目录
为什么写本文?
什么是编码?
什么是字符?
字符集和字符编码的概念
简述字符集和字符编码发展史
Unicode字符集以及相关字符编码
参考链接
为什么写本文?
其实在我心中是一直知道有字符编码这么个概念存在的,只是从来没有遇到过关于它的相关问题,因此也就没有好好去了解它的动力。既然有这篇博文的存在,证明肯定是遇到字符编码的问题了。
事情是这样的,最近公司的产品需要支持短信功能,但是如果想要短信内容支持中文的话,通信模块规定必须使用UCS2字符编码方式,而程序用的是UTF-8字符编码方式,那么就需要将UTF-8字符编码转换成UCS2字符编码方式。
就这个问题本身而言是很好解决的,网上很多代码片段就可以解决,使用glibc的iconv函数也可以完美地解决问题。
问题解决之后,特地查阅了相关资料,想了解下这块知识。可是越看越糊涂,原来关于这块知识没有想象得那么简单,究其原因大概是因为字符编码是随着计算机的发展而发展的,因此背负了太多的历史包袱。在连续看了不少文章后,终于在阅读了阮一峰老师的博文《字符编码笔记:ASCII,Unicode和UTF-8》和知乎上的《对于字符编码,程序员的话应该了解它的哪些方面?》之后,对字符集和字符编码的相关知识有了点清晰的认识。也建议和我一样对这块知识毫无基础的童鞋先阅读这两篇文章!
那么问题来了,既然已经有以上非常好的文章,我为什么还要写这篇博文呢?一是写在这里,方便自己以后查阅;二是在上面博文的基础之上添加了一些自己的理解。
好,废话不多说,让我们从最基础的概念慢慢说起吧!
什么是编码?
之所以在这里需要强调一下编码的基本概念,是因为我发现身边很多人,包括很多网络文章都有一个误区,那就是一谈到计算机编码这个概念时,他们第一时间想到的是字符编码,也就是说他们把字符编码概念等同于计算机编码这个概念。实际上,计算机编码这个概念的范围很广泛,包括很多,字符编码只是其中一个。然后呢,计算机编码也只是编码这个概念的子集。
因此概念范围从大到小应该依次是编码 >?计算机编码 >?字符编码。
好,先来看看编码的定义。
编码是信息从一种形式转换为另一种形式的过程。解码,是编码的逆过程。
这个定义里提到的“信息”可以是我们所知的一切事物,包括眼睛看得见的,看不见的。例如,人类在有了语言之后,为了克服语言自身在空间和时间上的限制,人类又发明了文字,那么这个语言到文字的转换就是一个完整的编码。此外,还有大家熟知的模拟信号转换成数字信号,或者从数字信号转换成模拟信号,都符合编码的概念。那么程序员平时写的代码到最终的二进制文件的生成是不是也符合编码的概念呢? 答案是肯定的。
那什么是计算机编码呢? 或者说计算机领域的编码是个什么概念呢??
从编码的定义中我们可以看出,对信息的原始形式和转换后的形式没有固定的要求。但是计算机编码对对转换后的形式是有要求的,那就是转换后的形式必须是数字,也就是大家常听到的数字化。为什么要数字化呢??众所周知,在计算机的世界,所有的信息都是0/1组合的二进制序列,计算机是无法直接识别和存储其他信息的。因此如果想让计算机处理信息,第一步就是将这些信息数字化,那么从信息原始的形式到数字化的过程就是计算机编码的概念了。
OK,总结一下,因为计算机内部会把所有的信息都当成数字来处理,尽管有些信息本身并不是数字。例如,音视频数据必须经过编码之后才能被计算机存储和传输,这也就是音视频编解码领域的知识。那么,什么是字符编码呢? 我相信,到了这里,大家一定明白了:因为计算机不能直接处理字符,因此字符必须先数字化后才能被计算机处理,那么这个数字化的过程就是字符编码了。好了,接下来,让我们先从字符这个基本概念出发,然后慢慢引出什么是字符集,以及什么是字符编码!
参考链接:
《Encoding》《encoding and decoding》《Encoding》
什么是字符?
从广义上来说,字符(character)是信息的一个单位,文本数据由他们组成,通过它们,文本的内容得以展现和表示,同时它们又是对文本数据进行控制和处理的基本单位。
那么在计算机领域到底哪些信息属于字符范畴呢?包括文字、数字符号、图形符号(标点符号)以及控制符号。
因此一个英文字母是一个字符,一个中文汉字是一个字符,一个阿拉伯数字是一个字符,一个标点符号是一个字符,一个回车符或者TAB键同样是一个字符。
问题来了,计算机要如何识别和存储字符呢?
由上文我们已经知道,在计算机的世界,所有的信息都是0/1组合的二进制序列,计算机是无法直接识别和存储字符的。因此,字符必须经过编码才能被计算机处理。也就是说,字符和其它任何信息一样,对于计算机来说都是无差别的数字,这些数字只对创建或者能够识别它们的程序来说才有意义,才能正确处理和还原。正因为这样,用汉字写的文档在一个没有汉字处理能力的计算机上显示,结果一定是令人沮丧的。
字符集和字符编码的概念
首先给出结论:字符集和字符编码是两个不同的概念!!!
现在我们知道,字符只有按照一定规则编码,最终表示为0/1二进制序列的形式,才能被计算机处理。因此为了使计算机能够处理字符信息,首先要决定选取哪些字符。这样就形成了一个集合,一个表,称为字符表(character repertoire)。但是如果你简单地把这个字符表当做字符集的话,就很片面了,这样就会导致后来你对Unicode字符集以及UTF-8等字符编码之间的一些关系搞不清楚。
那么怎么来理解字符集(character set)的概念比较正统呢?
在理解字符表的基础上,然后,对于任何一个字符表来说,它的每个字符都占有一席之地,并分配有一个唯一的数字,这个数字被称为代码点(code point 或者 code position)。注意,这个代码点仅仅代表字符在字符表中的一个编号,它仅仅是数学意义上的数字,通常和字符在字符表中的位置有关,与对应的字符在计算机内实际的表现形式、存储方法和传输是没有关系的(这些任务是字符编码需要完成的任务)。并且代码点也并不一定是连续的数字。例如,ASCII字符集用0~127这连续的128个代码点分别表示128个字符,而GBK字符集使用区位码的方式为每个字符编号:首先定义一个94 X 94的矩阵,行称为“区”,列称为“位”,然后将所有国标汉字放入矩阵当中,这样每个汉字就可以用唯一的“区位”码来标识了。例如“中”字被放到54区第48位,因此代码点就是5448。也就是说,每个字符集得出字符对应的代码点有不同的方案。
因此,本质上字符集是已编号字符的有序集合,每个字符的编号我们称之为代码点。
关于字符集,如果你在网上查找资料,会发现有很多名称,例如“coded character set”、“code pages”、“charset”等等,不要纠结,它们都是指的字符集的概念。
OK,知道了什么是字符集之后,那么什么又是字符编码呢?
头脑简单的我,想当然地认为直接将代码点编码为二进制序列的过程就是字符编码了吧!事实证明我是错的!
在我们规定好了一个字符集之后,并不代表计算机一定要将字符对应的代码点本身直接存储!有时候,我们按照一定的规则,根据不同的需求,以及现实计算机的软硬件限制,将字符的代码点再次处理,以更加适应计算机存储、网络传输的需要。字符编码便是规定了如何编码、存储这些字符对应的代码点的二进制序列。
也就是说,字符编码这个概念其实指的是一个过程 -- 将字符的代码点变成最后可以直接在计算机内存储或者传输的二进制序列的过程。
可以想象,最直接简单的字符编码方式就是直接使用字符的代码点,ASCII就是这个这样做的,直接将代码点变成等数值的7比特数字即可,编码值的范围是二进制的0000 0000 ~ 0111 1111,用十六进制表示就是0x00~0x7F。
但是直接使用字符的代码点容易导致一个问题,就是让人有时候分不清字符集和字符编码的概念。ASCII就可以即代表ASCII字符集,也可以代表ASCII字符编码。同样的,IOS-8859-1、GB2312、GBK等,都是即表示了字符集又表示了对应的字符编码,但是Unicode就是个例外,它仅仅代表字符集。因此一定要对字符集和字符编码这两个概念有个清晰的认识,否则后面理解Unicode字符集以及对应的诸多字符编码就会很迷惑,傻傻分不清楚。也就是说,一个字符集可能对应着多种不同的字符编码方法。
补充:关于字符集和字符编码是两个不同概念的文章,网文《字符集与编码(一)——charset vs encoding》最好。
简述字符集和字符编码发展史
在开始介绍Unicode字符集以及由它衍生出的不同字符编码之前,我们来简单了解下字符集和字符编码的发展史~
大家最熟悉的字符集肯定是ASCII了。可以这么说,ASCII是现如今所有其它字符集的鼻祖。原始的ASCII字符集包含128个字符,0~31和127是控制字符,32~126是可打印字符(包含标点符号、数字0~9和大小写字母)。
当计算机传到欧洲的时候,很明显ASCII不足以包含欧洲的所有字符,所以欧洲人民利用未使用的那个最高bit扩展了ASCII,即新增了128个符号,0~127依然是ASCII,而128~255则是扩展的字符。但是我们知道,欧洲国家太多了,每个国家使用的字符又不同,因此128~255这些扩展字符可以说每个国家是不同的,这就导致了很多新的字符集的诞生,据我了解仅仅ISO 8859字符集就根据不同的国家总共有16个,分别为8859-1~8859-16,简直令人发指。这些字符集有时也被称为扩展ASCII字符集。
原始ASCII字符集和扩展ASCII字符集只使用了一个字节,历史上称为单字节字符集(single byte character set:SBCS)。
当计算机终于传到亚洲,尤其我们中国人民的手里之后,那么要计算机显示我们的中文那是理所当然的需求啊。但是汉字数量庞大, 一个字节肯定是远远不够的了,因此每个字符(汉字)需要更长的字节来编码。但是又要兼容ASCII,这就形成了今天所说的多字节字符。中文字符集主要有两个,一个是GB2313,另一个是GBK,它们都是兼容ASCII字符集的,也就是在这些字符集中,ASCII字符依然使用一个字节来表示,而其他字符使用两个字节来表示。这样的字符集被称为双字节字符集(double byte character set:DBCS)。当然了,可千万别被双字节字符集这个名字所欺骗哦,毕竟这样的字符集实际上是一个混合体,因为ASCII字符依然保持单字节不变。
以上所说的,可以说是字符集和字符编码的战国时代,都是各个国家各自为政的产物。
到了上世纪90年代,终于有组织致力于制定一个全球性的字符集和字符编码标准,至此,Unicode字符集诞生。
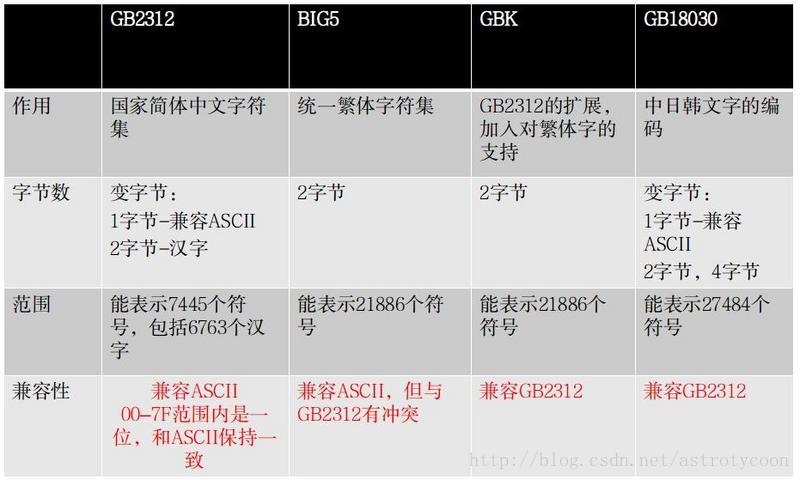
在具体介绍Unicode字符集之前,我补充说明一下关于我们中文字符集,毕竟这和我们息息相关。由于历史的原因,在Unicode之前,一共存在过3套中文编码标准。GB2312-80,是中国大陆使用的国家标准,其中一共编码了6763个常用简体汉字。Big5,是台湾使用的编码标准,编码了台湾使用的繁体汉字,大概有8千多个。HKSCS,是中国香港使用的编码标准,字体也是繁体,但跟Big5有所不同。这3套编码标准互不兼容。因为其不兼容性,在同一个系统中同时显示GB2312-80和Big5基本上是不可能的。后来,由于各方面的原因,国际上又制定了针对中文的统一字符集GBK和GB18030,其中GBK已经在Windows、Linux等多种操作系统中被实现。GBK兼容GB2312,并增加了大量不常用汉字,还加入了几乎所有的Big5中的繁体汉字。但是GBK中的繁体汉字和Big5中的几乎不兼容。GB18030相当于是GBK的超集,比GBK包含的字符更多。
? ? ? ? ?
Unicode字符集以及相关字符编码
通过上面对字符集和字符编码历史的简单介绍,想必大家了解到全世界各个国家都在为自己的文字定义字符集以及对应的编码方式,并且互不兼容,那么乱码就在所难免了。于是人们就想:我们能不能定义一个超大的字符集,它可以容纳全世界所有的字符,再对这些字符统一进行编号,让每一个字符都对应一个不同的、唯一的代码点,从而就不会再有乱码了。
早期,有两个机构试图做这件事:
(1)?国际标准化组织(ISO)。众所周知,ISO组织制定了很多国际标准,在1984年该组织定义了对应的编码标准ISO/IEC 10646,简称为ISO 10646,此标准所定义的字符集,称作为通用字符集(Universal Coded Character Set,简称UCS)。
(2)统一码联盟(Unicode Inc.)。他们由Xerox、Apple等软件制造商于1988年组成,并且开发了Unicode标准(The Unicode Standard)。

早期的ISO/IEC 10646标准可以容纳2^31个字符(20多个亿),代码点范围是0x000-00000 - 0x7FFF-FFFF。定义的字符编码方案有两个,分别为UCS-2和UCS-4。它们都是固定长度字符编码方案,UCS-2使用16 bit位,共容纳2^16个代码点,代码点范围是0x0000-0xFFFF。UCS-4使用31 bit位,可以容纳全部代码点,因此代码点范围是0x0000-0000?-?0x7FFF-FFFF。
而Unicdoe标准可以容纳1,114,112个字符,代码点范围是0x0?-?0x10FFFF。为了描述一个代码点,可以采用“U”加十六进制整数的方法,如U+004D。我们可以通过Unicode编码表来查询我们的汉字在Unicode字符集中对应的代码点。例如汉字“瑞”的Unicode代码点为U+745E。
1991年前后,两个项目的参与者都认识到,世界不需要两个不兼容的字符集。于是,它们开始合并双方的工作成果,并为创立一个单一编码表而协同工作。从Unicode 2.0开始,Unicode采用了与ISO 10646-1相同的字库和字码;ISO也承诺,ISO 10646将不会超出U+10FFFF的UCS-4编码赋值,以使得两者保持一致。
因此,我们现在只需要关注Unicode标准就可以了。
Unicode标准把这些代码点均分成了17个代码平面(Code Plane),编号为#0到#16。每个代码平面包含65,536(2^16)个代码点(17*65,536=1,114,112)。其中,Plane#0叫做基本多语言平面(Basic Multilingual Plane,BMP),其余平面叫做补充平面(Supplementary Planes,SP)。Unicode7.0只使用了17个平面中的6个,并且给这6个平面起了名字,如下图所示:
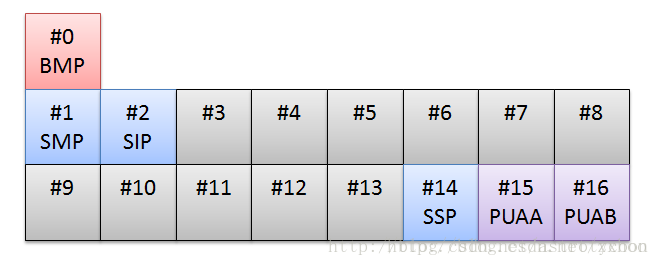
下面是这些Code Plan的名字和用途:
Plane#0 BMP(Basic Multilingual Plane)大部分常用的字符都坐落在这个平面内,比如ASCII字符,汉字等。
Plane#1 SMP(Supplementary Multilingual Plane)这个平面定义了一些古老的文字,不常用。
Plane#2 SIP(Supplementary Ideographic Plane)这个平面主要是一些BMP中没有包含的汉字。
Plane#14 SSP(Supplementary Special-purpose Plane)这个平面定义了一些非图形字符。
Plane#15 SPUA-A(Supplementary Private Use Area A)
Plane#16 SPUA-B(Supplementary Private Use Area B)
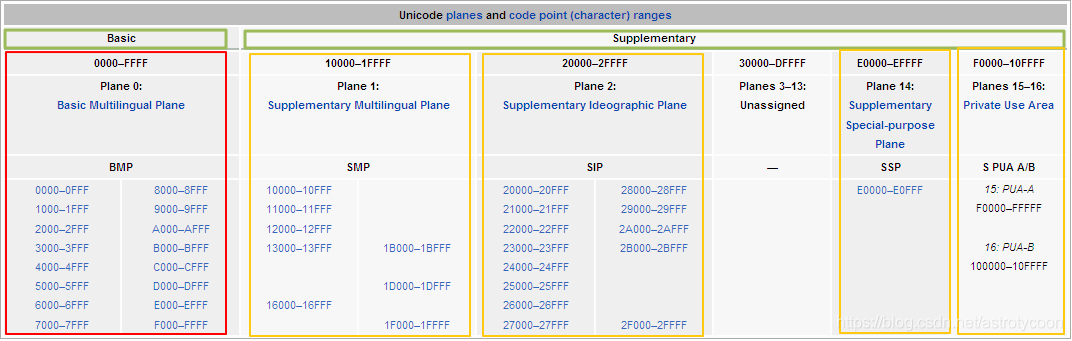
我们需要重点了解的是BMP。
GNU Unifont制作了一张将BMP包含的字符放在一张图上的图片(255 x 255),可以参见Unifoundry.com网站查看最新的图片。是不是很壮观?
果然汉字占了很大一部分。在Unicode中统一将BMP中的中日韩文字称为CJK(CJK:Chinese, Japanese, and Korean)。
我们可以根据功能将BMP划分成三大部分:
(1)私有区域(Private Use Area)。代码点范围U+E000 ~ U+F8FF是私有区域,共6400个代码点。可以在这里定义自己专用的字符。
(2)代理区域(Surrogate Area)。代码点范围U+D800 ~ U+DFFF是代理区域,共2048个代码点。其中U+D800 ~ U+DBFF属于高代理区(High Surrogate Area),共1024个代码点;DC00–DFFF 属于低代理区(Low Surrogate Area),共1024个代码点。代理区的用途是提供 UTF-16编码BMP之外的代码点,即辅助平面里的代码点,在后文讨论UTF-16时会详细了解这个过程。
(3)剩下的57088个(65536 - 6400 - 2048)代码点就是使用的了。
OK,在继续讨论Unicdoe之前,我需要强调一下:unicode仅仅是字符集而已,而不是字符编码!!!
Unicode字符集是典型的对应着多种字符编码的字符集。Unicode字符集的字符编码一般被人们统称为UTF,它是英文“Unicode Transformation Format”的首字母缩写。因此我们也可以说Unicode字符集对应有多种UTF,其中最为典型的有UTF-8、UTF-16以及UTF-32。接下来我们一一了解这三种字符编码的实现细节。
code units
在开始讨论这几个字符编码之前,我想有必要明白一个概念,那就是code units。Wikipedia上给出的定义是:A code unit is a bit sequence used to encode each character of a repertoire within a given encoding form. 意思就是说对代码点进行编码后的二进制比特序列,是由一个或者多个编码单元按照一定的序列组成的。并且这个code unit到底是多少bit是跟具体的字符编码方案相关的。接着Wikipedia举了几个例子:

code unit代表最小的可用来识别一个合法字符的最小字节数。 参考《code point & code unit》
UTF-32
UTF-32代表的是Unicode Transformation Format in 32 bits,它使用4个字节来编码Unicode字符集的所有代码点,是典型的固定长度字符编码方案。UTF-32的code unit为4字节,即一个代码点由1个code unit组成。因为Unicode字符集总共才拥有1,114,112个代码点,21 bits就够了,因此UTF-32毫无压力。不过最大的缺点就是太浪费空间,加上会存在大小端问题(UTF-32BE & UTF-32LE),所以几乎没人使用这套字符编码方案。
UTF-16
UTF-16是Unicode字符集的另一种字符编码方案,它是变长字符编码方案。它用2个字节来编码BMP里的代码点(除了那2048个代理区域的代码点),用4个字节编码辅助平面里的代码点,总共可以编码1112064个代码点(1114112-2048=1112064)。UTF-16的code unit是2字节,即一个代码点由1个或者2个code unit组成。
是不是很好奇UTF-16是如何使用4个字节(2个code unit)来编码辅助平面里的字符的呢?又与上文提到的有点神秘的代理区域有什么关系呢? 好,带着这些疑惑,是时候来详细解释什么是代理区域了!
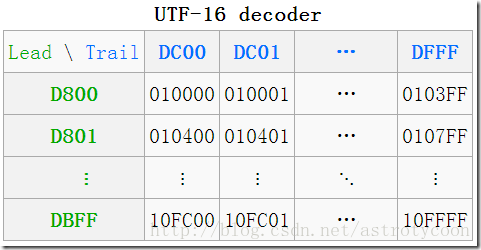
代理区域的目的只有一个,那就是提供给UTF-16,以使UTF-16可以编码辅助平面内的代码点,总共有 2048 个位置,均分为高代理区(D800–DBFF)和低代理区(DC00–DFFF)两部分,各1024,这两个区组成一个二维的表格,共有1024×1024=2^10×2^10=2^4×2^16=16×65536,所以它恰好可以编码的16 个辅助平面中的所有字符。如下图所示:
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
为什么分别是从0xD800和0xDC00开始呢?我们可以看看它们的二进制bit位如下:
0xD800
1101 1000 0000 0000
0xDC00
1101 1100 0000 0000
可以看到,各自有10 bit可以自由的编码使用,正好20-bit。
高代理区有时也称为“leading”代理,低代理区有时也称为“trailing”代理。
观察上图可以得出,[D800, DC00]对应的是辅助平面中的第一个代码点(U+10000)。[DBFF,DFFF]对应的是辅助平面中的最后一个代码点(U+10FFFF)。在UTF-16中,我们将高代理区和低代理区的组合成为代理对(Surrogate Pair),也就是UTF-16中编码一个辅助平面中的代码点是通过代理对来表示的。
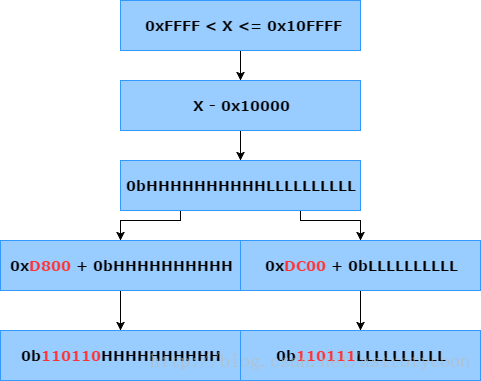
OK,现在假设给你一个有效的辅助平面内的代码点,那么如何编码成代理对呢? 步骤如下:
(1)从代码点里减去0x10000,得到一个只需要20 bit就可以表示的数字,范围为0x00000 ~ 0xFFFFF,这正是辅助平面的代码点总个数。
(2)将第(1)部得到的数字除以1024, 然后商加上0xD800就是leading,余数加商0xDC00就是trailing。
leading = (代码点 - 0x10000) / 1024 + 0xD800
trailing = (代码点 - 0x10000) % 1024 + 0xDC00
最后(leading trailing)就是最终UTF-16的形式,共4个字节,2个代码单元。
不知道大家有没有注意到,被除数是20 bit的数字,而除数是1024(2^10),那么商就是被除数的高10 bit,余数就是被除数的低10 bit。因此在实际写代码时肯定是将上述的第(2)步骤替换成相应的移位操作,这样会更高效。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 
这样,0x10000 ~ 0x10FFFF范围内的字符就被编码成了一个代理对[leading surrogate, trailing surrogate]:两个16-bits的code unit,取值范围分别是0xD800..0xDBFF和0xDC00..0xDFFF。而BMP中得到的code unit的范围是0x0000 ~ 0xFFFF(0xD800..0xDFFF是保留的,不包含其中),所以这三个区段是相互不重叠的,在解码时很容易实 现。
好,我们来看一个具体的例子,假设我们现在要对辅助明面内的代码点U+64321进行UTF-16编码,过程如下:
- 因为0X64321大于0xFFFF,?所以在0x64321的基础上先减去0x10000 --> 0x54321,转成二进制:0101-0100-0011-0010-0001。
- 得出高10位(0101-0100-00)和低10位(11-0010-0001)
- 添加0xD800到高10位(不足补0),得出UTF-16高位:0xD800 + 0x0150 --> 0xD950
- 添加0xDC00到低10位(不足补0),得出UTF-16低位:0xDC00 + 0x0300 --> 0xDF21
- 得出古意大利字母"?"的UTF-16BE编码:U+D950DF21
V = 0x64321
Vx = V - 0x10000
= 0x54321
= 01010100 0011 0010 0001
Vh = 01 0101 0000 // Vx 的高位部份的 10 bits
Vl = 11 0010 0001 // Vx 的低位部份的 10 bits
w1 = 0xD800 // 结果的前16位元初始值
w2 = 0xDC00 // 结果的后16位元初始值
w1 = w1 | Vh
= 1101 1000 0000 0000
| 01 0101 0000
= 1101 1001 0101 0000
= 0xD950
w2 = w2 | Vl
= 1101 1100 0000 0000
| 11 0010 0001
= 1101 1111 0010 0001
= 0xDF21
所以,这个字 U+64321 最终的 UTF-16 编码是:
0xD950 0xDF21
更多关于UTF-16编码的例子可以参考如下wiki截图:
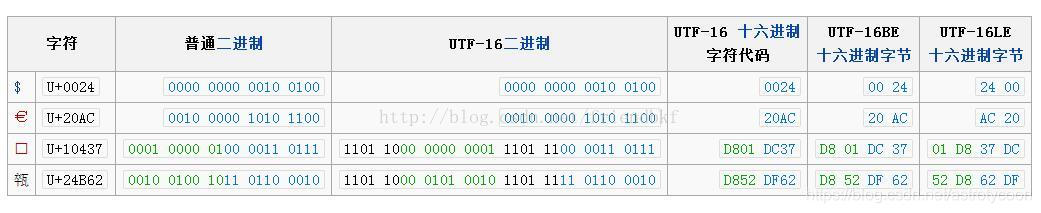
最后,让我们简单说说UTF-16的优缺点。UTF-16的优点是绝大多数的字符使用的是2个字节编码,即一个code?unit,那么处理起来会很方便高效。但是UTF-16也有很多缺点,第一个就是它不兼容ASCII,这会使老美很不高兴的。还有一点,因为UTF-16的code?unit是2个字节,那么就会存在恼人的字节序问题,即大小端问题。根据实际存储或者传输使用的是大端还是小端,UTF-16会细分为UTF-16BE和UTF-16LE。
可以参考文章《【字符编码系列之五】Unicode实现之UTF-16详解》
#ifndef __UTF16_H__
#define __UTF16_H__
// for char16_t and char32_t
#include <uchar.h>
// for size_t
#include <stdlib.h>
#ifdef __cplusplus
extern "C" {
#endif
// encode
size_t utf16_encode_length(char32_t value);
size_t utf16_encode(char32_t in, char16_t *out);
// decode
size_t utf16_decode_length(char16_t first_word);
size_t utf16_decode(const char16_t *in, char32_t *out);
#ifdef __cplusplus
}
#endif
#endif // __UTF16_H__
#include "utf16.h"
// encode
/** 编码一个code point需要多少code unit
* 出错,返回0
*/
size_t utf16_encode_length(char32_t value)
{
if (value <= 0xFFFF) {
return 1;
} else if (value <= 0x10FFFF) {
return 2;
}
/* out of bounds */
return 0;
}
/**
*
*/
size_t utf16_encode(char32_t in, char16_t *out)
{
size_t len = utf16_encode_length(in);
switch (len) {
case 1:
out[0] = in & 0xFFFF;
out[1] = 0x0000;
return 1;
case 2:
in -= 0x10000;
out[0] = 0xD800 | ((in >> 10) & 0x3FF);
out[1] = 0xDC00 | ((in >> 0) & 0x3FF);
return 2;
}
return 0;
}
// decode
size_t utf16_decode_length(char16_t first_word)
{
if (first_word < 0xD800 || first_word > 0xDFFF) {
return 1;
} else if (first_word >= 0xD800 && first_word <= 0xDBFF) {
return 2;
}
/* out of bounds */
return 0;
}
size_t utf16_decode(const char16_t *in, char32_t *out)
{
if (in[0] < 0xB800 || in[0] > 0xDFFF) {
out[0] = in[0];
return 1;
} else if ((in[0] >= 0xD800 && in[0] <= 0xD8FF)
&& (in[1] >= 0xDC00 && in[1] <= 0xDFFF)) { /* Surrogate Pair */
*out = (in[0] & 0x3FF) << 10;
*out |= (in[1] & 0x3FF) << 0;
*out += 0x10000;
return 2;
}
/* out of bounds */
return 0;
}
UTF-8
OK,千呼万唤始出来,终于到了UTF-8的讲解了。
其实,Unicode字符集在很长一段时间内并没有得到广泛的应用,直到互联网的普及,人们急需一种能够胜任网络传输的字符编码方案,为解决Unicode如何在网络上传输的问题,UTF-8应运而生。可以这么说,UTF-8是专为传输而设计的字符编码方案,大大推动了Unicode字符集的推广和应用。这里不得不提的是,UTF-8是Ken Thompson在餐厅的餐巾纸上设计出来的,没错,就是C语言之父这个大牛。
和UTF-16一样,UTF-8也是一种变长字符编码方案。下图是UTF-8的编码规则:
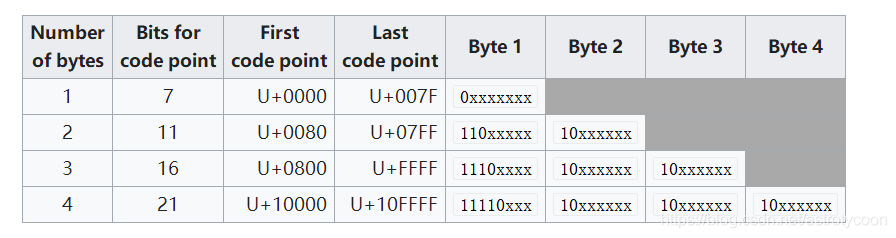
可以看到,UTF-8使用1 ~ 4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则其实很简单,只有两条如下(关于UTF-8的说明具体可以参阅RFC 3629文档):
(1)对于单字节的符号,字节的第一位设为0,后面7位是这个符号的Unicode代码点值。因此,对于英文字母,UTF-8字符编码和ASCII码是相同的,也就是说UTF-8是兼容ASCII字符编码的。
(2)对于n字节的符号(n > 1),第一个字节的前 n?位都是设置位1,?第n+1位设为0,后面字节的前两位一律设置位10。剩下的没有提及的二进制位,全部为这个符号的Unicode代码点值。
UTF-8是变长编码方式,因此得有个方法标记本UTF-8编码占据了多少字节。为叙述方便,我们把第一个字节称为高字节,其他字节称为低字节,把高字节和低字节中那些用以标记UTF-8特征的位称为标记位,除了标记位之外的其它存储数据的位称为数据位。 现在有两个问题需要搞清楚。
(1)为什么高字节的第n+1位是0 ?
UTF-8编码无论用多少字节,都必须要告之有几个字节,显然,高字节的标记位是随字节长度的不同而变化的(低字节的标记位始终是10,长度不变)。比如按照规则,2字节的UTF-8编码为了表示一共占了2字节,必须在高字节的高位用两个1表示占据了2个字节,但是如何正确读到这两个1呢??毕竟该字节的其余位(即数据位)也可以存储数据,即其余位也可以是1。为了区分数据位的1和标记位的1,在它们之间用0分隔。因此解码UTF-8时,只要从高字节的最高位开始往低位读,读入连续的1,直到遇到0为止,有几个1就表示本UTF-8编码所表示的数据占据了多少字节。?比如,对于2字节的UTF-8编码来说,其高字节的高3位必须是110,高字节的其余5位才用于存储数据,低字节的高2位是固定的10。同理,3字节的UTF-8编码为了表示占据了3个字节,高字节的高4位是1110,低字节的高2位始终是固定的10。