��æ֮�г��ʱ�����ҷ���һ�������⡣ϣ����Ҳ�Ҫ�����ҵ�һƬ�������濴��! 
һ. ʲô����»ᷢ��ջ�ڴ����?
˼·: ����ջ����,������Ϊʲô�����,��˵��һ��������ò���,OK�Ļ����Ը����Թ���д��һ
��ջ�����demo��
��:
- ջ���߳�˽�е�,���������������߳���ͬ,ÿ��������ִ�е�ʱ�ᴴ��һ��ջ֡,�����洢
�ֲ�������,������ջ,��̬����,�������ڵ���Ϣ���ֲ��������ְ���������������,��������
���� - ����߳������ջ��ȴ����������������������,���׳�StackOverflowError�쳣,������
����ò������ֽ���� - ���Java�����ջ���Զ�̬��չ,������չ�Ķ����Ѿ����Թ�,���������뵽�㹻���ڴ�ȥ���
��չ,�������½����̵߳�ʱ��û���㹻���ڴ�ȥ������Ӧ�������ջ,��ôJava��������׳�һ
��OutOfMemory �쳣��(�߳���������) - ���� -Xss ȥ����JVMջ�Ĵ�С
��. ���JVM�ڴ�ģ��
˼·: �����Թٻ�һ��JVM�ڴ�ģ��ͼ,������ÿ��ģ��Ķ���,����,�Լ����ܻ���ڵ�����,��ջ����ȡ�
��:
- JVM�ڴ�ṹ
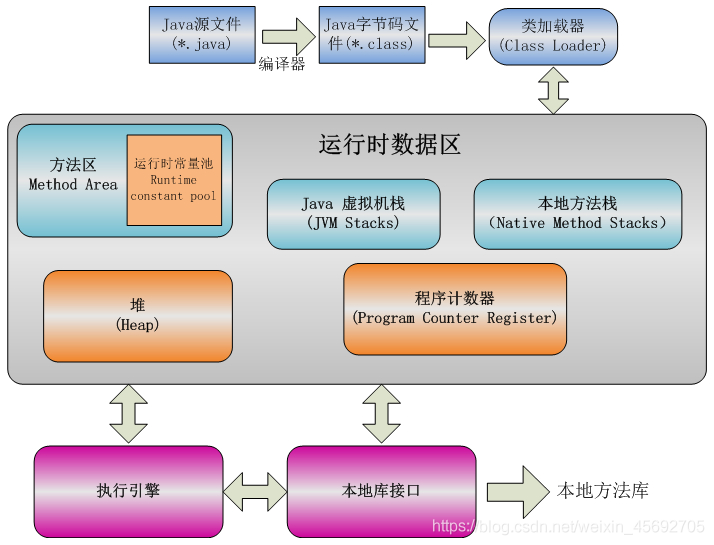
- ���������:��ǰ�߳���ִ�е��ֽ�����к�ָʾ��,���ڼ�¼����ִ�е�������ֽ�ָ���ַ,�߳�˽�С�
- Java����ջ:��Ż����������͡���������á��������ڵ�,�߳�˽�С�
- Native����ջ:������ջ����,ֻ������������Native����,�߳�˽�С�
- Java��:java�ڴ�����һ��,���ж���ʵ�������鶼�����java��,GC���յĵط�,�̹߳�����
- ������:����ѱ����ص�����Ϣ����������̬��������ʱ�����������Ĵ������ݵȡ�(�����ô�),����Ŀ����Ҫ�dz����صĻ��պ����͵�ж��,���̹߳�����
��. JVM�ڴ�ΪʲôҪ�ֳ�������,�����,�־ô�����������ΪʲôҪ��ΪEden��Survivor ?
˼·: �Ƚ�һ��JAVA��,�������Ļ���,��̸̸����֮���ת��,�֮��һЩ����������(��: �C XX:NewRatio,�CXX:SurvivorRatio��),�ٽ���ΪʲôҪ��������,��ü�һ���Լ������⡣
��:
�����ڴ�������
- �����ڴ��� = �־ô� + ��
- �־ô� = ������ + ����
- Java�� = ����� + ������
- ������ = Eden + S0 + S1
һЩ����������
- Ĭ�ϵ�,������ ( Young ) ������� ( Old ) �ı�����ֵΪ 1:2 ,����ͨ������
�CXX:NewRatio���á� - Ĭ�ϵ�,Edem : from : to = 8 : 1 : 1 ( ����ͨ������ �CXX:SurvivorRatio ���趨)��
- Survivor���еĶ����ƴ���Ϊ15(��Ӧ��������� -XX:+MaxTenuringThreshold)��
ΪʲôҪ��ΪEden��Survivor?ΪʲôҪ��������Survivor��?
- ���û��Survivor,Eden��ÿ����һ��Minor GC,���Ķ���ͻᱻ�͵��������������ܿ챻
����,����Major GC.��������ڴ�ռ�Զ����������,����һ��Full GC���ĵ�ʱ���Minor GC
���ö�,������Ҫ��ΪEden��Survivor�� - Survivor�Ĵ�������,���Ǽ��ٱ��͵�������Ķ���,��������Full GC�ķ���,Survivor��Ԥɸѡ
��֤,ֻ�о���16��Minor GC�������������д��Ķ���,�Żᱻ�͵�������� - ��������Survivor�����ĺô����ǽ������Ƭ��,�ո��½��Ķ�����Eden��,����һ��Minor
GC,Eden�еĴ�����ͻᱻ�ƶ�����һ��survivor space S0,Eden�����;��Eden������
��,���ٴ���һ��Minor GC,Eden��S0�еĴ������ֻᱻ��������ڶ���survivor space
S1(������̷dz���Ҫ,��Ϊ���ָ����㷨��֤��S1������S0��Eden�����ֵĴ�����ռ������
���ڴ�ռ�,��������Ƭ���ķ���)��
��. JVM��һ��������GC������������,������ν����������
˼·: ������һ��Java���ڴ滮��,�ٽ���Minor GC,Major GC,full GC,��������֮��ת�����̡�
��:
- ava�� = ����� + ������
- ������ = Eden + S0 + S1
- �� Eden ���Ŀռ�����, Java������ᴥ��һ�� Minor GC,���ռ�������������,��������Ķ���,���ת�Ƶ� Survivor����
- �����(��Ҫ���������ڴ�ռ��Java����,�����ֺܳ����ַ���)ֱ�ӽ�������̬; ���������Eden����,��������һ��Minor GC����Ȼ���,���ұ�Survivor���ɵĻ�,������Ϊ1,ÿ����һ��Minor GC,����+1,�����䳬��һ������(15) , ����������̬�� �����ڴ��Ķ����������̬��
- ��������˶������ɸ���Ķ���,Minor GC ֮��ͨ���ͻ����Full GC,Full GC ���������ڴ�
�� �C ��������������ϴ��� - Major GC �������������GC,����������,�������������һ��Minor GC,��Minor GC��10
��������
��. ��֪���ļ��������ռ���,���Ե���ȱ��,�ص㽲��cms��G1,����ԭ��,����,��ȱ�㡣
˼·: һ��Ҫ��ס���͵������ռ���,����cms��G1,���ǵ�ԭ��������,�漰�����������㷨��
�ҵĴ�:
���������ռ���
- Serial�ռ���: ���̵߳��ռ���,�ռ�����ʱ,����stop the world,ʹ�ø����㷨��
- ParNew�ռ���: Serial�ռ����Ķ��̰߳汾,Ҳ��Ҫstop the world,�����㷨��
- Parallel Scavenge�ռ���: �������ռ���,�����㷨���ռ���,�����Ķ��߳��ռ���,Ŀ���Ǵ�
��һ���ɿص������������������ܹ�����100����,������������1����,����������99%�� - Serial Old�ռ���: ��Serial�ռ�����������汾,���߳��ռ���,ʹ�ñ�������㷨��
- Parallel Old�ռ���: ��Parallel Scavenge�ռ�����������汾,ʹ�ö��߳�,���-�����㷨��
- CMS(Concurrent Mark Sweep) �ռ���: ��һ���Ի����̻���ͣ��ʱ��ΪĿ����ռ���,��
������㷨,��������:��ʼ���,�������,���±��,�������,�ռ���������������ռ���
Ƭ�� - G1�ռ���: ��������㷨ʵ��,����������Ҫ��������:��ʼ���,�������,���ձ��,ɸѡ
��ǡ���������ռ���Ƭ,���Ծ�ȷ�ؿ���ͣ�١�
CMS�ռ�����G1�ռ���������
- CMS�ռ�������������ռ���,���������������Serial��ParNew�ռ���һ��ʹ��;
- G1�ռ����ռ���Χ���������������,����Ҫ��������ռ���ʹ��;CMS�ռ�������С��ͣ��ʱ��ΪĿ����ռ���;
- G1�ռ�����Ԥ���������յ�ͣ��ʱ��
- CMS�ռ�����ʹ�á����-������㷨���е���������,���ײ����ڴ���Ƭ
- G1�ռ���ʹ�õ��ǡ����-�������㷨,�����˿ռ�����,�������ڴ�ռ���Ƭ��
��. JVM�ڴ�ģ�͵����֪ʶ�˽����,����������,�ڴ�����,happen-before,���ڴ�,�����ڴ档
˼·: �Ȼ���Java�ڴ�ģ��ͼ,�������volatile ,˵��ʲô��������,�ڴ�����,����ܸ����Թ�д����demo˵����
��:
һ. Java�ڴ�ģ��ͼ
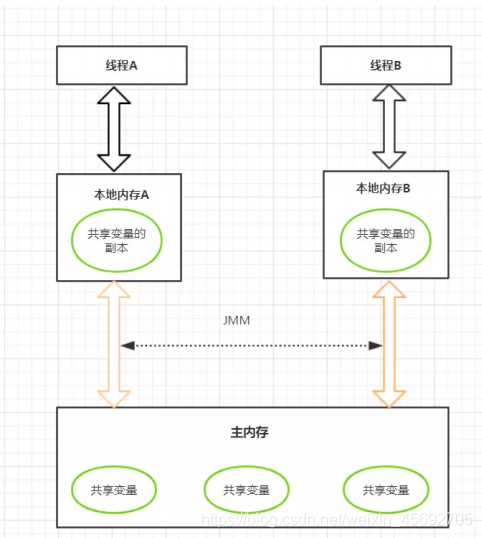
- Java�ڴ�ģ�涨�����еı������洢�����ڴ���,ÿ���̻߳����Լ��Ĺ����ڴ�,�̵߳Ĺ����ڴ��б����˸��߳������õ��ı��������ڴ渱������,�̶߳Ա��������в����������ڹ����ڴ��н���,������ֱ�Ӷ�д���ڴ档��ͬ���߳�֮��Ҳ��ֱ�ӷ��ʶԷ������ڴ��еı���,�̼߳�����Ĵ��ݾ���Ҫ�Լ��Ĺ����ڴ������֮���������ͬ�����С�
��. ָ��������
public class PossibleReordering {
static int x = 0, y = 0;
static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
Thread one = new Thread(new Runnable() { public void run() { a = 1; x = b; }});
Thread other = new Thread(new Runnable() { public void run() { b = 1; y = a;}});
one.start();other.start(); one.join();other.join(); System.out.println(��(�� + x + ��,�� + y + ��)��);
}
���մ������˳��ִ�еġ�������ִ�������������ý�ָ������ִ��(out-of-order execution,���OoOE��OOE)�ķ���,�����������������,ֱ�����е�ǰ����������ִ�еĺ���ָ��,�ܿ���ȡ��һ��ָ����������ʱ��ɵĵȴ�3��ͨ������ִ�еļ���,���������Դ�����ִ��Ч�ʡ��������ָ�����š�
��. �ڴ�����
�ڴ�����,Ҳ���ڴ�դ��,��һ��CPUָ��,���ڿ����ض������µ���������ڴ�ɼ������⡣
- LoadLoad����:�������������Load1; LoadLoad; Load2,��Load2��������ȡ����Ҫ��ȡ��
���ݱ�����ǰ,��֤Load1Ҫ��ȡ�����ݱ���ȡ��ϡ� - StoreStore����:�������������Store1; StoreStore; Store2,��Store2������д�����ִ��
ǰ,��֤Store1��д������������������ɼ��� - LoadStore����:�������������Load1; LoadStore; Store2,��Store2������д�������ˢ��
ǰ,��֤Load1Ҫ��ȡ�����ݱ���ȡ��ϡ� - StoreLoad����:�������������Store1; StoreLoad; Load2,��Load2���������ж�ȡ����ִ��
ǰ,��֤Store1��д������д������ɼ������Ŀ������������������ġ� �ڴ������������ʵ
����,��������Ǹ���������,������������ڴ����ϵĹ��ܡ�
��. happen-beforeԭ��
- ���߳�happen-beforeԭ��:��ͬһ���߳���,��д��ǰ��IJ���happen-before����IJ�����
- ����happen-beforeԭ��:ͬһ������unlock����happen-before������lock������
- volatile��happen-beforeԭ��:��һ��volatile������д����happen-before�Դ˱����������
��(��ȻҲ����д������)�� - happen-before�Ĵ�����ԭ��:���A���� happen-before B����,B����happen-before C��
��,��ôA����happen-before C������ - �߳�������happen-beforeԭ��:ͬһ���̵߳�start����happen-before���̵߳�����������
- �߳��жϵ�happen-beforeԭ�� :���߳�interrupt�����ĵ���happen-before���ж��̵߳ļ��
���жϷ��͵Ĵ��롣 - �߳��ս��happen-beforeԭ��: �߳��е����в�����happen-before�̵߳���ֹ��⡣
- ������happen-beforeԭ��: һ������ij�ʼ�������������finalize�������á�
��������һ�������ӹ�עŶ ~ 
cs