其实,引用传递一开始是针对C的引用类型而言的,引用传递以外,有值传递和地址传递两种(即传值和传址),因为引用传递和地址传递都能达到改变形参外的实参的效果,所以,慢慢的地址传递也开始被很多人叫为引用传递。
形参的形就是一种所谓的形式,只是用于辅助说明函数的参数的类型,并没有实际的值,当函数被调用时,函数栈产生,形参也就存在于该栈的数据区(其实就是一个相对地址),当函数调用结束,栈撤销,形参也没了。实参是函数调用时实际传给函数的参数,值传递时,实参的值被复制到函数栈的形应的形参的数据区的地址里,地址(引用)传递时,实参的地址被复制到函数栈的形应的形参的数据区的地址里,函数对形参的操作,只是针对与数据区的那个形参的地址而操作,值传递时,因为修改的是形参地址的内容,所以不会对实参产生影响,地址(引用)传递时,修改形参的属性,并不是直接就把形参的地址里的内容覆盖(因为形参地址里存的只是个地址,没有什么属性),而是先从形参地址里取出里面的内容,即形参和实参共同指向的地址,然后再对那个地址进行操作,这样,因为实参也指向那个地址,所以实参的属性也会发生改变。对于重新给形参赋值,这时是在形参的地址里重新存入一个新的地址,此时形参与实参不再指向同一个地址,所以形参的任何变化都不会对实参造成影响。这也就是为什么在函数里不能改变实参的指向的原因。
Java的参数传递完全等同于赋值运算符的操作。
给方法内的参数用等于号赋值不会改变原来参数的值。
int num=20;
String str="hello"
对于基本类型 num ,赋值运算符会直接改变变量的值,原来的值被覆盖掉。
对于引用类型 str,赋值运算符会改变引用中所保存的地址,原来的地址被覆盖掉。但是原来的对象不会被改变(重要)。
如上图所示,"hello" 字符串对象没有被改变。(没有被任何引用所指向的对象是垃圾,会被垃圾回收器回收)
调用方法时发生了什么?参数传递基本上就是赋值操作。
https://zhuanlan.zhihu.com/p/27573287
JAVA在程序运行时,在内存中划分5片空间进行数据的存储。分别是:1:寄存器。2:本地方法区。3:方法区。4:栈。5:堆。
基本,栈stack和堆heap这两个概念很重要,不了解清楚,后面就不用学了。
以下是这几天栈和堆的学习记录和心得。得些记录下来。以后有学到新的,会慢慢补充。
一、先说一下最基本的要点
基本数据类型、局部变量都是存放在栈内存中的,用完就消失。
new创建的实例化对象及数组,是存放在堆内存中的,用完之后靠垃圾回收机制不定期自动消除。
二、先明确以上两点,以下示例就比较好理解了
示例1
main()
int x=1;
show ()
int x=2
主函数main()中定义变量int x=1,show()函数中定义变量int x=1。最后show()函数执行完毕。
以上程序执行步骤:
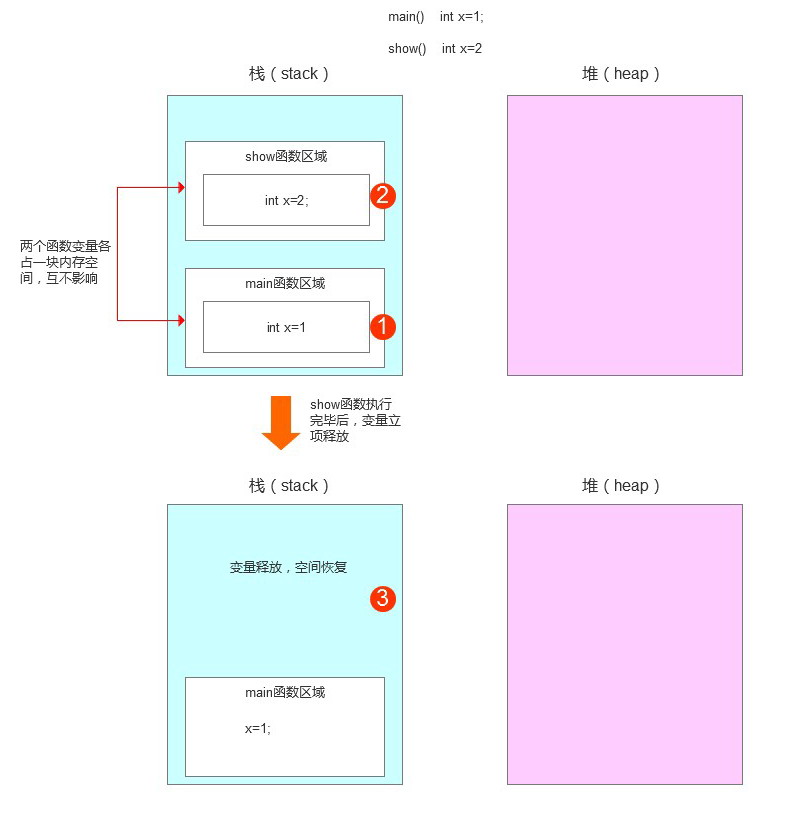
第1步——main()函数是程序入口,JVM先执行,在栈内存中开辟一个空间,存放int类型变量x,同时附值1。
第2步——JVM执行show()函数,在栈内存中又开辟一个新的空间,存放int类型变量x,同时附值2。
此时main空间与show空间并存,同时运行,互不影响。
第3步——show()执行完毕,变量x立即释放,空间消失。但是main()函数空间仍存在,main中的变量x仍然存在,不受影响。
示意图如下:
——————————————————————————————————————————————————————————————————————
示例2
main()
int[] x=new int[3];
x[0]=20
主函数main()中定义数组x,元素类型int,元素个数3。
以上程序执行步骤
第1步——执行int[] x=new int[3];
隐藏以下几分支
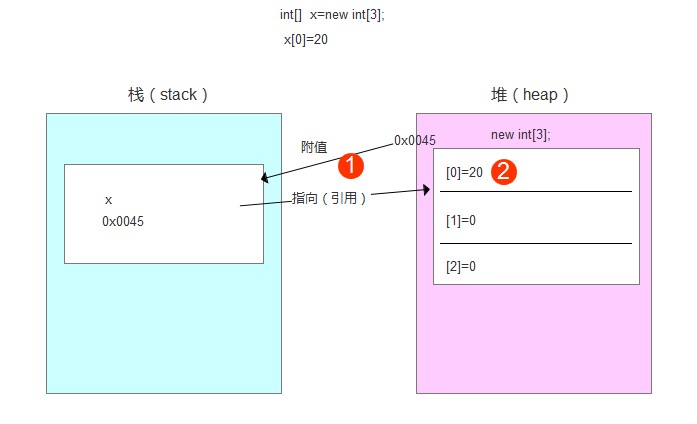
JVM执行main()函数,在栈内存中开辟一个空间,存放x变量(x变量是局部变量)。
同时,在堆内存中也开辟一个空间,存放new int[3]数组,堆内存会自动内存首地址值,如0x0045。
数组在栈内存中的地址值,会附给x,这样x也有地址值。所以,x就指向(引用)了这个数组。此时,所有元素均未附值,但都有默认初始化值0。
第2步——执行x[0]=20
即在堆内存中将20附给[0]这个数组元素。这样,数组的三个元素值分别为20,0,0
示图如下:
——————————————————————————————————————————————————————————————————————
示例3
main()
int[] x=new int[3];
x[0]=20
x=null;
以上步骤执行步骤
第1、2步——与示例2完全一样,略。
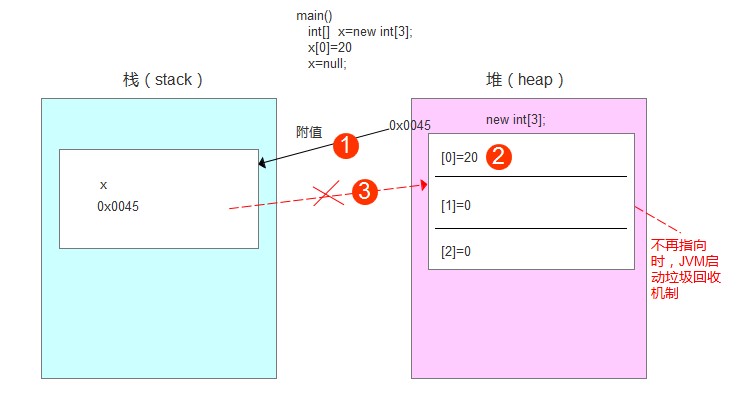
第3步——执行x=null;
null表示空值,即x的引用数组内存地址0x0045被删除了,则不再指向栈内存中的数组。此时,堆中的数组不再被x使用了,即被视为垃圾,JVM会启动垃圾回收机制,不定时自动删除。
示图如下
——————————————————————————————————————————————————————————————————
示例4
main()
int[] x=new int[3];
int[] y=x;
y[1]=100
x=null;
以上步骤执行步骤
第1步——与示例2第1步一致,略。
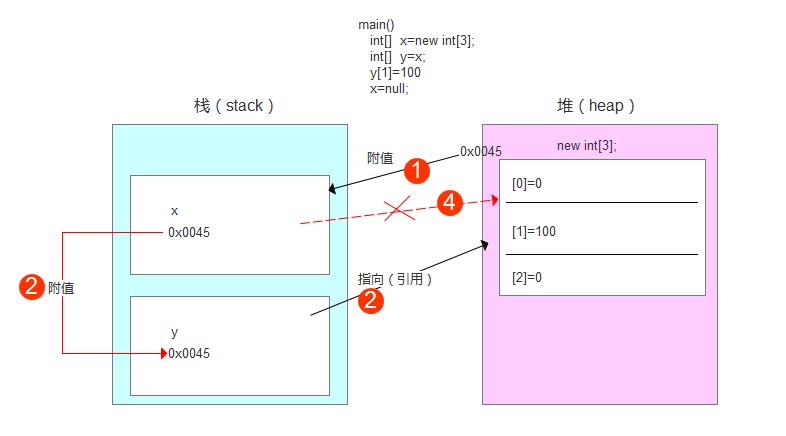
第2步——执行int[] y=x,
在栈内存定义了新的数组变量内存y,同时将x的值0x0045附给了y。所以,y也指向了堆内存中的同一个数组。
第3步——执行y[1]=100
即在堆内存中将20附给[0]这个数组元素。这样,数组的三个元素值分别为0,100,0
第4步——执行x=null
则变量x不再指向堆内存中的数组了。但是,变量y仍然指向,所以数组不消失。
示图如下
——————————————————————————————————————————————————————————————————
示例5
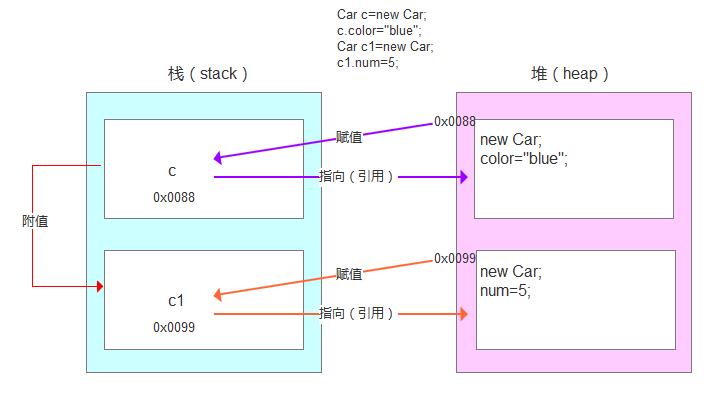
Car c=new Car;
c.color="blue";
Car c1=new Car;
c1.num=5;
?虽然是个对象都引用new Car,但是是两个不同的对象。每一次new,都产生不同的实体
——————————————————————————————————————————————————————————————————
示例6
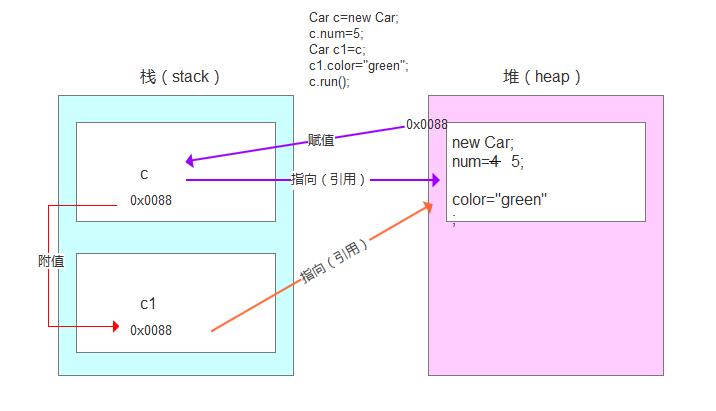
Car c=new Car;
c.num=5;
Car c1=c;
c1.color="green";
c.run();
Car c1=c,这句话相当于将对象复制一份出来,两个对象的内存地址值一样。所以指向同一个实体,对c1的属性修改,相当于c的属性也改了。
三、栈和堆的特点
栈:
函数中定义的基本类型变量,对象的引用变量都在函数的栈内存中分配。
栈内存特点,数数据一执行完毕,变量会立即释放,节约内存空间。
栈内存中的数据,没有默认初始化值,需要手动设置。
堆:
堆内存用来存放new创建的对象和数组。
堆内存中所有的实体都有内存地址值。
堆内存中的实体是用来封装数据的,这些数据都有默认初始化值。
堆内存中的实体不再被指向时,JVM启动垃圾回收机制,自动清除,这也是JAVA优于C++的表现之一(C++中需要程序员手动清除)。
注:
什么是局部变量:定义在函数中的变量、定义在函数中的参数上的变量、定义在for循环内部的变量
=============================分割线==============================================================================================
再举个例子:
Java 程序员之所以容易搞混值传递和引用传递,主要是因为 Java 有两种数据类型,一种是基本类型,比如说 int,另外一种是引用类型,比如说 String。
基本类型的变量存储的都是实际的值,而引用类型的变量存储的是对象的引用——指向了对象在内存中的地址。值和引用存储在 stack(栈)中,而对象存储在 heap(堆)中。
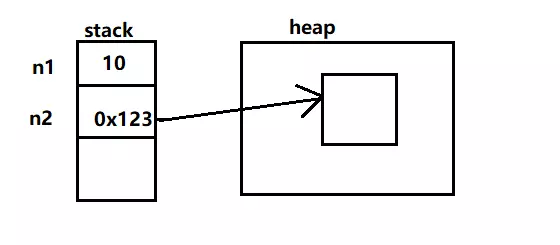
之所以有这个区别,是因为:
- 栈的优势是,存取速度比堆要快,仅次于直接位于 CPU 中的寄存器。但缺点是,栈中的数据大小与生存周期必须是确定的。
- 堆的优势是可以动态地分配内存大小,生存周期也不必事先告诉编译器,Java 的垃圾回收器会自动收走那些不再使用的数据。但由于要在运行时动态分配内存,存取速度较慢。
02、基本类型的参数传递
众所周知,Java 有 8 种基本数据类型,分别是 int、long、byte、short、float、double 、char 和 boolean。它们的值直接存储在栈中,每当作为参数传递时,都会将原始值(实参)复制一份新的出来,给形参用。形参将会在被调用方法结束时从栈中清除。
来看下面这段代码:
public class PrimitiveTypeDemo {
public static void main(String[] args) {
int age = 18;
modify(age);
System.out.println(age);
}
private static void modify(int age1) {
age1 = 30;
}
}
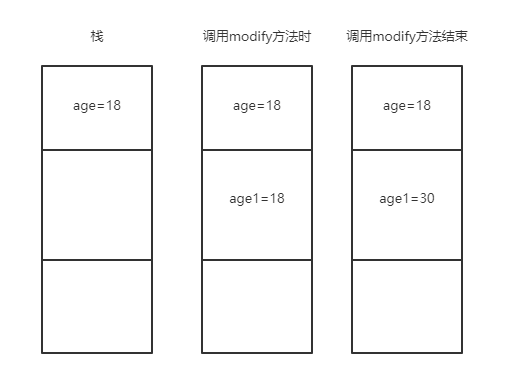
1)main 方法中的 age 是基本类型,所以它的值 18 直接存储在栈中。
2)调用 modify() 方法的时候,将为实参 age 创建一个副本(形参 age1),它的值也为 18,不过是在栈中的其他位置。
3)对形参 age 的任何修改都只会影响它自身而不会影响实参。
03、引用类型的参数传递
来看一段创建引用类型变量的代码:
Writer writer = new Writer(18, "沉默王二");
writer 是对象吗?还是对象的引用?为了搞清楚这个问题,我们可以把上面的代码拆分为两行代码:
Writer writer;
writer = new Writer(18, "沉默王二");
假如 writer 是对象的话,就不需要通过 new 关键字创建对象了,对吧?那也就是说,writer 并不是对象,在“=”操作符执行之前,它仅仅是一个变量。那谁是对象呢?new Writer(18, "沉默王二"),它是对象,存储于堆中;然后,“=”操作符将对象的引用赋值给了 writer 变量,于是 writer 此时应该叫对象引用,它存储在栈中,保存了对象在堆中的地址。
每当引用类型作为参数传递时,都会创建一个对象引用(实参)的副本(形参),该形参保存的地址和实参一样。
来看下面这段代码:
package test;
public class Demo {
public static void main(String[] args) {
Writer a = new Writer();
Writer b = new Writer();
a.setAge(18);
b.setAge(18);
modify(a, b);
System.out.println(a.getAge());
System.out.println(b.getAge());
}
private static void modify(Writer a1, Writer b1) {
a1.setAge(30);
b1 = new Writer();
b1.setAge(30);
}
}
class Writer {
private int age;
public void setAge(int age) {
this.age = age;
}
public int getAge() {
return age;
}
}
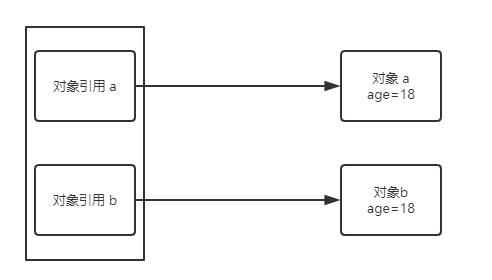
1)在调用 modify() 方法之前,实参 a 和 b 指向的对象是不一样的,尽管 age 都为 18。
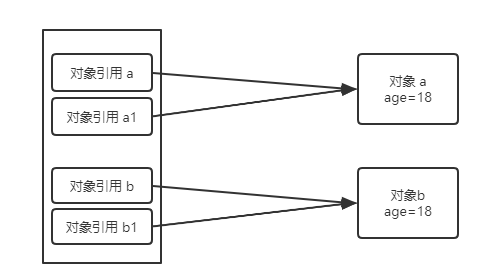
2)在调用 modify() 方法时,实参 a 和 b 都在栈中创建了一个新的副本,分别是 a1 和 b1,但指向的对象是一致的(a 和 a1 指向对象 a,b 和 b1 指向对象 b)。
3)在 modify() 方法中,修改了形参 a1 的 age 为 30,意味着对象 a 的 age 从 18 变成了 30,而实参 a 指向的也是对象 a,所以 a 的 age 也变成了 30;形参 b1 指向了一个新的对象,随后 b1 的 age 被修改为 30。
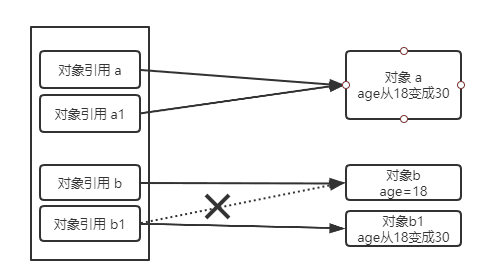
修改 a1 的 age,意味着同时修改了 a 的 age,因为它们指向的对象是一个;修改 b1 的 age,对 b 却没有影响,因为它们指向的对象是两个。
String类是我们平常项目中使用频率非常高的一种对象类型,JVM为了提升性能和减少开销,避免字符串的重复创建,维护了一块特殊的内存空间,即字符串常量池。当需要使用字符串时,先去字符串常量池查看该字符串是否已经存在,如果存在,则可直接使用;如果不存在,初始化,并将该字符串放入到字符串常量池中。
在JDK1.6及之前版本,字符串常量池在方法区中
在JDK1.7及以后版本,字符串常量池移到了堆中
————————————————
?
==使用总结
如果是基本数据类型,==判断的是值
如果是对象类型,==判断的是对象的地址
其它总结
通过直接赋值而不是new的方式给String赋值,如果字符串常量池中有该对象,则不会再创建,此时通过 == 判断,返回的是true。如:String str=“wo”;String str1=“wo”;str == str1为true.
对象的引用保存在栈中
?
关于浅拷贝和深拷贝,浅拷贝可以理解为一个指针,深拷贝会复制一块内存
参考文章:https://blog.csdn.net/baiye_xing/article/details/71788741
https://www.runoob.com/java/java-string-intern.html
cs