һ��find_element_by_id()
find_element_by_id()
1.�����涨λ����Ԫ�������У����Կ����и�id���ԣ�id=��kw�����������ͨ������id���Զ�λ�����Ԫ�ء�
2.��λ�����������send_keys()�������Ϳ��������ı���
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# ͨ��id��λ�ٶ����������'python'
ss = driver.find_element_by_id('kw')
ss.send_keys('python')
����find_element_by_name()
find_element_by_name()
1.�����涨λ����Ԫ�������У����Կ����и�name���ԣ�name=��wd�����������ͨ������name���Ե�λ�����Ԫ�ء�
˵�����������к�ᱨ����˵������������name���Բ���Ψһ�ģ���ͨ��name����ֱ�Ӷ�λ�������
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://www.baidu.com")
# ͨ��name��λ�ٶ����������'python'
ss = driver.find_element_by_name('wd')
ss.send_keys('python')
����find_element_by_class_name()
find_element_by_class_name()
1.�����涨λ����Ԫ�������У����Կ����и�class���ԣ�class=��s_ipt�����������ͨ������class���Զ�λ�����Ԫ�ء�
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#ͨ��class��λ�ٶ����������'python'
driver.find_element_by_class_name('s_ipt').send_keys('python')
�ġ�find_element_by_tag_name()
find_element_by_tag_name()
1.�����涨λ����Ԫ�������У����Կ���ÿ��Ԫ�ض���tag����ǩ�����ԣ���������ı�ǩ���ԣ�������ǰ���input��
2.�����ԣ���һ��ҳ���У���ͬ�ı�ǩ�кܶ࣬����һ�㲻�ñ�ǩ����λ���������ӣ������ο������⣬���п϶�������
from selenium import webdriver
driver = webdriver.Firefox()
driver.get('http://www.baidu.com')
#ͨ��tag(��ǩ)��λ�ٶ����������'python'
ss = driver.find_element_by_tag_name('input')
ss.send_keys('python')
�塢find_element_by_link_text()
1.��λ�ٶ�ҳ����"hao123"�����ť
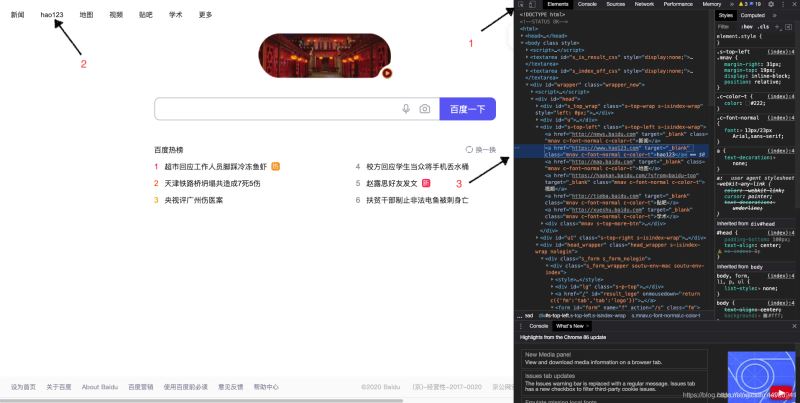
�鿴ҳ��Ԫ�أ�
<a class="mnav" target="_blank" href="http://www.hao123.com" rel="external nofollow" >hao123</a>
2.��Ԫ�����Կ��Է��������и�href = "http://www.hao123.com
˵�����Ǹ������ӣ���������Ԫ�أ����������·�����
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#ͨ��tlink(������)��λ�ٶ���������
driver.find_element_by_link_name('hao123').click()
����find_element_by_partial_link_text()
1.��ʱ��һ�������������ַ������ܱȽϳ����������ȫ�ƵĻ�������ʾ�ܳ�����ʱ�������һģ��ƥ�䷽ʽ����ȡ����һ�����ַ����Ϳ�����
2.�硰hao123��,ֻ�����롰ao123��Ҳ���Զ�λ��
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#ͨ��partial_link��λ�ٶ���������(partial_link��һ��ģ��ƥ��ķ�ʽ��
driver.find_element_by_partial_link_name('hao123').click()
�ߡ�find_element_by_xpath()
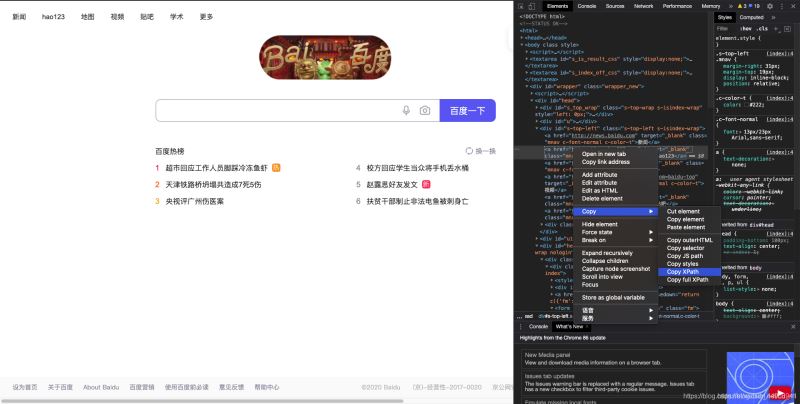
1.���϶�λ��ʽ����ͨ��Ԫ�ص�ij����������λ�ģ����һ��Ԫ������û��id��name��class����Ҳ���dz����ӣ���ô���أ�����˵�������Ժܶ��ظ��ġ����ʱ��Ϳ�����xpath�����
2.xpath��һ��·�����ԣ�������Ķ�λԭ����̫һ�������ȵ�һ��Ҫ��ѧ��鿴һ��Ԫ�ص�xpath��
- ���ڹȸ��������˵�����Լ� ��xpath�������ߣ�����Ƶ���Ҫ�鿴��htmlԴ���ϣ��һ�
- ѡ��copycopy
- xpath������Դ���xpath·��
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#ͨ��xpath��ַ��λ�ٶ���������(xpath��ַ��Ϊ��ֵ�����ĵ�ַ��
driver.find_element_by_xpath('//*[@]/a[2]').click()
�ˡ�find_element_by_css_selector()
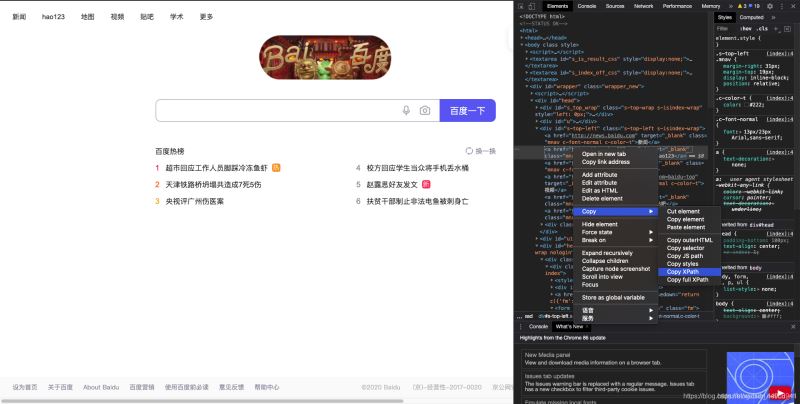
1.css������һ�������xpath��Ϊ��࣬���Dz�̫�����⡣������ѧ������ù��߲鿴�������Ľ̳������뽲��
���ڹȸ��������˵��ͬ�����Լ� ��css�������ߣ�����Ƶ���Ҫ�鿴��htmlԴ���ϣ��һ�
ѡ��copy
copy selector������Դ���css·��
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
#ͨ��css��ַ��λ�ٶ���������
driver.find_element_by_xpath('#s-top-left > a:nth-child(2)').click()
�ܽ
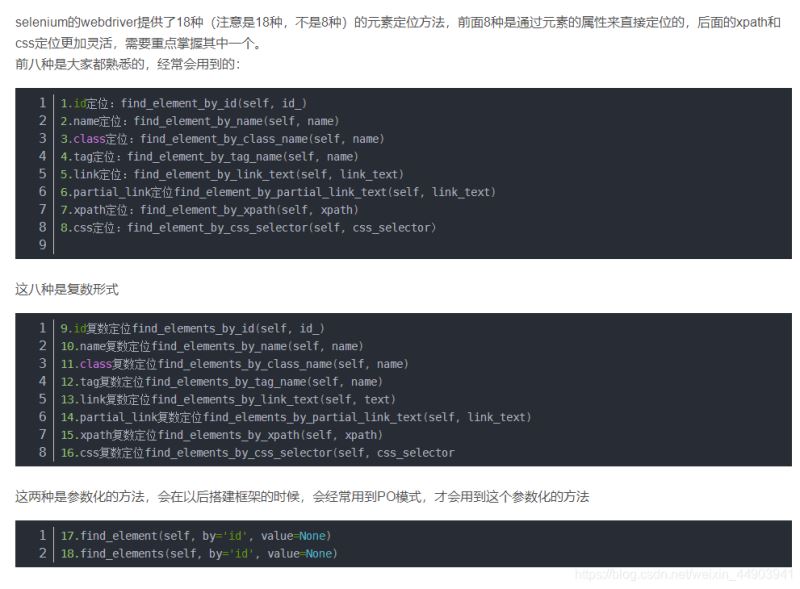
������ƪ����python�Զ����˴�λԪ�ؽ�������¾ͽ��ܵ�����,�������python�Զ����˴�λԪ������������վ��������ǰ�����»�������������������ϣ������Ժ���֧��վ�����ͣ�
jsjbwy