Yarn高可用架构重温
解决NameNode单点故障问题
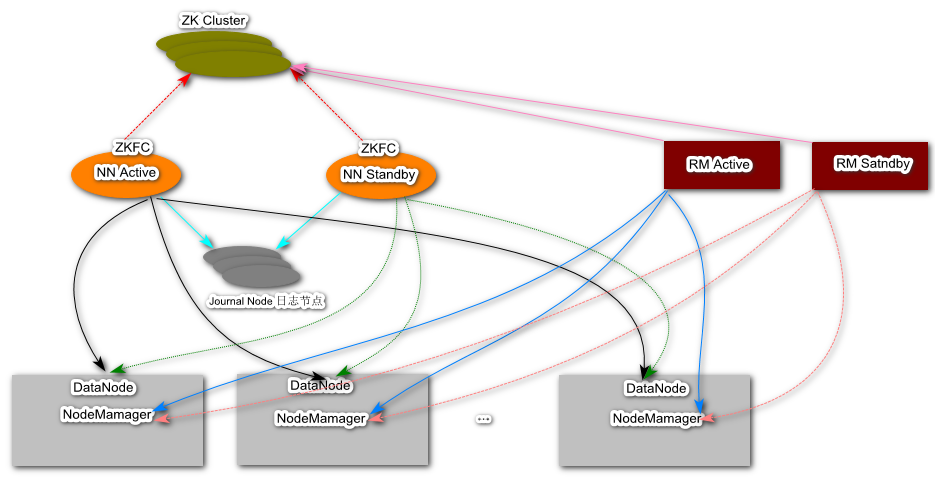
? ResoueceManager:负责整个集群的资源统筹和管理(只有一个active状态,另外一个为standby状态,active的挂掉之后,standby切换为active,之后active挂掉的节点重新加入集群会处于standby)
? NameNode:一个中心服务器,负责管理文件系统的namespace以及客户端对文件的访问。NameNode执行文件系统的namespace操作,比如打开、关闭、重命名目录或文件,同时它还确定block和DataNode节点的映射关系
NodeManager:管理着主机上的计算资源【计算资源的抽象(代表着一组内存、cpu、硬盘、网络)】,负责向RM汇报自身的状态, 处理来自ResourceManager和ApplicationMaster的命令
? DataNode:用于存储的数据块的节点,负责处理文件系统客户端的读写请求,在NameNode的统一调度下进行数据块的创建、删除和复制
? Zookeeper: 在ZooKeeper的体系下,会使用一种树状的文件存储系统,这一套系统强调在各个子节点下的文件目录结构,文件名称以及文件内容都是相同的,而ZooKeeper会通过其内部机制,保证在发送增删改等操作时,各个子节点会同步操作。 它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等
yarn的高可用集群中开启故障转移和leader选举的配置
开启自动故障转移(自动选举)
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
启动自动故障转移后,使用内置的leader选举机制:
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
</property>
? JournalNode:日志服务,主要用于主备NameNode元数据的同步;运行的JournalNode进程非常轻量,可以部署在其他的服务器上。注意:节点数至少3个( 在高可用集群中,active namenode写数据到journalnode上时,必须有半数以上的journalnode写成功的话,才标志写成功。因此需要奇数。也就是说如果有3个journalnode,则可以请允许1个down掉,如果有5个的话,可以允许2个down掉。 )
? ZKFC:ZooKeeperFailoverController作为一个ZK集群的客户端,主要用来监控NameNode的状态信息
? fsimage:fsimage文件实质是Hadoop文件系统元数据的一个永久性检查点,其中包含Hadoop文件系统的所有目录和文件id的序列化信息,元数据信息的备份(持久化),会加载在内存中
? editlog:(写操作日志文件)editlog文件存放的是Hadoop文件系统的所有更新操作的命令,文件系统客户端执行的所有写操作首先会被记录到editlog文件中
cs