1. kubernetes Scheduler 简介
kubernetes Scheduler 运行在 master 节点,它的核心功能是监听 apiserver 来获取 PodSpec.NodeName 为空的 pod,然后为每个这样的 pod 创建一个 binding 指示 pod 应该调度到哪个节点上。
从哪里读取还没有调度的 pod 呢?当然是 apiserver。怎么知道 pod 没有调度呢?它会向 apiserver 请求 spec.nodeName 字段为空的 pod,然后调度得到结果之后,把结果写入 apiserver。
虽然调度的原理说起来很简单,但是要编写一个优秀的调度器却不容易,因为要考虑的东西很多:
尽可能地将 workload 平均到不同的节点,减少单个节点宕机造成的损失
可扩展性。随着集群规模的增加,怎么保证调度器不会成为性能的瓶颈
高可用。调度器能做组成集群,任何一个调度器出现问题,不会影响整个集群的调度
灵活性。不同的用户有不同的调度需求,一个优秀的调度器还要允许用户能配置不同的调度算法
资源合理和高效利用。调度器应该尽可能地提高集群的资源利用率,防止资源的浪费
和其他组件不同,scheduler 的代码在 plugin/ 目录下:plugin/cmd/kube-scheduler/ 是代码的 main 函数入口,plugin/pkg/scheduler/ 是具体调度算法。从这个目录结构也可以看出来,kube-scheduler 是作为插件接入到集群中的,它的最终形态一定是用户可以很容易地去定制化和二次开发的。
2. 代码分析
2.1 启动流程
虽然放到了 plugin/ 目录下,kube-scheduler 的启动过程和其他组件还是一样的,它会新建一个 SchedulerServer,这是一个保存了 scheduler 启动所需要配置信息的结构体,然后解析命令行的参数,对结构体中的内容进行赋值,最后运行 app.Run(s) 把 scheduler 跑起来。
plugin/cmd/kube-scheduler/scheduler.go:
func main() {
s := options.NewSchedulerServer()
s.AddFlags(pflag.CommandLine)
flag.InitFlags()
logs.InitLogs()
defer logs.FlushLogs()
verflag.PrintAndExitIfRequested()
app.Run(s)
}
app.Runs(s) 根据配置信息构建出来各种实例,然后运行 scheduler 的核心逻辑,这个函数会一直运行,不会退出。
plugin/cmd/kube-scheduler/app/server.go:
func Run(s *options.SchedulerServer) error {
......
configFactory := factory.NewConfigFactory(leaderElectionClient, s.SchedulerName, s.HardPodAffinitySymmetricWeight, s.FailureDomains)
config, err := createConfig(s, configFactory)
......
sched := scheduler.New(config)
run := func(_ <-chan struct{}) {
sched.Run()
select {}
}
......
......
}
Run 方法的主要逻辑是这样的:根据传递过来的参数创建 scheduler 需要的配置(主要是需要的各种结构体),然后调用 scheduler 的接口创建一个新的 scheduler 对象,最后运行这个对象开启调度代码。需要注意的是,config 这个对象也是在 configFactory 的基础上创建出来的。
了解 config 的创建和内容对后面了解调度器的工作原理非常重要,所以我们先来分下它的代码。
2.2 Config 的创建
factory.NewConfigFactory 方法会创建一个 ConfigFactory 的对象,这个对象里面主要是一些 ListAndWatch,用来从 apiserver 中同步各种资源的内容,用作调度时候的参考。此外,还有两个特别重要的结构体成员:PodQueue 和 PodLister,PodQueue 队列中保存了还没有调度的 pod,PodLister 同步未调度的 Pod 和 Pod 的状态信息。
plugin/pkg/scheduler/factory/factory.go:
func NewConfigFactory(client clientset.Interface, schedulerName string, hardPodAffinitySymmetricWeight int, failureDomains string) *ConfigFactory {
// schedulerCache 保存了 pod 和 node 的信息,是调度过程中两者信息的 source of truth
schedulerCache := schedulercache.New(30*time.Second, stopEverything)
informerFactory := informers.NewSharedInformerFactory(client, 0)
pvcInformer := informerFactory.PersistentVolumeClaims()
c := &ConfigFactory{
Client: client,
PodQueue: cache.NewFIFO(cache.MetaNamespaceKeyFunc),
ScheduledPodLister: &cache.StoreToPodLister{},
informerFactory: informerFactory,
// ConfigFactory 中非常重要的一部分就是各种 `Lister`,用来从获取各种资源列表,它们会和 apiserver 保持实时同步
NodeLister: &cache.StoreToNodeLister{},
PVLister: &cache.StoreToPVFetcher{Store: cache.NewStore(cache.MetaNamespaceKeyFunc)},
PVCLister: pvcInformer.Lister(),
pvcPopulator: pvcInformer.Informer().GetController(),
ServiceLister: &cache.StoreToServiceLister{Indexer: cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})},
ControllerLister: &cache.StoreToReplicationControllerLister{Indexer: cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})},
ReplicaSetLister: &cache.StoreToReplicaSetLister{Indexer: cache.NewIndexer(cache.MetaNamespaceKeyFunc, cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc})},
schedulerCache: schedulerCache,
StopEverything: stopEverything,
SchedulerName: schedulerName,
HardPodAffinitySymmetricWeight: hardPodAffinitySymmetricWeight,
FailureDomains: failureDomains,
}
// PodLister 和其他 Lister 创建方式不同,它就是 `schedulerCache`
c.PodLister = schedulerCache
// ScheduledPodLister 保存了已经调度的 pod, 即 `Spec.NodeName` 不为空且状态不是 Failed 或者 Succeeded 的 pod
// Informer 是对 reflector 的一层封装,reflect 把 ListWatcher 的结果实时更新到 store 中,而 informer 在每次更新的时候会调用对应的 handler 函数。
// 这里的 handler 函数把 store 中的 pod 数据更新到 schedulerCache 中
c.ScheduledPodLister.Indexer, c.scheduledPodPopulator = cache.NewIndexerInformer(
c.createAssignedNonTerminatedPodLW(),
&api.Pod{},
0,
cache.ResourceEventHandlerFuncs{
AddFunc: c.addPodToCache,
UpdateFunc: c.updatePodInCache,
DeleteFunc: c.deletePodFromCache,
},
cache.Indexers{cache.NamespaceIndex: cache.MetaNamespaceIndexFunc},
)
// 同上,把 node 的数据实时同步到 schedulerCache
c.NodeLister.Store, c.nodePopulator = cache.NewInformer(
c.createNodeLW(),
&api.Node{},
0,
cache.ResourceEventHandlerFuncs{
AddFunc: c.addNodeToCache,
UpdateFunc: c.updateNodeInCache,
DeleteFunc: c.deleteNodeFromCache,
},
)
......
return c
}
ConfigFactory 里面保存了各种 Lister,它们用来获取 kubernetes 中各种资源的信息,并且 schedulerCache 中保存了调度过程中需要用到的 pods 和 nodes 的最新信息。
然后,createConfig(s, configFactory) 根据配置参数和 configFactory 创建出真正被 scheduler 使用的 config 对象。
func createConfig(s *options.SchedulerServer, configFactory *factory.ConfigFactory) (*scheduler.Config, error) {
if _, err := os.Stat(s.PolicyConfigFile)
var (
policy schedulerapi.Policy
configData []byte
)
configData, err := ioutil.ReadFile(s.PolicyConfigFile)
......
if err := runtime.DecodeInto(latestschedulerapi.Codec, configData, &policy)
return nil, fmt.Errorf("invalid configuration: %v", err)
}
return configFactory.CreateFromConfig(policy)
}
return configFactory.CreateFromProvider(s.AlgorithmProvider)
}
createConfig 根据不同的配置有两种方式来创建 scheduler.Config:
通过 policy 文件:用户编写调度器用到的 policy 文件,控制调度器使用哪些 predicates 和 priorities 函数
通过 algorithm provider:已经在代码中提前编写好的 provider,也就是 predicates 和 priorities 函数的组合
这两种方法殊途同归,最终都是获取到 predicates 和 priorities 的名字,然后调用 CreateFromKeys 创建 Config 对象:
func (f *ConfigFactory) CreateFromKeys(predicateKeys, priorityKeys sets.String, extenders []algorithm.SchedulerExtender) (*scheduler.Config, error) {
// 获取所有的 predicates 函数
predicateFuncs, err := f.GetPredicates(predicateKeys)
// priority 返回的不是函数,而是 priorityConfigs。一是因为 priority 还包含了权重,二是因为 priority 的实现在迁移到 map-reduce 的方式
priorityConfigs, err := f.GetPriorityFunctionConfigs(priorityKeys)
// 两种 MetaProducer 都是用来获取调度中用到的 metadata 信息,比如 affinity、toleration,pod ports(用到的端口)、resource request(请求的资源)等
priorityMetaProducer, err := f.GetPriorityMetadataProducer()
predicateMetaProducer, err := f.GetPredicateMetadataProducer()
// 运行各种 informer 的内部逻辑,从 apiserver 同步资源数据到 Lister 和 cache 中
f.Run()
// 构造出 schedulerAlgorithm 对象,它最核心的方法是 `Schedule` 方法,我们会在下文说到
algo := scheduler.NewGenericScheduler(f.schedulerCache, predicateFuncs, predicateMetaProducer, priorityConfigs, priorityMetaProducer, extenders)
......
// 返回最终的 Config 对象
return &scheduler.Config{
SchedulerCache: f.schedulerCache,
NodeLister: f.NodeLister.NodeCondition(getNodeConditionPredicate()),
Algorithm: algo,
Binder: &binder{f.Client},
PodConditionUpdater: &podConditionUpdater{f.Client},
// NextPod 就是从 PodQueue 中取出 下一个未调度的 pod
NextPod: func() *api.Pod {
return f.getNextPod()
},
// 调度出错时的处理函数,会把 pod 重新加入到 podQueue 中,等待下一次调度
Error: f.makeDefaultErrorFunc(&podBackoff, f.PodQueue),
StopEverything: f.StopEverything,
}, nil
}
Config 的定义在文件 plugins/pkg/scheduler/scheduler.go 中。它把调度器的逻辑分成几个组件,提供了这些功能:
NextPod() 方法能返回下一个需要调度的 pod
Algorithm.Schedule() 方法能计算出某个 pod 在节点中的结果
Error() 方法能够在出错的时候重新把 pod 放到调度队列中进行重试
schedulerCache 能够暂时保存调度中的 pod 信息,占用着 pod 需要的资源,保证资源不会冲突
Binder.Bind 在调度成功之后把调度结果发送到 apiserver 中保存起来
后面可以看到 Scheduler 对象就是组合这些逻辑组件来完成最终的调度任务的。
Config 中的逻辑组件中,负责调度 pod 的是 Algorithm.Schedule() 方法。其对应的值是 GenericScheduler,GenericScheduler 是 Scheduler 的一种实现,也是 kube-scheduler 默认使用的调度器,它只负责单个 pod 的调度并返回结果:
plugin/pkg/scheduler/generic_scheduler.go
func NewGenericScheduler(
cache schedulercache.Cache,
predicates map[string]algorithm.FitPredicate,
predicateMetaProducer algorithm.MetadataProducer,
prioritizers []algorithm.PriorityConfig,
priorityMetaProducer algorithm.MetadataProducer,
extenders []algorithm.SchedulerExtender) algorithm.ScheduleAlgorithm {
return &genericScheduler{
cache: cache,
predicates: predicates,
predicateMetaProducer: predicateMetaProducer,
prioritizers: prioritizers,
priorityMetaProducer: priorityMetaProducer,
extenders: extenders,
cachedNodeInfoMap: make(map[string]*schedulercache.NodeInfo),
}
}
调度算法的接口只有一个方法:Schedule,第一个参数是要调度的 pod,第二个参数是能够获取 node 列表的接口对象。它返回一个节点的名字,表示 pod 将会调度到这台节点上。
plugin/pkg/scheduler/algorithm/scheduler_interface.go
type ScheduleAlgorithm interface {
Schedule(*api.Pod, NodeLister) (selectedMachine string, err error)
}
Config 创建出来之后,就是 scheduler 的创建和运行,执行最核心的调度逻辑,不断为所有需要调度的 pod 选择合适的节点:
sched := scheduler.New(config)
run := func(_ <-chan struct{}) {
sched.Run()
select {}
}
总结起来,configFactory、config 和 scheduler 三者的关系如下图所示:
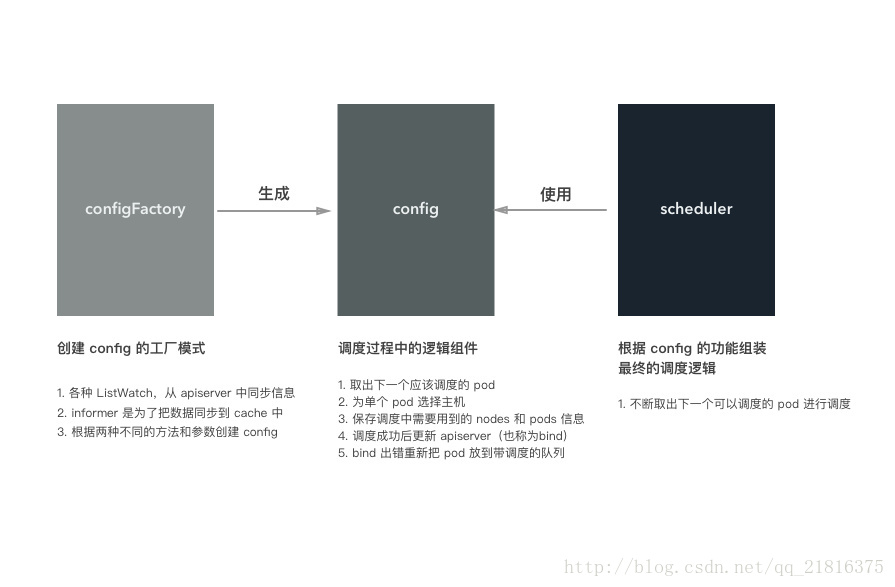
configFactory 对应工厂模式的工厂模型,根据不同的配置和参数生成 config,当然事先会准备好 config 需要的各种数据
config 是调度器中最重要的组件,里面实现了调度的各个组件逻辑
scheduler 使用 config 提供的功能来完成调度
如果把调度对比成做菜,那么构建 config 就相当于准备食材和调料、洗菜、对食材进行预处理。做菜就是把准备的食材变成美味佳肴的过程!
2.3 调度的逻辑
接着上面分析,看看 scheduler 创建和运行的过程。其对应的代码在 plugin/pkg/scheduler/scheduler.go 文件中:
// Scheduler 结构体本身非常简单,它把所有的东西都放到了 `Config` 对象中
type Scheduler struct {
config *Config
}
// 创建 scheduler 就是把 config 放到结构体中
func New(c *Config) *Scheduler {
s := &Scheduler{
config: c,
}
return s
}
func (s *Scheduler) Run() {
go wait.Until(s.scheduleOne, 0, s.config.StopEverything)
}
func (s *Scheduler) scheduleOne() {
pod := s.config.NextPod()
dest, err := s.config.Algorithm.Schedule(pod, s.config.NodeLister)
......
// assumed 表示已经为 pod 选择了 host,但是还没有在 apiserver 中创建绑定
// 这个状态的 pod 会单独保存在 schedulerCache 中,并暂时占住了节点上的资源
assumed := *pod
assumed.Spec.NodeName = dest
if err := s.config.SchedulerCache.AssumePod(&assumed)
return
}
// 异步对 pod 进行 bind 操作
go func() {
b := &api.Binding{
ObjectMeta: api.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name},
Target: api.ObjectReference{
Kind: "Node",
Name: dest,
},
}
err := s.config.Binder.Bind(b)
if err != nil {
// 绑定失败,删除 pod 的信息,占用的节点资源也被释放,可以让其他 pod 使用
if err := s.config.SchedulerCache.ForgetPod(&assumed)
glog.Errorf("scheduler cache ForgetPod failed: %v", err)
}
s.config.PodConditionUpdater.Update(pod, &api.PodCondition{
Type: api.PodScheduled,
Status: api.ConditionFalse,
Reason: "BindingRejected",
})
return
}
}()
}
scheduler.Run 就是不断调用 scheduler.scheduleOne() 每次调度一个 pod。
对应的调度逻辑如下图所示:
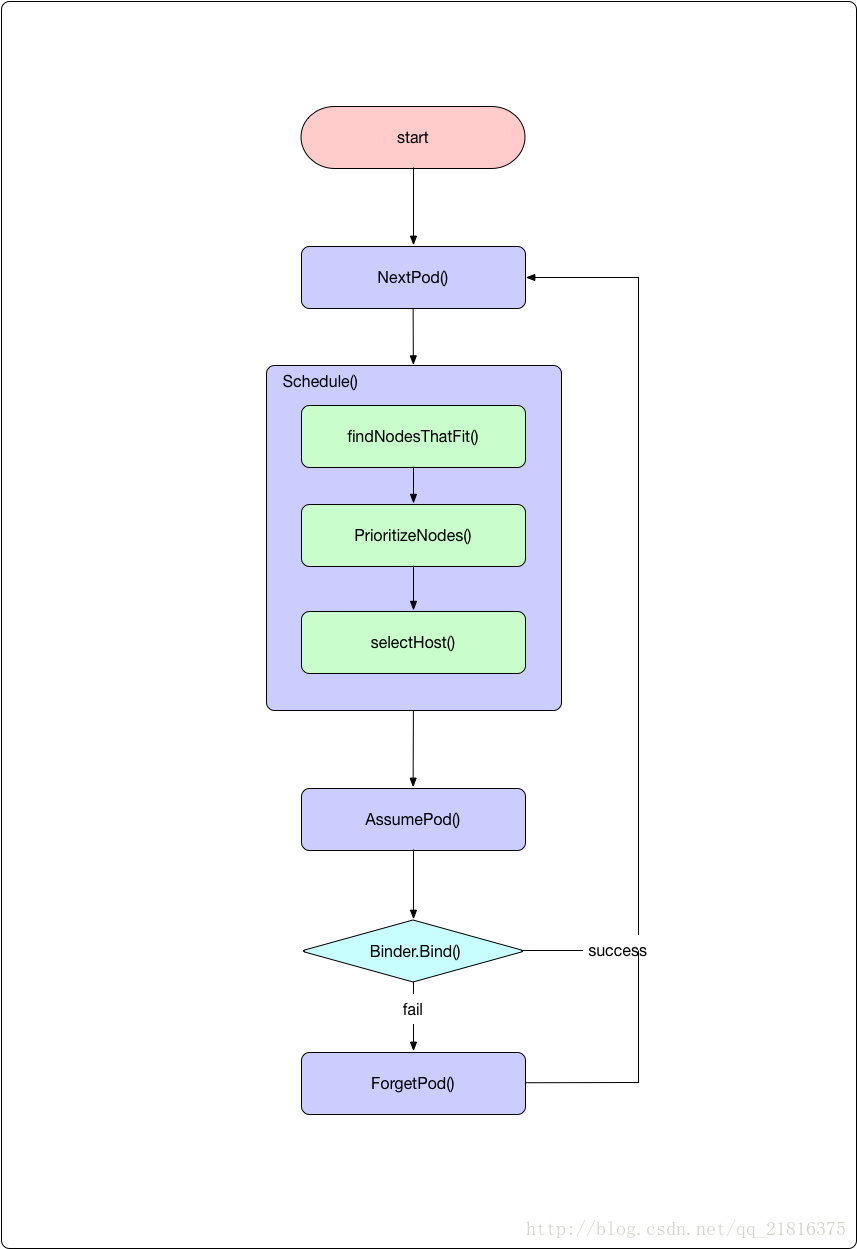
接下来我们逐步分解和解释。
2.3.1 下一个需要调度的 pod
NextPod 函数就是 configFactory.getNextPod(),它从未调度的队列中返回下一个应该由当前调度器调度的 pod。
它从 configFactory.PodQueue 中 pop 出来一个应该由当前调度器调度的 pod。当前 pod 可以通过 scheduler.alpha.kubernetes.io/name annotation 来设置调度器的名字,如果调度器名字发现这个名字和自己一致就认为 pod 应该由自己调度。如果对应的值为空,则默认调度器会进行调度。
PodQueue 是一个先进先出的队列:
PodQueue:cache.NewFIFO(cache.MetaNamespaceKeyFunc)
这个 FIFO 的实现代码在 pkg/client/cache/fifo.go 文件中。PodQueue 的内容是 reflector 从 apiserver 实时同步过来的,里面保存了需要调度的 pod(spec.nodeName 为空,而且状态不是 success 或者 failed):
func (f *ConfigFactory) Run() {
// Watch and queue pods that need scheduling.
cache.NewReflector(f.createUnassignedNonTerminatedPodLW(), &api.Pod{}, f.PodQueue, 0).RunUntil(f.StopEverything)
......
}
func (factory *ConfigFactory) createUnassignedNonTerminatedPodLW() *cache.ListWatch {
selector := fields.ParseSelectorOrDie("spec.nodeName==" + "" + ",status.phase!=" + string(api.PodSucceeded) + ",status.phase!=" + string(api.PodFailed))
return cache.NewListWatchFromClient(factory.Client.Core().RESTClient(), "pods", api.NamespaceAll, selector)
}
2.3.2 调度单个 pod
拿到 pod 之后,就调用具体的调度算法选择一个节点。
dest, err := s.config.Algorithm.Schedule(pod, s.config.NodeLister)
上面已经讲过,默认的调度算法就是 generic_scheduler,
它的代码在 plugin/pkg/scheduler/generic_scheduler.go 文件:
func (g *genericScheduler) Schedule(pod *api.Pod, nodeLister algorithm.NodeLister) (string, error) {
// 第一步:从 nodeLister 中获取 node 的信息
nodes, err := nodeLister.List()
......
// schedulerCache 中保存了调度用到的 pod 和 node 的最新数据,用里面的数据更新 `cachedNodeInfoMap`,作为调度过程中节点信息的参考
err = g.cache.UpdateNodeNameToInfoMap(g.cachedNodeInfoMap)
// 第二步:执行 predicate,过滤符合调度条件的节点
filteredNodes, failedPredicateMap, err := findNodesThatFit(pod, g.cachedNodeInfoMap, nodes, g.predicates, g.extenders, g.predicateMetaProducer)
if len(filteredNodes) == 0 {
return "", &FitError{
Pod: pod,
FailedPredicates: failedPredicateMap,
}
}
// 第三步:执行 priority,为符合条件的节点排列优先级
metaPrioritiesInterface := g.priorityMetaProducer(pod, g.cachedNodeInfoMap)
priorityList, err := PrioritizeNodes(pod, g.cachedNodeInfoMap, metaPrioritiesInterface, g.prioritizers, filteredNodes, g.extenders)
if err != nil {
return "", err
}
// 第四步:从最终的结果中选择一个节点
return g.selectHost(priorityList)
}
调度算法的过程分为四步骤:
获取必要的数据,这个当然就是 pod 和 nodes 信息。pod 是作为参数传递过来的,nodes 有两类,一个是通过 nodeLister 获取的节点信息,一类是 cachedNodeInfoMap。后一类节点信息中额外保存了资源的使用情况,比如节点上有多少调度的 pod、已经申请的资源、还可以分配的资源等
执行过滤操作。根据当前 pod 和 nodes 信息,过滤掉不适合运行 pod 的节点
执行优先级排序操作。对适合 pod 运行的节点进行优先级排序
选择节点。从最终优先级最高的节点中选择出来一个作为 pod 调度的结果
下面的几个部分就来讲讲过滤和优先级排序的过程。
2.3.3 过滤(Predicate):移除不合适的节点
调度器的输入是一个 pod(多个 pod 调度可以通过遍历来实现) 和多个节点,输出是一个节点,表示 pod 将被调度到这个节点上。
如何找到最合适 pod 运行的节点呢?第一步就是移除不符合调度条件的节点,这个过程 kubernetes 称为 Predicate,
过滤调用的函数是 findNodesThatFit,代码在 plugins/pkg/scheduler/generic_scheduler.go 文件中:
func findNodesThatFit(
pod *api.Pod,
nodeNameToInfo map[string]*schedulercache.NodeInfo,
nodes []*api.Node,
predicateFuncs map[string]algorithm.FitPredicate,
extenders []algorithm.SchedulerExtender,
metadataProducer algorithm.MetadataProducer,
) ([]*api.Node, FailedPredicateMap, error) {
var filtered []*api.Node
failedPredicateMap := FailedPredicateMap{}
if len(predicateFuncs) == 0 {
filtered = nodes
} else {
filtered = make([]*api.Node, len