змЬхЫМТЗ:
????ЭјеОЕижЗ:https://www.umei.net/bizhitupian/weimeibizhi/
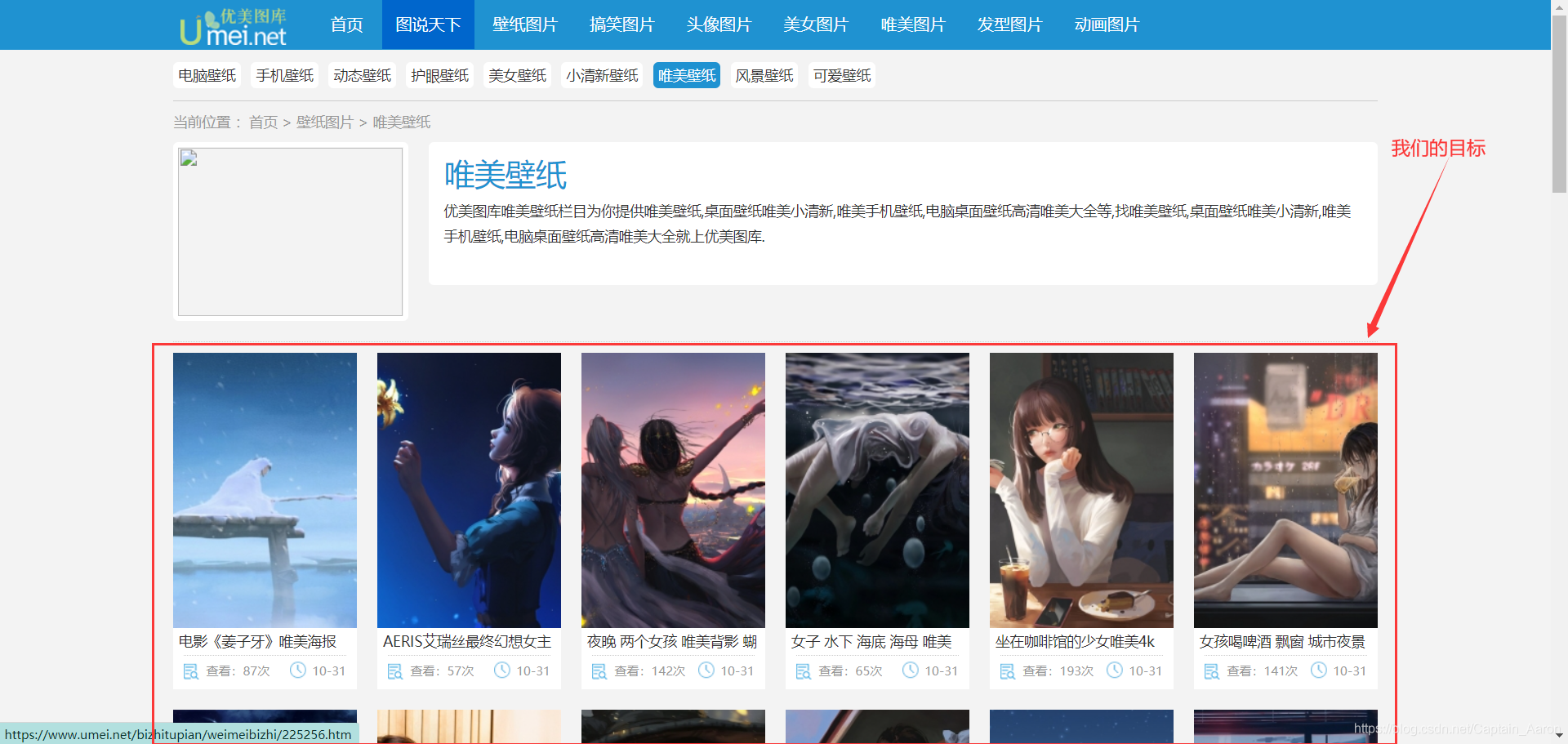
?????зЂвтЮвбЁжаЕФетИіЧјгђ, ЮвУЧЯывЊЕФЭМЦЌОЭдкетРя. ЕЋЪЧ, ОјЖдВЛЪЧЯждкФуПДЕНЕФбљзгЁЃЮЊЪВУДФи? ВЛЙЛИпЧхДѓЭМ~
?????еце§ЕФИпЧхДѓЭМдкзгвГУцжа, БШШч, ЮвЕуЛїЕк?ИіЭМЦЌ
????ЮвашвЊдкЭјеОЕФЪзвГжа, евЕНзгвГУцЕФСДНг, ШЛКѓЧыЧѓЕНзгвГУц,ВХФмПДЕНетеХДѓЭМ~
????вВОЭЪЧЫЕ, ЯывЊЯТдиИУЭјеОЭМЦЌ(ИпЧхДѓЭМ), ашвЊШ§ВН,
????Ек?ВН, дкжївГУцжаФУЕНУП?ИіЭМЦЌЕФзгвГУцСДНг
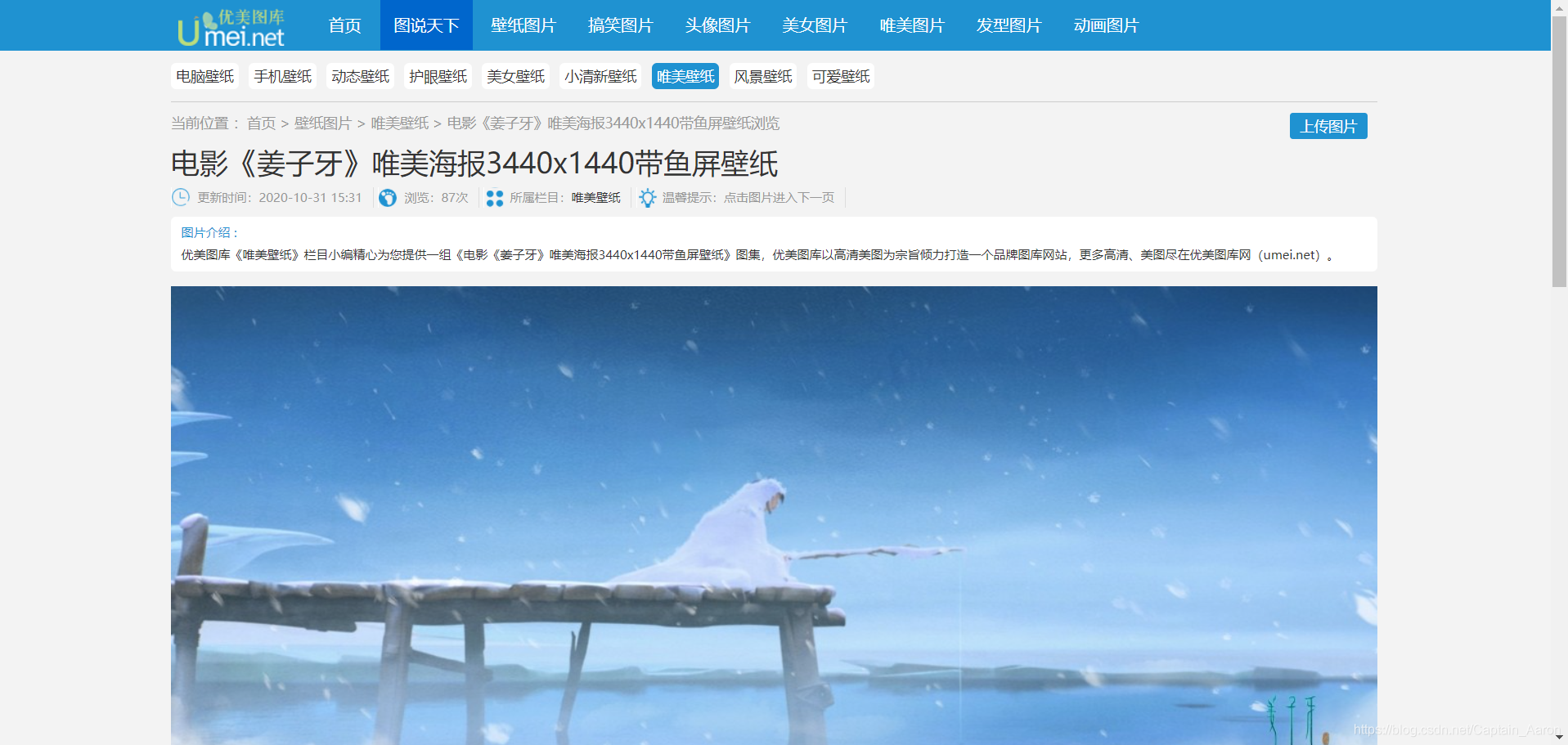
????ЕкЖўВН, дкзгвГУцжаевЕНеце§ЕФЭМЦЌЯТдиЕижЗ
????ЕкШ§ВН, ЯТдиЭМЦЌ
ДњТы:
# 1.ФУЕНжївГУцЕФдДДњТы,ШЛКѓЬсШЁЕНзгвГУцЕФСДНг,href
# 2.ЭЈЙ§hrefФУЕНзгвГУцЕФФкШн,ДгзгвГУцевЕНЭМЦЌЕФЯТдиЕижЗ img->src
# 3.ЯТдиЭМЦЌ
import requests
from bs4 import BeautifulSoup
import time
url = "https://www.umei.net/bizhitupian/weimeibizhi/"
resp = requests.get(url)
resp.encoding="utf-8"
# print(resp.text)
# АбдДДњТыНЛИјbs
main_page = BeautifulSoup(resp.text,"html.parser")
alist = main_page.find("div",class_="TypeList").find_all("a") # АбЗЖЮЇЕквЛДЮЫѕаЁ
# print(alist)
for a in alist:
href = "https://www.umei.net"+a.get('href') # жБНгЭЈЙ§getОЭПЩвдФУЕНЪєадЕФжЕ ЕквЛВНЭъГЩ
# ФУЕНзгвГУцЕФдДДњТы
child_page_resp = requests.get(href)
child_page_resp.encoding = 'utf-8'
child_page_text = child_page_resp.text
# ДгзгвГУцжаФУЕНЭМЦЌЕФЯТдиТЗОЖ
child_page = BeautifulSoup(child_page_text,"html.parser")
p = child_page.find("p",align="center") # pБъЧЉ
img = p.find("img") # imgБъЧЉ
src = img.get("src")
# print(src)
# ЯТдиЭМЦЌ
img_resp = requests.get(src)
# img_resp.content # етРяФУЕНЕФзжНк
img_name = src.split("/")[-1] # ФУЕНurlжаЕФзюКѓвЛИі/вдКѓЕФФкШн
with open("img/"+img_name,mode="wb") as f:
f.write(img_resp.content) # ЭМЦЌФкШнаДШыЮФМў
print("over! ",img_name)
time.sleep(1)
f.close()
resp.close()
дЫааНсЙћ:
cs