Ŀ¼
- ����
- ��������
- ����ΪʲôҪ������һ�У�
- PyTorch ʵ��
- ֱ�Ӿ�������
- �ܽ�
- ��¼��
����
���������ݷ����������ڡ���ʮ����������һֱ�������źź�ͼ��������������dz�Ϊ�ִ����������Ҫ��ɲ��֡�����㴦�����ݵĻ�������ܻ��������۸��ӵ����⡣
��ѧ�ϣ�������ʾΪ��
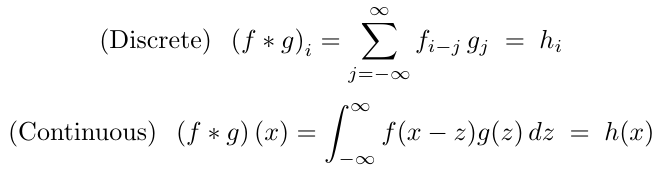
������ɢ�����ڼ���Ӧ�ó����и�Ϊ���������ڱ��ĵĴ��������ҽ�ʹ��������ʽ����Ϊʹ������������֤����������(��������)Ҫ���öࡣ֮�����ǽ��ص���ɢ�������ʹ�ø���Ҷ�任�� PyTorch ��ʵ��������ɢ�������Կ��������������Ľ��ƣ���������������ɢ�ڹ��������ϡ���ˣ����Dz���Ϊ�����ɢ�İ�������֤������������
��������
����ѧ����˵������������������������
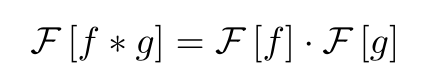
���е���������Ҷ�任��(�ﵽ����������) ��
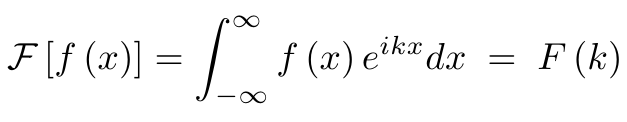
���仰˵��λ�ÿռ��еľ����ȼ���Ƶ�ʿռ��е�ֱ�ˡ�����뷨���൱��ֱ�۵ģ����Ƕ��������������˵��֤�����������Ǿ��˵����ס�Ҫ������һ�㣬����Ҫд����ʽ����ߡ�
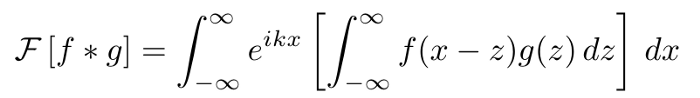
�����л����ֵ�˳���滻����(x = y + z) ����������������������
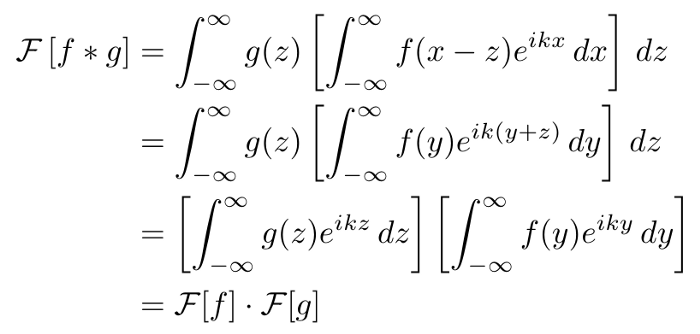
����ΪʲôҪ������һ�У�
��Ϊ���ٸ���Ҷ�任���㷨���Ӷȵ��ھ�����ֱ�Ӿ���������и��Ӷ� O(n^2) ����Ϊ�� f �У����Ǵ��� g �е�ÿ��Ԫ�أ����Կ����� O(nlogn)ʱ���ڼ�������ٸ���Ҷ�任������������ܴ�ʱ�����DZȾ���Ҫ��öࡣ����Щ����£����ǿ���ʹ�þ�����������Ƶ�ʿռ��еľ�����Ȼ��ִ���渵��Ҷ�任�ص�λ�ÿռ䡣
�������Сʱ(����3x3�����ں�) ��ֱ�Ӿ�����Ȼ���졣�ڻ���ѧϰӦ�ó����У�ʹ��С�ں˸�Ϊ����������� PyTorch �� Tensorflow ���������ѧϰ��ֻ�ṩֱ�Ӿ�����ʵ�֡���������ʵ�������кܶ�ʹ�ô��ں˵����������и���Ҷ�����㷨����Ч��
PyTorch ʵ��
���ڣ��ҽ���ʾ����� PyTorch ��ʵ�ָ���Ҷ������������Ӧ��ģ�� torch.nn.functional.convNd �Ĺ��ܣ������� fft��������Ҫ�û����κζ���Ĺ�������ˣ���Ӧ�ý������� Tensors (signal��kernel �Ϳ�ѡ bias)��Ӧ��������� padding���Ӹ����Ͻ�������������ڲ�����ԭ���ǣ�
def fft_conv(
signal: Tensor, kernel: Tensor, bias: Tensor = None, padding: int = 0,
) -> Tensor:
# 1. Pad the input signal & kernel tensors
# 2. Compute FFT for both signal & kernel
# 3. Multiply the transformed Tensors together
# 4. Compute inverse FFT
# 5. Add bias and return
�����ǰ���������ʾ�IJ���˳������ FFT ����������������ӣ��ҽ�����һ��һά����Ҷ���������ǽ�����չ����ά����ά�����Ǻܼġ�
1. �����������
������Ҫȷ�� signal �� kernel �����֮������ͬ�Ĵ�С��Ӧ�ó�ʼ��� signal��Ȼ����� kernel �������ƥ�䡣
# 1. Pad the input signal & kernel tensors
signal = f.pad(signal, [padding, padding])
kernel_padding = [0, signal.size(-1) - kernel.size(-1)]
padded_kernel = f.pad(kernel, kernel_padding)
ע�⣬��ֻ��һ����� kernel������ϣ��ԭʼ�ں�λ������������࣬�������Ϳ����� signal ����Ŀ�ʼ���롣
2. ���㸵��Ҷ�任
��dz�����Ϊ n ά fft �Ѿ��� PyTorch ��ʵ���ˡ����Ǽ�ʹ�����ú�������������ÿ�����������һ��ά���� FFT��
# 2. Perform fourier convolution
signal_fr = rfftn(signal, dim=-1)
kernel_fr = rfftn(padded_kernel, dim=-1)
3. �任�������
���˾��ȵ��ǣ��������ǹ�������ӵIJ��֡���������ԭ��(1) PyTorch ���������ڶ�ά�����ϣ�������ǵ� signal �� kernel ����ʵ��������ά�ġ��� PyTorch �ĵ��е��������ʽ�����ǿ��Կ�������˷�����ǰ����ά�������е�(������ƫ����) ��
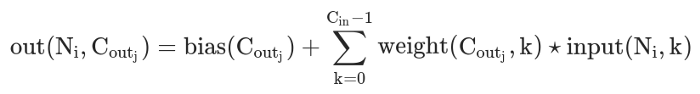
���ǽ���Ҫ�����������˷����Լ���ת�����ά�ȵ�ֱ�ӳ˷���
PyTorch ʵ����ʵ���˻����/ֵ���������Ǿ���������(TensorFlow ���������ѧϰ��Ҳ����ˡ�)����������������أ�����һ����Ҫ�ı�־�仯��
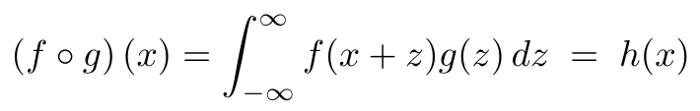
�������ȣ�����Ч����ת�˺˵ķ���(g)�����Dz����ֶ���ת�ںˣ������ڸ���Ҷ�ռ��������ں˵Ĺ����������������⡣�������Dz���Ҫ����һ��ȫ�µ� Tensor���������������ٶ����Ը��죬�ڴ�Ч��Ҳ���ߡ�(����ĩβ�ĸ�¼�м�Ҫ˵�������ַ����Ĺ���ԭ����)
# 3. Multiply the transformed matrices
def complex_matmul(a: Tensor, b: Tensor) -> Tensor:
"""Multiplies two complex-valued tensors."""
# Scalar matrix multiplication of two tensors, over only the first two dimensions.
# Dimensions 3 and higher will have the same shape after multiplication.
scalar_matmul = partial(torch.einsum, "ab..., cb... -> ac...")
# Compute the real and imaginary parts independently, then manually insert them
# into the output Tensor. This is fairly hacky but necessary for PyTorch 1.7.0,
# because Autograd is not enabled for complex matrix operations yet. Not exactly
# idiomatic PyTorch code, but it should work for all future versions (>= 1.7.0).
real = scalar_matmul(a.real, b.real) - scalar_matmul(a.imag, b.imag)
imag = scalar_matmul(a.imag, b.real) + scalar_matmul(a.real, b.imag)
c = torch.zeros(real.shape, dtype=torch.complex64)
c.real, c.imag = real, imag
return c
# Conjugate the kernel for cross-correlation
kernel_fr.imag *= -1
output_fr = complex_matmul(signal_fr, kernel_fr)
PyTorch 1.7�Ľ��˶Ը�����֧�֣������� autograd �л���֧�ֶԸ���������������������ڣ����DZ����д�����Լ��ĸ��� matmul ������Ϊһ����������Ȼ���Ǻ����룬������ȷʵ��Ч��������δ���İ汾�в���������⡣
4. ������任
ʹ�� torch.irfftn ����ֱ�Ӽ�����任��Ȼ��ü��������������䡣
# 4. Compute inverse FFT, and remove extra padded values
output = irfftn(output_fr, dim=-1)
output = output[:, :, :signal.size(-1) - kernel.size(-1) + 1]
5. ����ƫִ�����
����ƫ����Ҳ�����ס����ס��������������е�ÿ��ͨ����ƫ�����һ��Ԫ�أ�����Ӧ�ص�������״��
# 5. Optionally, add a bias term before returning.
if bias is not None:
output += bias.view(1, -1, 1)
����������������һ��
Ϊ����������������ǽ�������Щ����Ƭ�α����һ���ھۺ�����
def fft_conv_1d(
signal: Tensor, kernel: Tensor, bias: Tensor = None, padding: int = 0,
) -> Tensor:
"""
Args:
signal: (Tensor) Input tensor to be convolved with the kernel.
kernel: (Tensor) Convolution kernel.
bias: (Optional, Tensor) Bias tensor to add to the output.
padding: (int) Number of zero samples to pad the input on the last dimension.
Returns:
(Tensor) Convolved tensor
"""
# 1. Pad the input signal & kernel tensors
signal = f.pad(signal, [padding, padding])
kernel_padding = [0, signal.size(-1) - kernel.size(-1)]
padded_kernel = f.pad(kernel, kernel_padding)
# 2. Perform fourier convolution
signal_fr = rfftn(signal, dim=-1)
kernel_fr = rfftn(padded_kernel, dim=-1)
# 3. Multiply the transformed matrices
kernel_fr.imag *= -1
output_fr = complex_matmul(signal_fr, kernel_fr)
# 4. Compute inverse FFT, and remove extra padded values
output = irfftn(output_fr, dim=-1)
output = output[:, :, :signal.size(-1) - kernel.size(-1) + 1]
# 5. Optionally, add a bias term before returning.
if bias is not None:
output += bias.view(1, -1, 1)
return output
ֱ�Ӿ�������
������ǽ�ʹ�� torch.nn.functional.conv1d ��ȷ��������ֵ�ϵ�ͬ��ֱ��һά����������Ϊ�������빹��������������������ֵ����Բ��졣
import torch
import torch.nn.functional as f
torch.manual_seed(1234)
kernel = torch.randn(2, 3, 1025)
signal = torch.randn(3, 3, 4096)
bias = torch.randn(2)
y0 = f.conv1d(signal, kernel, bias=bias, padding=512)
y1 = fft_conv_1d(signal, kernel, bias=bias, padding=512)
abs_error = torch.abs(y0 - y1)
print(f'\nAbs Error Mean: {abs_error.mean():.3E}')
print(f'Abs Error Std Dev: {abs_error.std():.3E}')
# Abs Error Mean: 1.272E-05
���ǵ�����ʹ�õ���32λ���ȣ�ÿ��Ԫ������Լ1e-5�`�൱��ȷ��������Ҳִ��һ�����ٵĻ�������ÿ���������ٶȣ�
from timeit import timeit
direct_time = timeit(
"f.conv1d(signal, kernel, bias=bias, padding=512)",
globals=locals(),
number=100
) / 100
fourier_time = timeit(
"fft_conv_1d(signal, kernel, bias=bias, padding=512)",
globals=locals(),
number=100
) / 100
print(f"Direct time: {direct_time:.3E} s")
print(f"Fourier time: {fourier_time:.3E} s")
# Direct time: 1.523E-02 s
# Fourier time: 1.149E-03 s
�����Ļ���������ʹ�õĻ��������������ı仯��(��������һ̨�dz��ɵ� Macbook Pro ���в��ԡ�)����1025���ںˣ�����Ҷ�����ƺ�Ҫ��10�����ϡ�
�ܽ�
��ϣ�����Ѿ��ṩ��һ�����Ľ��ܸ���Ҷ����������Ϊ����һ���dz���ļ��ɣ�����ʵ�������кܶ�Ӧ�ó������ʹ��������Ҳϲ����ѧ�����Կ�����̺ʹ���ѧ�Ľ���Ǻ���Ȥ�ġ���ӭ�������е����ۺͽ����Ե������������ϲ����ƪ���£�����ƣ�
��¼��
���� vs. �����
�ڱ��ĵ�ǰ�棬����ͨ���ڸ���Ҷ�ռ���ȡ���ں˵Ļ���ع������ʵ�֡���ʵ���ϵߵ��� kernel �ķ�������������ʾһ��Ϊʲô�����������ȣ���ס�����ͻ���صĹ�ʽ��
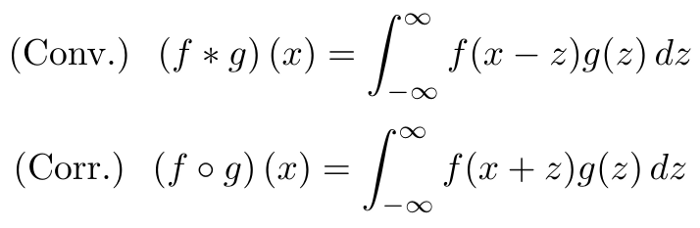
Ȼ�������������� g(x) �ĸ���Ҷ�任��
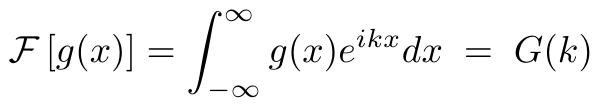
ע�⣬g(x)��ʵֵ�ģ����������ܹ�����仯��Ӱ�졣Ȼ���ı���(y =-x)������ʽ��
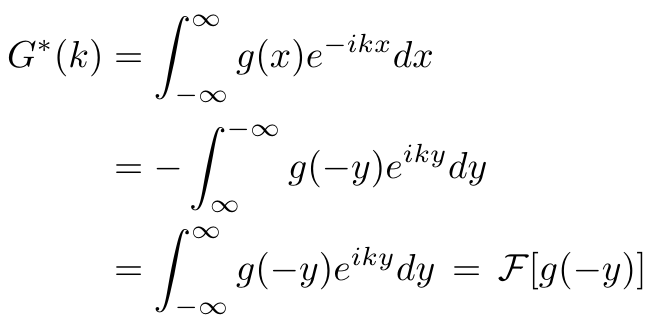
jsjbwy