ФПТМ
- 1. ГЃгУЕФБрТы
- 2.ВЙГф:МЦЫуЛњБэЪОЕФЕЅЮЛЃК
- 3.ASCIIБрТы
- 2.GBKКЭGB2312БрТы
- 4.Unicode
- 5.UTF-8БрТы
- 6.БрТыКЭНтТы
1. ГЃгУЕФБрТы
- ASCII:жЛФмБэЪОвЛаЉзжФИЃЌЪ§зжКЭЬиЪтЕФзжЗћЃЌеМвЛИізжНк
- GBKЃКЙњМвМђЬхжаЮФзжЗћМЏКЭЗБЬхзжЗћМЏЃЌМцШнASCIIЃЌеМСНИізжНк
- UnicodeЃКФмЙЛБэЪОШЋЪРНчЩЯЫљгаЕФзжЗћЃЌUnicodeгаШЫЫЕеМ4ИізжНквВгаШЫЫЕеМ2ИізжНкЃЌЕЋжаЮФеМ2ИізжНк
- UTF-8ЃКUnicodeЕФбЙЫѕАцЃЌеМ1~3ИізжНкЃЌЦфжажаЮФеМШ§ИізжНк
2.ВЙГф:МЦЫуЛњБэЪОЕФЕЅЮЛЃК
bitЃК ЮЛЃЌМЦЫуЛњзюаЁЕФБэЪОЕЅЮЛ
bytesЃКзжНкЃЌзюаЁЕФДцДЂЕЅЮЛЃЌ1bytes=8bitЃЌ1bytesМђаДГЩ1B
1KB = 1024B
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
......
3.ASCIIБрТы
ASCIIБрТыЪЧЛљгкРЖЁзжФИвЛЬзБрТыЃЌжївЊЪЧЯдЪОЯжДњгЂгяКЭЦфЮїХЗгябдЃЌЪЧзюдчЭЈгУЕФЕЅзжНкБрТыЯЕЭГ,ОпЬхASCIIЖдееБэШчЯТЃК
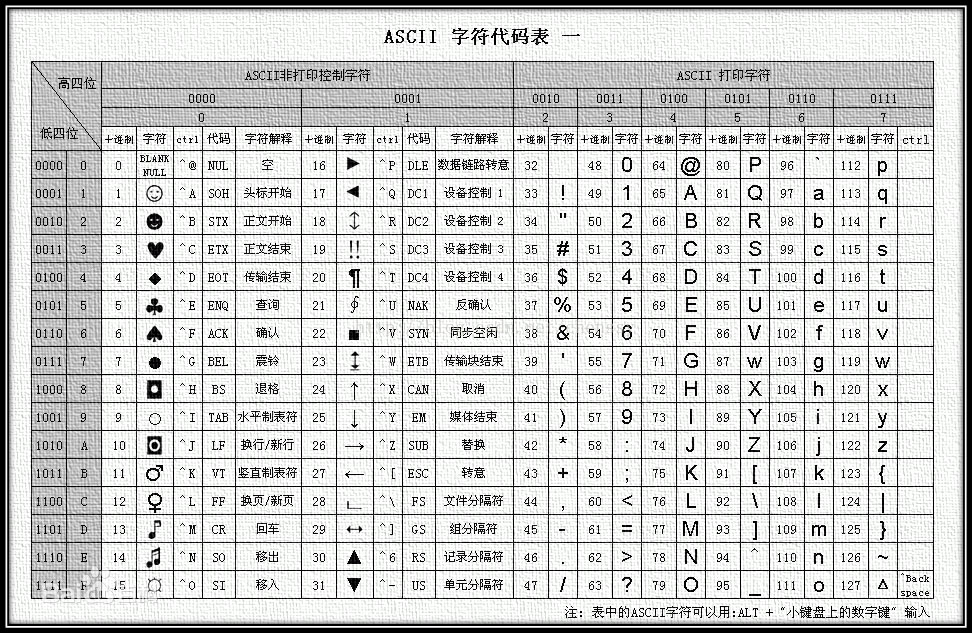
дкЖдееБэжаашвЊМЧзЁЕФЪЧДѓаДзжФИAЕФБрТыЪЧ65ЃЌаЁаДзжФИaЕФБрТыЕФ97МДПЩЁЃ
дкpythonжаПЩвдЪЙгУchrКЭordЗНЗЈНјаазЊЛЛЃК
# НЋЪ§зжРраЭзЊЛЛГЩASCIIЖдгІЕФзжЗћ
print(chr(97)) # a
# НЋЪ§зжзЊЛЛГЩЖдгІЕФЪ§Он
print(ord("A")) # 65
# ЛђепЪЙгУ
ЕЋЫцзХЪТМўЕФЗЂеЙЃЌASCIIБрТыРЉеЙЕНСЫ256ИізжЗћЃЌБрТы ЖдееБэШчЯТЃК

ЦфжаКѓ128ИізжЗћГЦЮЊРЉеЙASCIIТы
2.GBKКЭGB2312БрТы
гЩгкASCIIБрТыжЛФмгЩ256ИізжЗћзщГЩЃЌШЛжЛФмгЩ1ИізжНкРДБэЪОжаЮФЪЧВЛПЩФмЕФЃЌвђДЫжЦЖЈСЫGB2312БрТыЃЌгУРДБэЪОжаЮФЕФЖдееБэ
4.Unicode
ЮЊСЫНтОіИїИіЙњМвБрТыГхЭЛЕФЮЪЬтЃЌUnicodeБрТыОЭвђДЫЖјЩњЃЌUnicodeАбЫљгагябдЖМЭГвЛЕНвЛЬзБрТыРяУцЃЌОЭЛсБмУтГхЭЛЃЌВњЩњТвТыЁЃ
UnicodebБъзМдкВЛЖЯЗЂеЙЃЌзюГЃгУЕФЪЧгУСНИізжНкБэЪОвЛИізжЗћЃЌвВгаЕФзжЗћЪЧ4ИізжНкЃЌЕЋЪЧжаЮФЪЧеМСНИізжНкЁЃШчЙћЭГвЛГЩUnicodeБрТыЃЌдкДцДЂКЭДЋЪфЩЯОЭВЛЛЎЫу
5.UTF-8БрТы
ЮЊСЫНтОіUnicodeБрТыДцДЂЙ§ДѓЕФЮЪЬтЃЌОЭЭЦГіСЫПЩБфГЄБрТыUTF-8ЃЌUTF-8БрТыАбвЛИіUnicodeзжЗћвРОнВЛЭЌЕФЪ§ОнДѓаЁБрГЬ1~6ИізжНкЃЌЦфжажаЮФОЭеМ3ИізжНк
6.БрТыКЭНтТы
1.БрТыВйзї
ПЩвдЭЈЙ§encodeНјааБрТыЃЌЦфжагяЗЈШчЯТЃК
ЖдзжЗћДЎНјааASCIIБрТы(жЛФмзЊЛЛЪ§зжЃЌгЂЮФзжФИКЭвЛаЉЗћКХ)
# ЗНЪН1ЃК ЭЈЙ§bytesЗНЗЈ
bytes('a', 'ASCII')
# ЗНЪН2: ЭЈЙ§encodeЗНЗЈНјаа
'a'.encode('ASCII')
НЋзжЗћДЎзЊЛЛГЩgbkБрТыИёЪН
# ЗНЪН1: ЭЈЙ§encodeЗНЗЈНјаа
print('ФуКУ'.encode('GBK')) # БрТыжЎКѓЕФНсЙћЮЊ:b'\xc4\xe3\xba\xc3'
# ЗНЪН2: ЭЈЙ§bytesРраЭ
print(bytes('ЮвАЎФу', 'GBK')) # БрТыжЎКѓЕФНсЙћЮЊ:b'\xce\xd2\xb0\xae\xc4\xe3'
НЋзжЗћДЎзЊЛЛГЩUnicodeБрТыИёЪН
# ЗНЪН1: ЭЈЙ§encodeЗНЗЈНјаа
print('ФуКУ'.encode('unicode_escape')) # БрТыжЎКѓЕФНсЙћЮЊ:b'\\u4f60\\u597d'
# ЗНЪН2: ЭЈЙ§bytesРраЭ
print(bytes('ЮвАЎФу', 'unicode_escape')) # БрТыжЎКѓЕФНсЙћЮЊ:b'\\u6211\\u7231\\u4f60'
НЋзжЗћДЎзЊЛЛГЩUTF-8БрТыИёЪН
# ЗНЪН1: ЭЈЙ§encodeЗНЗЈНјаа
print('ФуКУ'.encode('utf-8')) # БрТыжЎКѓЕФНсЙћЮЊ:b'\xe4\xbd\xa0\xe5\xa5\xbd'
# ЗНЪН2: ЭЈЙ§bytesРраЭ
print(bytes('ЮвАЎФу', 'utf-8')) # БрТыжЎКѓЕФНсЙћЮЊ:b'\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'
2.НтТыВйзї
НЋGBKБрТыИёЪНзЊЛЛГЩзжЗћДЎ
# ЭЈЙ§decodeЗНЗЈНтТы
print(b'\xc4\xe3\xba\xc3\xce\xd2\xb0\xae\xc4\xe3'.decode('GBK')) # НтТыжЎКѓНсЙћЮЊЃКФуКУЮвАЎФу
НЋUTF-8БрТыИёЪНзЊЛЛГЩзжЗћДЎ
# ЭЈЙ§decodeЗНЗЈНтТы
print(b'\xe4\xbd\xa0\xe5\xa5\xbd\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0'.decode('utf-8')) # НтТыжЎКѓНсЙћЮЊЃКФуКУЮвАЎФу
НЋUnicondeБрТыИёЪНзЊЛЛГЩзжЗћДЎ
# ЭЈЙ§decodeЗНЗЈНтТы
print(b'\\u4f60\\u597d\\u6211\\u7231\\u4f60'.decode('GBK')) # НтТыжЎКѓНсЙћЮЊЃКФуКУЮвАЎФу
jsjbwy