前言
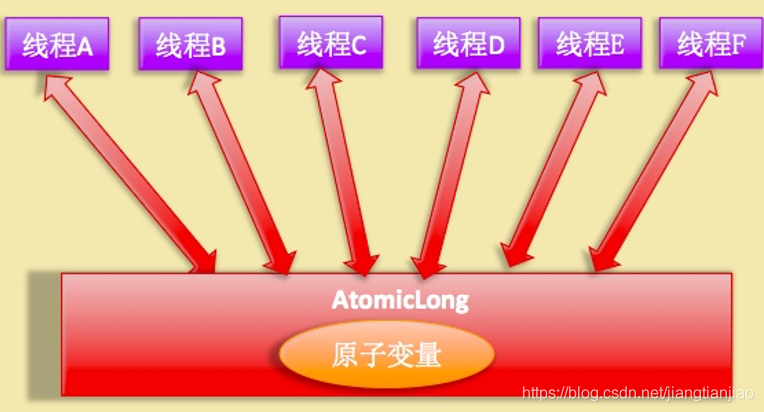
AtomicInteger、AtomicLong使用非阻塞的CAS算法原子性地更新某一个变量,比synchronized这些阻塞算法拥有更好的性能,但是在高并发情况下,大量线程同时去更新一个变量,由于同一时间只有一个线程能够成功,绝大部分的线程在尝试更新失败后,会通过自旋的方式再次进行尝试,严重占用了CPU的时间片。
AtomicLong的实现原理图:
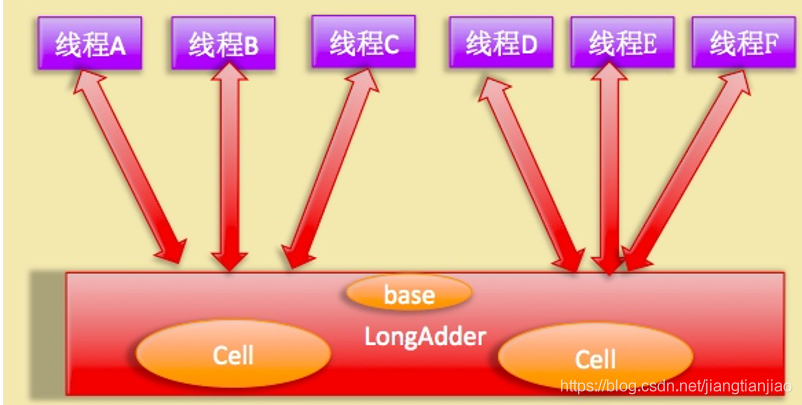
LongAdder是JDK8新增的原子操作类,它提供了一种新的思路,既然AtomicLong的性能瓶颈是由于大量线程同时更新一个变量造成的,那么能不能把这个变量拆分出来,变成多个变量,然后让线程去竞争这些变量,最后合并即可?LongAdder的设计精髓就在这里,通过将变量拆分成多个元素,降低该变量的并发度,最后进行合并元素,变相的减少了CAS的失败次数。
LongAdder的实现原理图:
常用方法
public class LongAdder extends Striped64 implements Serializable {
//构造方法
public LongAdder() {
}
//加1操作
public void increment();
//减1操作
public void decrement();
//获取原子变量的值
public long longValue();
}
下面给出一个简单的例子,模拟50线程同时进行更新
package com.xue.testLongAdder;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.LongAdder;
public class Main {
public static void main(String[] args) {
LongAdder adder = new LongAdder();
ExecutorService threadPool = Executors.newFixedThreadPool(20);
for (int i = 0; i < 50; i++) {
Runnable r = () -> {
adder.add(1);
};
threadPool.execute(r);
}
threadPool.shutdown();
//若关闭线程池后,所有任务执行完毕,则isTerminated()返回true
while (!threadPool.isTerminated()) {
System.out.println(adder.longValue());
break;
}
}
}
输出结果是50
其中,如果对线程池不熟悉的同学,可以先参考我的另外一篇文章说说线程池
原理解析
类图
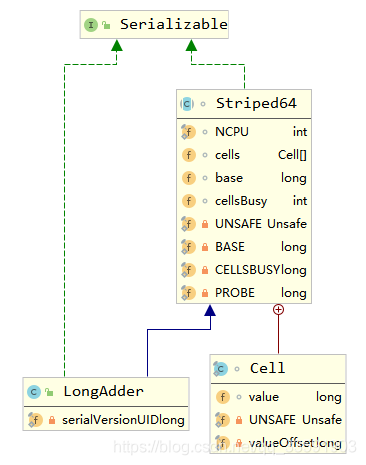
LongAdder内部维护了一个Cell类型的数组,其中Cell是Striped64中的一个静态内部类。
Cell类
abstract class Striped64 extends Number {
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
}
}
Cell用来封装被拆分出来的元素,内部用一个value字段保存当前元素的值,等到需要合并时,则累加所有Cell数组中的value。Cell内部使用CAS操作来更新value值,对CAS操作不熟悉的同学,可以参考我的另外一篇文章浅探CAS实现原理
可以注意到,Cell类被?@sun.misc.Contended注解修饰了,这个注解是为了解决伪共享问题的,什么是伪共享?
一个缓存行可以存储多个变量(存满当前缓存行的字节数);而CPU对缓存的修改又是以缓存行为最小单位的,在多线程情况下,如果需要修改“共享同一个缓存行的变量”,就会无意中影响彼此的性能,这就是伪共享(False Sharing)。
对伪共享还不理解的同学,可以参考这位大佬的文章伪共享(False Sharing)底层原理及其解决方式
而LongAdder采用的是Cell数组,而数组元素是连续的,因此多个Cell对象共享一个缓存行的情况非常普遍,因此这里@sun.misc.Contended注解对单个Cell元素进行字节填充,确保一个Cell对象占据一个缓存行,即填充至64字节。
关于如何确定一个对象的大小,可以参考我的另外一篇文章对象的内存布局,怎样确定对象的大小,这样可以算出来,还需要填充多少字节。
longValue()
longValue()返回累加后的值
public long longValue() {
return sum();
}
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
//当Cell数组不为null时,进行累加后返回,否则直接返回基准数base
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
这可能是LongAdder中最简单的方法了,就不进行赘述了。什么,你要看复杂的?好的,这就来了。
increment()
public void increment() {
add(1L);
}
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
/**
* 如果一下两种条件则继续执行if内的语句
* 1. cells数组不为null(不存在争用的时候,cells数组一定为null,一旦对base的cas操作失败,
* 才会初始化cells数组)
* 2. 如果cells数组为null,如果casBase执行成功,则直接返回,如果casBase方法执行失败
* (casBase失败,说明第一次争用冲突产生,需要对cells数组初始化)进入if内;
* casBase方法很简单,就是通过UNSAFE类的cas设置成员变量base的值为base+要累加的值
* casBase执行成功的前提是无竞争,这时候cells数组还没有用到为null,可见在无竞争的情况下是
* 类似于AtomticInteger处理方式,使用cas做累加。
*/
if ((as = cells) != null || !casBase(b = base, b + x)) {
//uncontended判断cells数组中,当前线程要做cas累加操作的某个元素是否#不#存在争用,
//如果cas失败则存在争用;uncontended=false代表存在争用,uncontended=true代表不存在争用。
boolean uncontended = true;
/**
*1. as == null : cells数组未被初始化,成立则直接进入if执行cell初始化
*2. (m = as.length - 1) < 0: cells数组的长度为0
*条件1与2都代表cells数组没有被初始化成功,初始化成功的cells数组长度为2;
*3. (a = as[getProbe() & m]) == null :如果cells被初始化,且它的长度不为0,
* 则通过getProbe方法获取当前线程Thread的threadLocalRandomProbe变量的值,初始为0,
* 然后执行threadLocalRandomProbe&(cells.length-1 ),相当于m%cells.length;
* 如果cells[threadLocalRandomProbe%cells.length]的位置为null,
* 这说明这个位置从来没有线程做过累加,
* 需要进入if继续执行,在这个位置创建一个新的Cell对象;
*4. !(uncontended = a.cas(v = a.value, v + x)):
* 尝试对cells[threadLocalRandomProbe%cells.length]位置的Cell对象中的value值做累加操作,
* 并返回操作结果,如果失败了则进入if,重新计算一个threadLocalRandomProbe;
如果进入if语句执行longAccumulate方法,有三种情况
1. 前两个条件代表cells没有初始化,
2. 第三个条件指当前线程hash到的cells数组中的位置还没有其它线程做过累加操作,
3. 第四个条件代表产生了冲突,uncontended=false
**/
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
其中longAccumulate()的解析如下:
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
//获取当前线程的threadLocalRandomProbe值作为hash值,如果当前线程的threadLocalRandomProbe为0,
// 说明当前线程是第一次进入该方法,则强制设置线程的threadLocalRandomProbe为ThreadLocalRandom类的成员
// 静态私有变量probeGenerator的值,后面会详细将hash值的生成;
//另外需要注意,如果threadLocalRandomProbe=0,代表新的线程开始参与cell争用的情况
//1.当前线程之前还没有参与过cells争用(也许cells数组还没初始化,进到当前方法来就是为了初始化cells数组
//后争用的),
// 是第一次执行base的cas累加操作失败;
//2.或者是在执行add方法时,对cells某个位置的Cell的cas操作第一次失败,则将wasUncontended设置为false,
// 那么这里会将其重新置为true;第一次执行操作失败;
//凡是参与了cell争用操作的线程threadLocalRandomProbe都不为0;
int h;
if ((h = getProbe()) == 0) {
//初始化ThreadLocalRandom;
ThreadLocalRandom.current(); // force initialization
//将h设置为0x9e3779b9
h = getProbe();
//设置未竞争标记为true
wasUncontended = true;
}
//cas冲突标志,表示当前线程hash到的Cells数组的位置,做cas累加操作时与其它线程发生了冲突,cas失败;
// collide=true代表有冲突,collide=false代表无冲突
boolean collide = false;
for (;;) {
Cell[] as; Cell a; int n; long v;
//这个主干if有三个分支
//1.主分支一:处理cells数组已经正常初始化了的情况(这个if分支处理add方法的四个条件中的3和4)
//2.主分支二:处理cells数组没有初始化或者长度为0的情况;(这个分支处理add方法的四个条件中的1和2)
//3.主分支三:处理如果cell数组没有初始化,并且其它线程正在执行对cells数组初始化的操作,
// 及cellbusy=1;
// 则尝试将累加值通过cas累加到base上
//先看主分支一
if ((as = cells) != null && (n = as.length) > 0) {
/**
*内部小分支一:这个是处理add方法内部if分支的条件3:如果被hash到的位置为null,
* 说明没有线程在这个位置设置过值,
* 没有竞争,可以直接使用,则用x值作为初始值创建一个新的Cell对象,
* 对cells数组使用cellsBusy加锁,
* 然后将这个Cell对象放到cells[m%cells.length]位置上
*/
if ((a = as[(n - 1) & h]) == null) {
//cellsBusy == 0 代表当前没有线程cells数组做修改
if (cellsBusy == 0) {
//将要累加的x值作为初始值创建一个新的Cell对象,
Cell r = new Cell(x);
//如果cellsBusy=0无锁,则通过cas将cellsBusy设置为1加锁
if (cellsBusy == 0 && casCellsBusy()) {
//标记Cell是否创建成功并放入到cells数组被hash的位置上
boolean created = false;
try {
Cell[] rs; int m, j;
//再次检查cells数组不为null,且长度不为空,且hash到的位置的Cell为null
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
//将新的cell设置到该位置
rs[j] = r;
created = true;
}
} finally {
//去掉锁
cellsBusy = 0;
}
//生成成功,跳出循环
if (created)
break;
//如果created为false,说明上面指定的cells数组的位置cells[m%cells.length]
// 已经有其它线程设置了cell了,
// 继续执行循环。
continue;
}
}
//如果执行的当前行,代表cellsBusy=1,有线程正在更改cells数组,代表产生了冲突,将collide设置为false
collide = false;
/**
*内部小分支二:如果add方法中条件4的通过cas设置cells[m%cells.length]位置的Cell对象中的
* value值设置为v+x失败,
* 说明已经发生竞争,将wasUncontended设置为true,跳出内部的if判断,
* 最后重新计算一个新的probe,然后重新执行循环;
*/
} else if (!wasUncontended)
//设置未竞争标志位true,继续执行,后面会算一个新的probe值,然后重新执行循环。
wasUncontended = true;
/**
*内部小分支三:新的争用线程参与争用的情况:处理刚进入当前方法时threadLocalRandomProbe=0的情况,
* 也就是当前线程第一次参与cell争用的cas失败,这里会尝试将x值加到cells[m%cells.length]
* 的value ,如果成功直接退出
*/
else if (a.cas(v = a.value, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
/**
*内部小分支四:分支3处理新的线程争用执行失败了,这时如果cells数组的长度已经到了最大值
* (大于等于cup数量),
* 或者是当前cells已经做了扩容,则将collide设置为false,后面重新计算prob的值*/
else if (n >= NCPU || cells != as)
collide = false;
/**
*内部小分支五:如果发生了冲突collide=false,则设置其为true;会在最后重新计算hash值后,
* 进入下一次for循环
*/
else if (!collide)
//设置冲突标志,表示发生了冲突,需要再次生成hash,重试。
// 如果下次重试任然走到了改分支此时collide=true,!collide条件不成立,则走后一个分支
collide = true;
/**
*内部小分支六:扩容cells数组,新参与cell争用的线程两次均失败,且符合库容条件,会执行该分支
*/
else if (cellsBusy == 0 && casCellsBusy()) {
try {
//检查cells是否已经被扩容
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
//为当前线程重新计算hash值
h = advanceProbe(h);
//这个大的分支处理add方法中的条件1与条件2成立的情况,如果cell表还未初始化或者长度为0,
// 先尝试获取cellsBusy锁。
}else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
//初始化cells数组,初始容量为2,并将x值通过hash&1,放到0个或第1个位置上
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
//解锁
cellsBusy = 0;
}
//如果init为true说明初始化成功,跳出循环
if (init)
break;
}
/**
*如果以上操作都失败了,则尝试将值累加到base上;
*/
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
// Fall back on using base
break;
}
}
以上2个方法的解析搬自于源码阅读:全方位讲解LongAdder,此处对代码做了微调,方便阅读。
总结
LongAdder在没有线程竞争的时候,只使用base值,此时的情况就类似与AtomicLong。但LongAdder的高明之处在于,发生线程竞争时,便会使用到Cell数组,所以该数组是惰性加载的。
Cell数组初始值为2,每次扩容(当线程竞争异常激烈时,发生扩容)为上次长度的2倍,因此数组长度一直是2的次幂,但是当数组长度≥CPU的核心数时,就不再进行扩容。为什么?我的理解是在一台电脑中,最多能有CPU核心数个线程能够并行,因此同时也就这么多个线程操作Cell数组,每个线程更新一个位置上的元素,且又因为数组中每个元素由于字节填充机制,十分的占据内存。考虑到这两个因素,Cell数组在长度≥CPU核心数时,停止扩容。
确实,LongAdder花了很多心思提高了高并发下程序运行的效率,每一步都是在没有更好的办法下才会去选择开销更大的操作。在低并发下,LongAdder和AtomicLong效率上差不多,但LongAdder更加耗费内存。不过在高并发下,LongAdder将更加高效。
cs