小白爬虫学习之路・・・
illegal multibyte sequence问题解决办法・・・
爬虫练习(百度产品以及新浪新闻关键词)
注:广搜索,细学习。
一、百度产品网页
打开网页之后呢,就进入百度产品的搜索页面了;
import requests
start_url = 'https://www.baidu.com/more/'
response = requests.get(start_url)
with open('index.html', 'w', encoding='utf-8') as fp:
fp.write(response.content.decode('utf-8'))
print(response.status_code)
print(response.headers)
print(type(response.text))
print(type(response.content))
二、新浪新闻――指定搜索内容的爬取
import requests
url = 'https://search.sina.com.cn/?'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
}
key = '李小龙'
params = {
'q': key,
'c': 'news',
'from': 'channel',
'ie': 'utf-8'
}
response = requests.get(url, headers=headers, params=params)
print(response.text)
print(response.url)
with open('sina_news.html', 'w', encoding='gbk',errors='ignore') as fp:
fp.write(response.content.decode('utf-8'))
get 方法是可以向服务器发送信息的,除了可以请求需要的页面之外,也可以发送我们指定的内容,这就是通过 params 参数实现的。
request库 ----- get方法 ----- params
这个 params 参数是字典结构,前面说到的 headers 其实也是字典结构,但它们传输的时候是以 json 的方式传输的~~~
首先我们构建一个字典,里面写上我们想要发送的信息,网站会根据我们发送的内容返回对应的信息,但是获取到的不是网站源码。
程序刚开始执行的时候呢报错如下:
UnicodeDecodeError: ‘gbk’ codec can’t decode byte 0x99 in position 958: illegal multibyte sequence
在网上搜索的,在open语句里面加入(errors=‘ignore’)就可以了,但是上面加入之后还报错,这个时候把write里面的编码格式"gbk"改为"utf-8",便不会报错了。(上面代码这里已改)
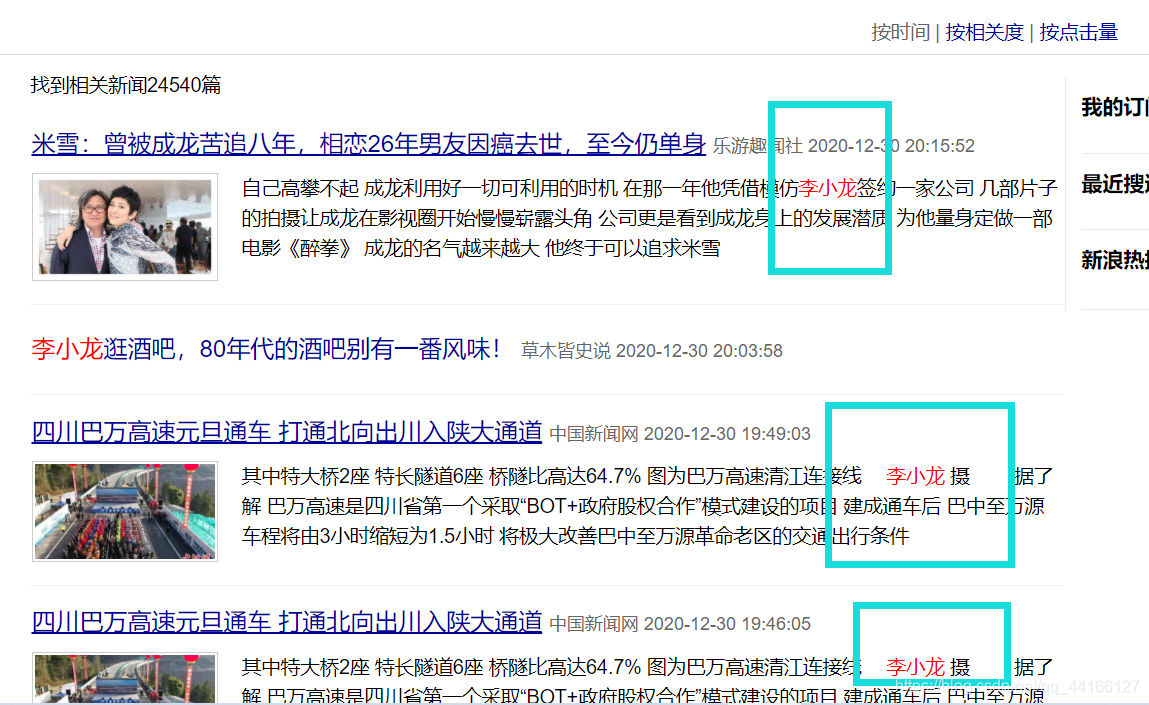
打开响应的url页面,便可以看到最新的关于“李小龙”三字进行的搜索:
天很冷,好冻手,我再看看params参数的使用・・・
cs