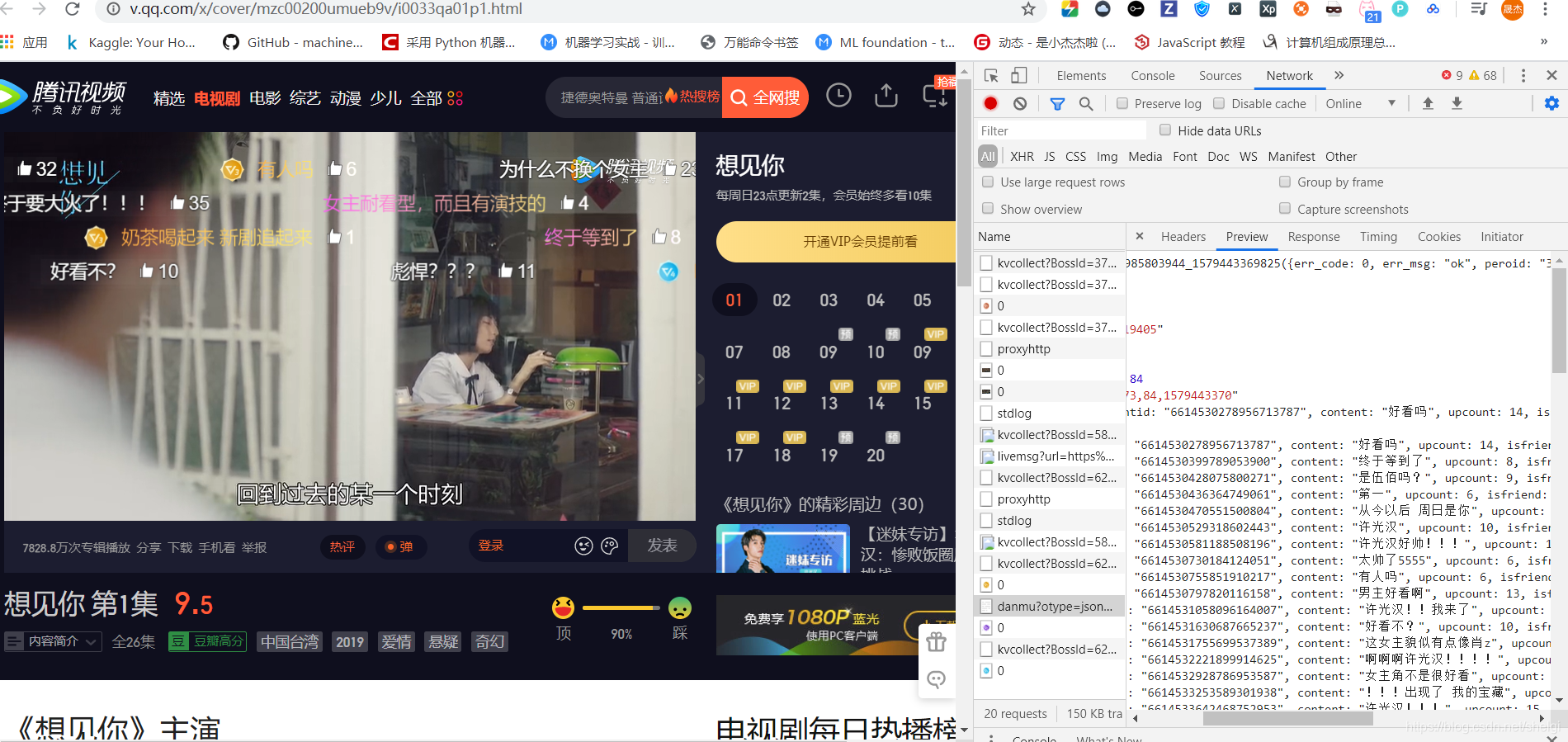
Ȼ�����Ҫ�ҵ�ÿһ����Ӧ��target_id��v_id���ܵõ�ÿһ���ĵ�Ļ,������ȥ������������Щtarget_id��v_id��
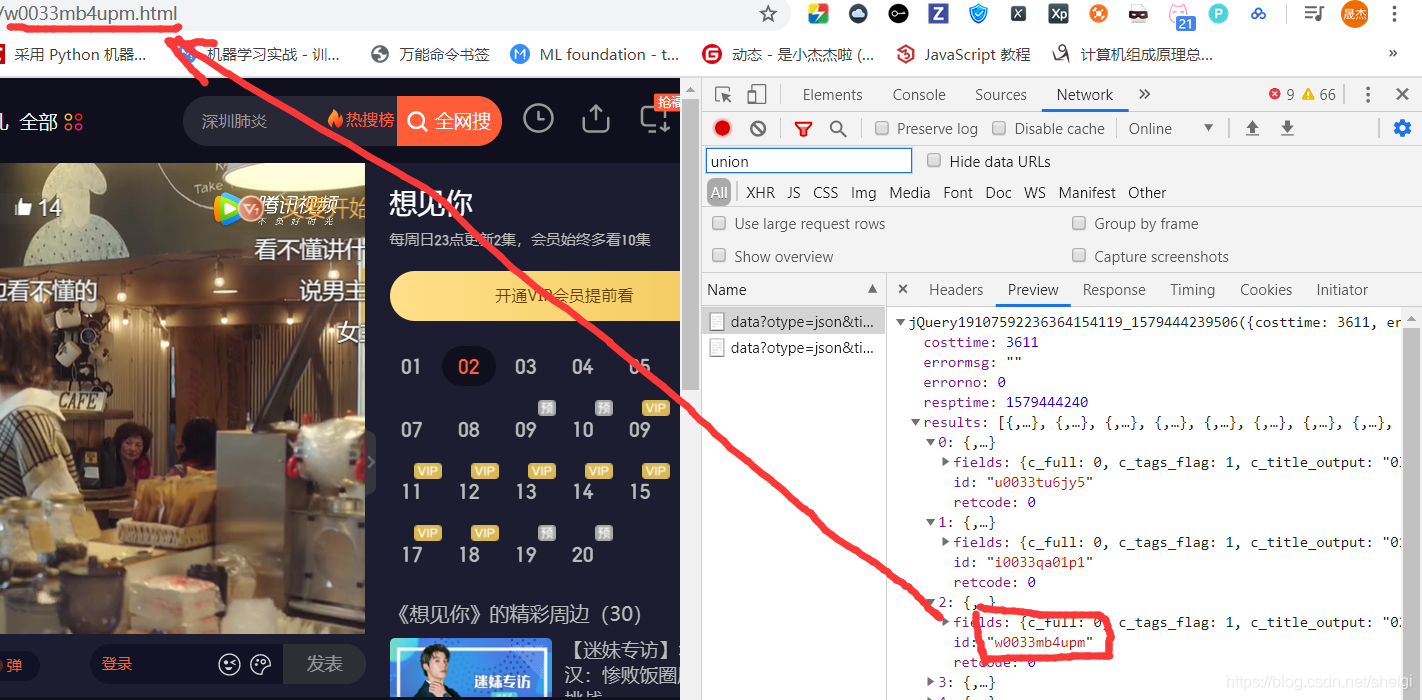
����͵õ���v_id,Ȼ����ȥͨ��v_id,post�õ�target_id
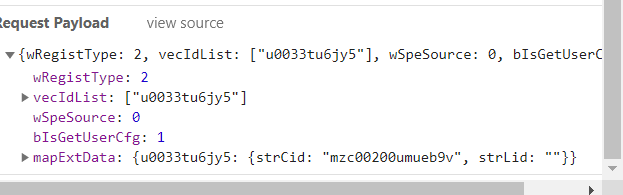
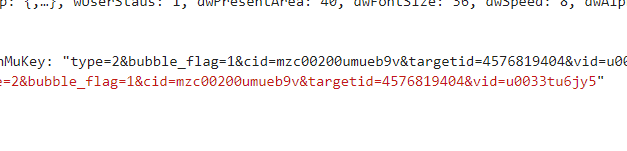
���˼·��������,������������Ҫ�����õ����С�
֮ǰҲ�����˱���д����ȡ��Ѷ��Ƶ��Ļ�Ĵ���,������������,������������ϸij�������Ҫ��,���������:
import requests
import json
import pandas as pd
import time
import random
def parse_base_info(url, headers):
df = pd.DataFrame()
html = requests.get(url, headers=headers)
bs = json.loads(html.text[html.text.find('{'):-1])
for i in bs['results']:
v_id = i['id']
title = i['fields']['title']
view_count = i['fields']['view_all_count']
episode = int(i['fields']['episode'])
if episode == 0:
pass
else:
cache = pd.DataFrame({'id': [v_id], 'title': [title], '������': [view_count], '�ڼ���': [episode]})
df = pd.concat([df, cache])
return df
def get_episode_danmu(v_id, headers):
base_url = 'https://access.video.qq.com/danmu_manage/regist?vappid=97767206&vsecret=c0bdcbae120669fff425d0ef853674614aa659c605a613a4&raw=1'
pay = {"wRegistType": 2, "vecIdList": [v_id],
"wSpeSource": 0, "bIsGetUserCfg": 1,
"mapExtData": {v_id: {"strCid": "mzc00200umueb9v", "strLid": ""}}}
html = requests.post(base_url, data=json.dumps(pay), headers=headers)
bs = json.loads(html.text)
danmu_key = bs['data']['stMap'][v_id]['strDanMuKey']
target_id = danmu_key[danmu_key.find('targetid') + 9: danmu_key.find('vid') - 1]
return [v_id, target_id]
def parse_danmu(url, target_id, v_id, headers, period):
html = requests.get(url, headers=headers)
bs = json.loads(html.text, strict=False)
df = pd.DataFrame()
try:
for i in bs['comments']:
content = i['content']
name = i['opername']
upcount = i['upcount']
user_degree = i['uservip_degree']
timepoint = i['timepoint']
comment_id = i['commentid']
cache = pd.DataFrame({'�û���': [name], '����': [content], '��Ա�ȼ�': [user_degree],
'��Ļʱ���': [timepoint], '��Ļ����': [upcount], '��Ļid': [comment_id], '����': [period]})
df = pd.concat([df, cache])
except:
pass
return df
def format_url(target_id, v_id, page=85):
urls = []
base_url = 'https://mfm.video.qq.com/danmu?otype=json×tamp={}&target_id={}%26vid%3D{}&count=400&second_count=5'
for num in range(15, page * 30 + 15, 30):
url = base_url.format(num, target_id, v_id)
urls.append(url)
return urls
def get_all_ids(part1_url,part2_url, headers):
part_1 = parse_base_info(part1_url, headers)
part_2 = parse_base_info(part2_url, headers)
df = pd.concat([part_1, part_2])
df.sort_values('�ڼ���', ascending=True, inplace=True)
count = 1
info_lst = []
for i in df['id']:
info = get_episode_danmu(i, headers)
info_lst.append(info)
print('����Ŭ����ȡ�� %d ����target_id' % count)
count += 1
time.sleep(2 + random.random())
print('�Dz��Ƿ��ֶ���һ��?����,��ȥ�ص�'