��С�εIJ���-CSDN����?blog.csdn.net
2020����35K��н��MySQL���Աʼǽ���:����+�Ż�+��+����ѯ+����
�Ƽ��ۿ�
���������⼯���:��������+��Ѷ����+֧��������+ƴ������+�ֽ�����+�Ա�����_�������� (�b-�b)�ĥ� �ɱ�~-bilibili?www.bilibili.com
?
������!Bվ��ȫ����ײ����:TCP��Sockt���������֡��Ĵλ��֡�NIO��Epoll����·����(����Դ�롢��ͼ)?www.bilibili.com
?
��������ܹ�ʦ�����ϸ����springԴ��(�����������Ϻ�Դ��)?www.bilibili.com
?
Java�ܹ�ʦ�ػ��������֪ʶ��:���̡߳�JVM�����ģʽ��MySQL��Redis��ZooKeeper?www.bilibili.com
?
���δ������ȫ�°汾!Tomcat��TCP/IP��IO���ֲ�ʽ����ܹ�ȫ��?www.bilibili.com
4. ZooKeeper ��Ⱥ
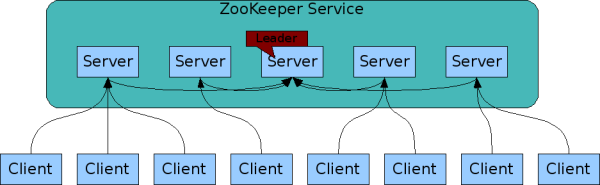
Ϊ�˱�֤�߿���,������Լ�Ⱥ��̬������ ZooKeeper,����ֻҪ��Ⱥ�дֻ����ǿ��õ�(�ܹ�����һ���Ļ�������),��ô ZooKeeper ������Ȼ�ǿ��õġ�ͨ�� 3 ̨�������Ϳ��Թ���һ�� ZooKeeper ��Ⱥ�ˡ�ZooKeeper �ٷ��ṩ�ļܹ�ͼ����һ�� ZooKeeper ��Ⱥ��������ṩ����
?
��ͼ��ÿһ�� Server ����һ����װ ZooKeeper ����ķ���������� ZooKeeper ����ķ������������ڴ���ά����ǰ�ķ�����״̬,����ÿ̨������֮�䶼���ౣ����ͨ�š���Ⱥ��ͨ�� ZAB Э��(ZooKeeper Atomic Broadcast)���������ݵ�һ���ԡ�
����ͼ�Ⱥģʽ: Master/Slave ģʽ(����ģʽ)��������ģʽ��,ͨ�� Master ��������Ϊ���������ṩд����,������ Slave �������ӷ�����ͨ���첽���Ƶķ�ʽ��ȡ Master ���������µ������ṩ������
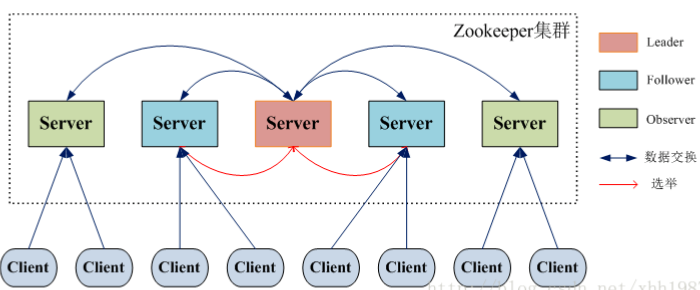
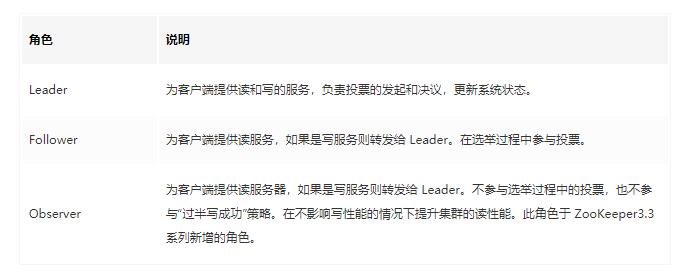
4.1. ZooKeeper ��Ⱥ��ɫ
����,�� ZooKeeper ��û��ѡ��ͳ�� Master/Slave ����,���������� Leader��Follower �� Observer ���ֽ�ɫ������ͼ��ʾ
?
ZooKeeper ��Ⱥ�е����л���ͨ��һ��?Leader ѡ�ٹ���?��ѡ��һ̨��Ϊ ��Leader�� �Ļ���,Leader �ȿ���Ϊ�ͻ����ṩд���������ṩ�������� Leader ��,Follower?��?Observer?��ֻ���ṩ������Follower �� Observer Ψһ���������� Observer ���������� Leader ��ѡ�ٹ���,Ҳ������д�����ġ�����д�ɹ�������,��� Observer ���������ڲ�Ӱ��д���ܵ������������Ⱥ�Ķ����ܡ�
?
�� Leader ���������������жϡ������˳����������쳣���ʱ,�ͻ���� Leader ѡ�ٹ���,������̻�ѡ�ٲ����µ� Leader ��������
������̴�����������:
- Leader election(ѡ�ٽ�):�ڵ���һ��ʼ������ѡ�ٽ�,ֻҪ��һ���ڵ�õ��������ڵ��Ʊ��,���Ϳ��Ե�ѡ leader��
- Discovery(���ֽ�) :�������,followers �� leader ����ͨ��,ͬ�� followers ������յ��������顣
- Synchronization(ͬ����) :ͬ������Ҫ������ leader ǰһ�λ�õ�����������ʷ,ͬ����Ⱥ�����еĸ�����ͬ�����֮�� leader �Ż��Ϊ������ leader��
- Broadcast(�㲥��) :���������,ZooKeeper ��Ⱥ������ʽ�����ṩ�������,���� leader ���Խ�����Ϣ�㲥��ͬʱ������µĽڵ����,����Ҫ���½ڵ����ͬ����
4.2. ZooKeeper ��Ⱥ�еķ�����״̬
- LOOKING :Ѱ�� Leader��
- LEADING :Leader ״̬,��Ӧ�Ľڵ�Ϊ Leader��
- FOLLOWING :Follower ״̬,��Ӧ�Ľڵ�Ϊ Follower��
- OBSERVING :Observer ״̬,��Ӧ�ڵ�Ϊ Observer,�ýڵ㲻���� Leader ѡ�١�
4.3. ZooKeeper ��ȺΪɶ�������̨?
ZooKeeper ��Ⱥ��崵����� ZooKeeper ������֮��,���ʣ�µ� ZooKeeper ��������������崵��ĸ����Ļ����� ZooKeeper ����Ȼ���á��������ǵļ�Ⱥ���� n ̨ ZooKeeper ������,��ôҲ����ʣ�µķ������������ n/2����˵һ�½���,2n �� 2n-1 �����̶���һ����,���� n-1,��ҿ������Լ���ϸ��һ��,��Ӧ����һ���ܼ���ѧ�����ˡ� ������������� 3 ̨,��ô�������崵� 1 ̨ ZooKeeper ������,��������� 4 ̨�ĵ�ʱ��Ҳͬ��ֻ����崵� 1 ̨�� ���������� 5 ̨,��ô�������崵� 2 ̨ ZooKeeper ������,��������� 6 ̨�ĵ�ʱ��Ҳͬ��ֻ����崵� 2 ̨��
����,�α�������һ������Ҫ�� ZooKeeper ��?
5. ZAB Э���Paxos �㷨
Paxos �㷨Ӧ�ÿ���˵�� ZooKeeper ������ˡ�����,ZooKeeper ��û����ȫ���� Paxos�㷨 ,����ʹ�� ZAB Э����Ϊ�䱣֤����һ���Եĺ����㷨������,��ZooKeeper�Ĺٷ��ĵ���Ҳָ��,ZABЭ�鲢���� Paxos �㷨����,��һ��ͨ�õķֲ�ʽһ�����㷨,����һ���ر�ΪZookeeper��Ƶı����ɻָ���ԭ����Ϣ�㲥�㷨��
5.1. ZAB �����
ZAB(ZooKeeper Atomic Broadcast ԭ�ӹ㲥) Э����Ϊ�ֲ�ʽЭ������ ZooKeeper ר����Ƶ�һ��֧�ֱ����ָ���ԭ�ӹ㲥Э�顣 �� ZooKeeper ��,��Ҫ���� ZAB Э����ʵ�ֲַ�ʽ����һ����,���ڸ�Э��,ZooKeeper ʵ����һ������ģʽ��ϵͳ�ܹ������ּ�Ⱥ�и�������֮�������һ���ԡ�
5.2. ZAB Э�����ֻ�����ģʽ:�����ָ�����Ϣ�㲥
ZAB Э��������ֻ�����ģʽ,�ֱ���
- �����ָ� :������������������������,���ǵ� Leader ���������������жϡ������˳����������쳣���ʱ,ZAB Э��ͻ����ָ�ģʽ��ѡ�ٲ����µ�Leader����������ѡ�ٲ������µ� Leader ������,ͬʱ��Ⱥ���Ѿ��й���Ļ������Leader�����������״̬ͬ��֮��,ZABЭ��ͻ��˳��ָ�ģʽ������,��ν��״̬ͬ����ָ����ͬ��,������֤��Ⱥ�д��ڹ���Ļ����ܹ���Leader������������״̬����һ�¡�
- ��Ϣ�㲥 :����Ⱥ���Ѿ��й����Follower����������˺�Leader��������״̬ͬ��,��ô���������ܾͿ��Խ�����Ϣ�㲥ģʽ�ˡ� ��һ̨ͬ������ZABЭ��ķ�������������뵽��Ⱥ��ʱ,�����ʱ��Ⱥ���Ѿ�����һ��Leader�������ڸ��������Ϣ�㲥,��ô�¼���ķ������ͻ��Ծ��ؽ������ݻָ�ģʽ:�ҵ�Leader���ڵķ�����,�������������ͬ��,Ȼ��һ����뵽��Ϣ�㲥������ȥ��
���� ZAB Э��&Paxos�㷨 ��Ҫ��������Ķ���̫����,������Կ���������ƪ����:
- ͼ�� Paxos һ����Э��
- Zookeeper ZAB �����
6. �ܽ�
- ZooKeeper ��������һ���ֲ�ʽ����(ֻҪ�������Ͻڵ���,ZooKeeper ������������)��
- Ϊ�˱�֤�߿���,������Լ�Ⱥ��̬������ ZooKeeper,����ֻҪ��Ⱥ�дֻ����ǿ��õ�(�ܹ�����һ���Ļ�������),��ô ZooKeeper ������Ȼ�ǿ��õġ�
- ZooKeeper �����ݱ������ڴ���,��Ҳ�ͱ�֤�� ���������͵��ӳ�(�����ڴ��������ܹ��洢��������̫��,������Ҳ�DZ��� znode �д洢����������С�Ľ�һ��ԭ��)��
- ZooKeeper �Ǹ����ܵġ� �ڡ��������ڡ�д����Ӧ�ó��������������,��Ϊ��д���ᵼ�����еķ�������ͬ��״̬��(���������ڡ�д����Э������ĵ��ͳ�����)
- ZooKeeper ����ʱ�ڵ�ĸ�� ��������ʱ�ڵ�Ŀͻ��˻Ựһֱ���ֻ,˲ʱ�ڵ��һֱ���ڡ������Ự�ս�ʱ,˲ʱ�ڵ㱻ɾ�����־ýڵ���ָһ����� znode ��������,������������ znode ���Ƴ�����,������� znode ��һֱ������ ZooKeeper �ϡ�
- ZooKeeper �ײ���ʵֻ�ṩ����������:�� ����(�洢����ȡ)�û������ύ������;�� Ϊ�û������ṩ���ݽڵ��������
-
�Ƽ��Ķ�
Ϊʲô����ij���Ա�ɳ����֮��?����Alibaba��Java�ɳ��ʼǡ��Ҷ���!_��С�εIJ���-CSDN����?blog.csdn.net
2020����35K��н��MySQL���Աʼǽ���:����+�Ż�+��+����ѯ+����
�Ƽ��ۿ�
���������⼯���:��������+��Ѷ����+֧��������+ƴ������+�ֽ�����+�Ա�����_�������� (�b-�b)�ĥ� �ɱ�~-bilibili?www.bilibili.com
?
������!Bվ��ȫ����ײ����:TCP��Sockt���������֡��Ĵλ��֡�NIO��Epoll����·����(����Դ�롢��ͼ)?www.bilibili.com
?
��������ܹ�ʦ�����ϸ����springԴ��(�����������Ϻ�Դ��)?www.bilibili.com
?
Java�ܹ�ʦ�ػ��������֪ʶ��:���̡߳�JVM�����ģʽ��MySQL��Redis��ZooKeeper?www.bilibili.com
?
���δ������ȫ�°汾!Tomcat��TCP/IP��IO���ֲ�ʽ����ܹ�ȫ��?www.bilibili.com
cs