ДҝВј
- Т»ЎўCrawlSpiderАаҪйЙЬ
- ¶юЎў°ёАэЈә№ЕК«ОДНшИ«ХҫКэҫЭЕАИЎ
- 2.1 ЕАіжОДјю
- 2.2 itemОДјю
- 2.3 №ЬөАОДјю
- 2.4 ЕдЦГОДјю
- 2.5 КдіцҪб№ы
Т»ЎўCrawlSpiderАаҪйЙЬ
1.1 ТэИл
К№УГscrapyҝтјЬҪшРРИ«ХҫКэҫЭЕАИЎҝЙТФ»щУЪSpiderАаЈ¬ТІҝЙТФК№УГҪУПВАҙУГөҪөДCrawlSpiderАаЎЈ»щУЪSpiderАаөДИ«ХҫКэҫЭЕАИЎЦ®З°ҫЩ№эАхЧУЈ¬ёРРЛИӨөДҝЙТФҝөҝө
scrapy»щУЪCrawlSpiderАаөДИ«ХҫКэҫЭЕАИЎ
1.2 ҪйЙЬәНК№УГ
1.2.1 ҪйЙЬ
CrawlSpiderКЗSpiderөДТ»ёцЧУАаЈ¬ТтҙЛCrawlSpiderіэБЛјМіРSpiderөДМШРФәН№ҰДЬНвЈ¬»№УРЧФјәМШУРөД№ҰДЬЈ¬ЦчТӘУГөҪөДКЗ LinkExtractor()әНrules = (Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),)
LinkExtractor()ЈәБҙҪУМбИЎЖч
LinkExtractor()ҪУКЬresponse¶ФПуЈ¬ІўёщҫЭallow¶ФУҰөДХэФтұнҙпКҪМбИЎПмУҰ¶ФПуЦРөДБҙҪУ
link = LinkExtractor(
# ItemsЦ»ДЬКЗТ»ёцХэФтұнҙпКҪ,»бМбИЎөұЗ°ТіГжЦРВъЧгёГ"ХэФтұнҙпКҪ"өДurl
ЎЎ allow=r'Items/'
)
rules = (Rule(link, callback='parse_item', follow=True),)Јә№жФтҪвОцЖч
°ҙХХЦё¶Ё№жФтҙУБҙҪУМбИЎЖчЦРМбИЎөҪөДБҙҪУЦРҪвОцНшТіКэҫЭ
linkЈәКЗТ»ёцLinkExtractor()¶ФПуЈ¬Цё¶ЁБҙҪУМбИЎЖч
callbackЈә»ШөчәҜКэЈ¬Цё¶Ё№жФтҪвОцЖч(ҪвОц·Ҫ·Ё)ҪвОцКэҫЭ
followЈәКЗ·сҪ«БҙҪУМбИЎЖчјМРшЧчУГөҪБҙҪУМбИЎЖчМбИЎіцөДБҙҪУНшТіЦР
import scrapy
# өјИлПа№ШөД°ь
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class TextSpider(CrawlSpider):
name = 'text'
allowed_domains = ['www.xxx.com']
start_urls = ['http://www.xxx.com/']
# БҙҪУМбИЎЖч,ҙУҪУКЬөҪөДresponse¶ФПуЦР,ёщҫЭitemХэФтұнҙпКҪМбИЎТіГжЦРөДБҙҪУ
link = LinkExtractor(allow=r'Items/')
link2 = LinkExtractor(allow=r'Items/')
# №жФтҪвОцЖч,ёщҫЭcallbackҪ«БҙҪУМбИЎЖчМбИЎөҪөДБҙҪУҪшРРКэҫЭҪвОц
# followОӘtrue,ФтұнКҫҪ«БҙҪУМбИЎЖчјМРшЧчУГөҪБҙҪУМбИЎЖчЛщМбИЎөҪөДБҙҪУТіГжЦР
# №К:ФЪОТГЗМбИЎ¶аТіКэҫЭКұ,ИфөЪТ»Ті¶ФУҰөДНшТіЦР°ьә¬БЛөЪ2,3,4,5ТіөДБҙҪУ,
# өұМшЧӘөҪөЪ5ТіКұ,өЪ5ТіУЦ°ьә¬БЛөЪ6,7,8,9ТіөДБҙҪУ,
# Боfollow=True,ҫНҝЙТФіЦРшЧчУГ,ҙУ¶шМбИЎөҪЛщУРТіГжөДБҙҪУ
rules = (Rule(link, callback='parse_item', follow=True),
Rule(link2,callback='parse_content',follow=False))
# БҙҪУМбИЎЖчlinkК№УГparse_itemҪвОцКэҫЭ
def parse_item(self, response):
item = {}
yield item
# БҙҪУМбИЎЖчlink2К№УГparse_contentҪвОцКэҫЭ
def parse_content(self, response):
item = {}
yield item
1.2.2 К№УГ
ҙҙҪЁЕАіжОДјюЈәіэБЛҙҙҪЁЕАіжОДјюІ»Н¬НвЈ¬ҙҙҪЁПоДҝәНФЛРРЕАіжК№УГөДГьБоәН»щУЪSpiderАаК№УГөДГьБоПаН¬
scrapy genspider crawl -t spiderName www.xxx.com
¶юЎў°ёАэЈә№ЕК«ОДНшИ«ХҫКэҫЭЕАИЎ
ЕАИЎ№ЕК«ОДНшКЧТі№ЕК«өДұкМвЈ¬ТФј°ГҝТ»КЧК«ПкЗйТі№ЕК«өДұкМвәНДЪИЭЎЈ
ЧоәуҪ«ҙУПкЗйТіМбИЎөҪөД№ЕК«ұкМвәНДЪИЭҪшРРіЦҫГ»Ҝҙжҙў
2.1 ЕАіжОДјю
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from gushiPro.items import GushiproItem,ContentItem
class GushiSpider(CrawlSpider):
name = 'gushi'
#allowed_domains = ['www.xxx.com']
start_urls = ['https://www.gushiwen.org/']
# БҙҪУМбИЎЖч:Ц»ДЬК№УГХэФтұнҙпКҪЈ¬МбИЎөұЗ°ТіГжөДВъЧгallowМхјюөДБҙҪУ
link = LinkExtractor(allow=r'/default_\d+\.aspx')
# БҙҪУМбИЎЖчЈ¬МбИЎЛщУРұкМв¶ФУҰөДПкЗйТіurl
content_link = LinkExtractor(allow=r'cn/shiwenv_\w+\.aspx')
rules = (
# №жФтҪвОцЖчЈ¬РиТӘҪвОцЛщУРөДТіГжЈ¬ЛщУРfollow=True
Rule(link, callback='parse_item', follow=True),
# І»РиТӘРҙfollowЈ¬ТтОӘОТГЗЦ»РиТӘҪвОцПкЗйТіЦРөДКэҫЭЈ¬¶шІ»КЗПкЗйТіЦРөДurl
Rule(content_link, callback='content_item'),
)
# ҪвОцөұЗ°ТіГжөДұкМв
def parse_item(self, response):
p_list = response.xpath('//div[@class="sons"]/div[1]/p[1]')
for p in p_list:
title = p.xpath('./a//text()').extract_first()
item = GushiproItem()
item['title'] = title
yield item
# ҪвОцПкЗйТіГжөДұкМвәНДЪИЭ
def content_item(self,response):
# //div[@]/div[@class="cont"]/div[@class="contson"]
# ҪвОцПкЗйТіГжөДДЪИЭ
content = response.xpath('//div[@]/div[@class="cont"]/div[@class="contson"]//text()').extract()
content = "".join(content)
# # ҪвОцПкЗйТіГжөДұкМв
title = response.xpath('//div[@]/div[@class="cont"]/h1/text()').extract_first()
# print("title:"+title+"\ncontent:"+content)
item = ContentItem()
item["content"] = content
item["title"] = title
# Ҫ«itme¶ФПуҙ«ёш№ЬөА
yield item
2.2 itemОДјю
import scrapy
# І»Н¬өДitemАаКЗ¶АБўөДЈ¬ЛыГЗҝЙТФҙҙҪЁІ»Н¬өДitem¶ФПу
class GushiproItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
class ContentItem(scrapy.Item):
title = scrapy.Field()
content = scrapy.Field()
2.3 №ЬөАОДјю
from itemadapter import ItemAdapter
class GushiproPipeline:
def __init__(self):
self.fp = None
def open_spider(self,spider):
self.fp = open("gushi.txt",'w',encoding='utf-8')
print("ҝӘКјЕАіж")
def process_item(self, item, spider):
# ҙУПкЗйТі»сИЎұкМвәНДЪИЭЈ¬ЛщТФРиТӘЕР¶ПЕАіжОДјюЦРҙ«АҙөДitemКЗКІГҙАаөДitem
# item.__class__.__name__ЕР¶ПКфУЪКІГҙАаРНөДitem
if item.__class__.__name__ == "ContentItem":
content = "Ў¶"+item['title']+"Ў·",item['content']
content = "".join(content)
print(content)
self.fp.write(content)
return item
def close_spider(self,spider):
self.fp.close()
print("ҪбКшЕАіж")
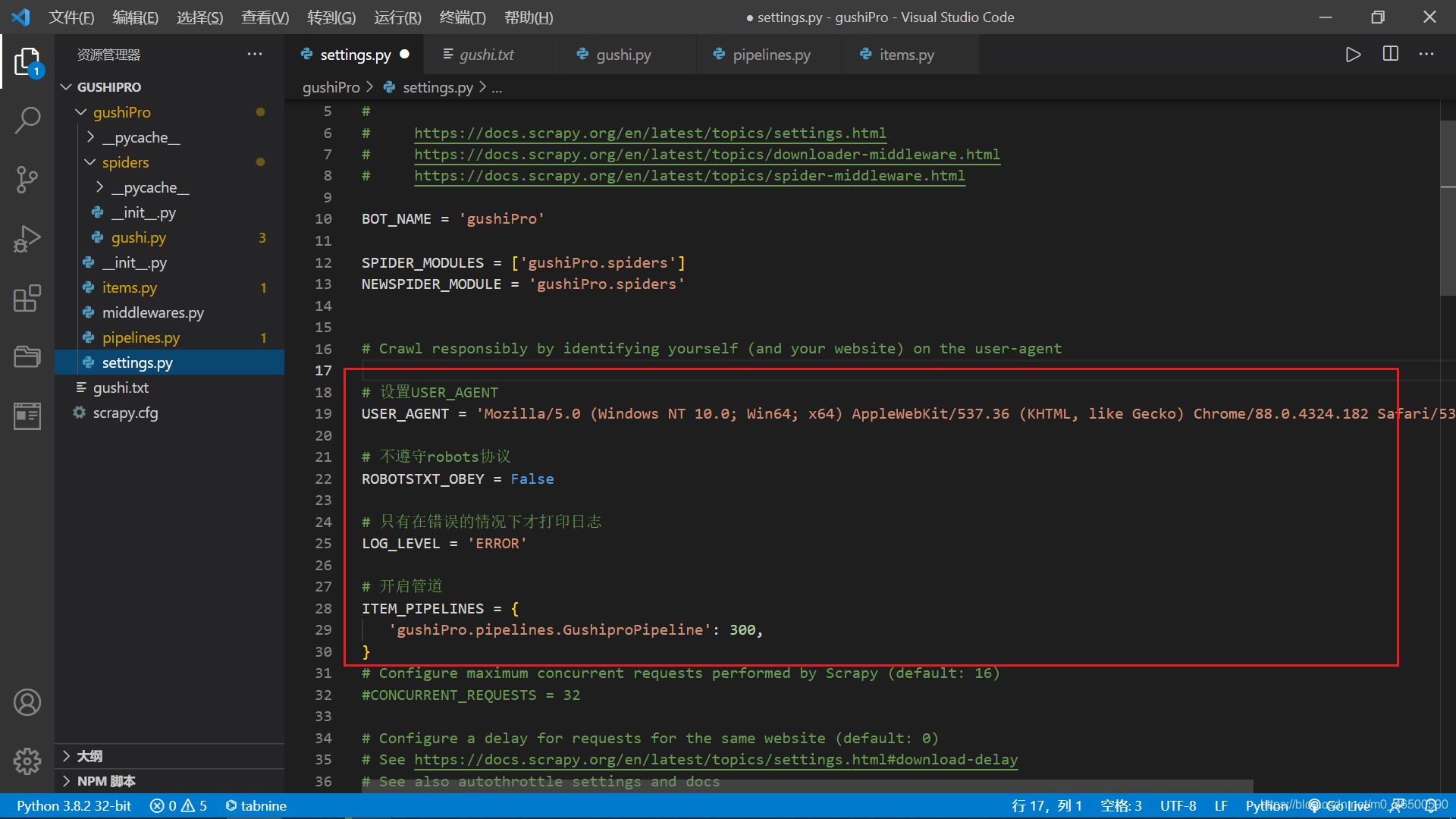
2.4 ЕдЦГОДјю
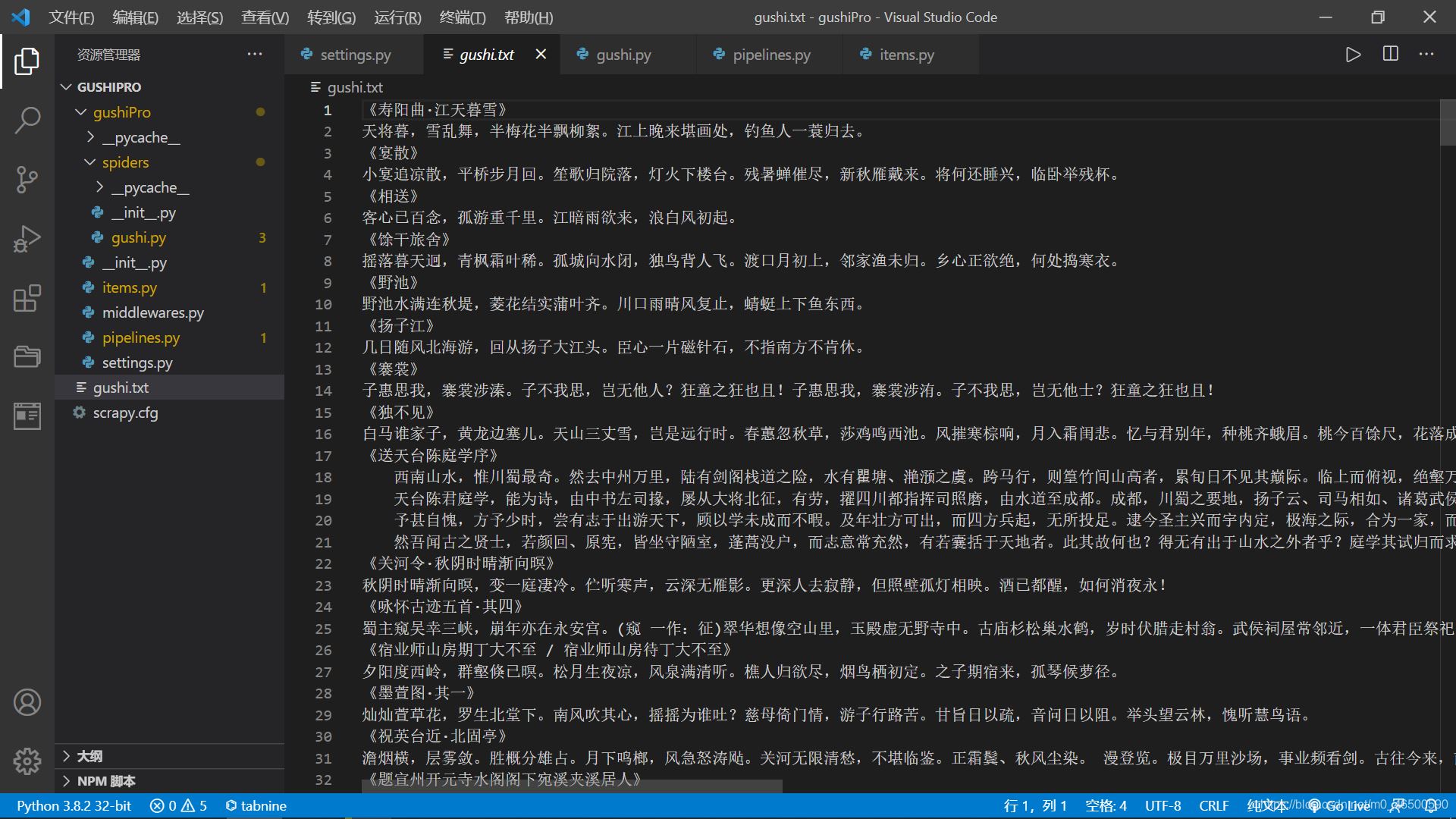
2.5 КдіцҪб№ы
jsjbwy