数学建模真的不适合我啊,劝退了,继续搞电路去了,这样一对比通信原理简单多了,这本书不错
我同学他们已经做完了,哈哈!
The Variability of Oxygen Saturation
氧饱和度的变异性
Pulse oximetry is routinely used for monitoring patients’ oxygen saturation levels.
脉搏血氧仪是监测病人血氧饱和度的常规方法。
During continuous monitoring, we wanted to be able to describe the patterns of oxygen saturation using a model.
在连续监测期间,我们希望能够使用一个模型来描述氧饱和度的模式。
We have the data of 36 individuals, each subject was tested the oxygen saturation continuously for approximately 1 hour at a frequency of 1 Hz.
我们有36个人的数据,每个受试者在1hz的频率下连续测试了大约1小时的氧饱和度。(大约一个小时说明采样数据点在3600左右)
We also recorded the following information about the participants, including age, BMI, gender, Smoking history and/or current smoking status, and any significant medical conditions that could affect reading.
我们还记录了参与者的以下信息,包括年龄、BMI、性别、吸烟史和/或当前吸烟状况,以及任何可能影响阅读的任何重要医学状况。(利用那个excel文件去数据挖掘,找到各个量和含氧量的关系)
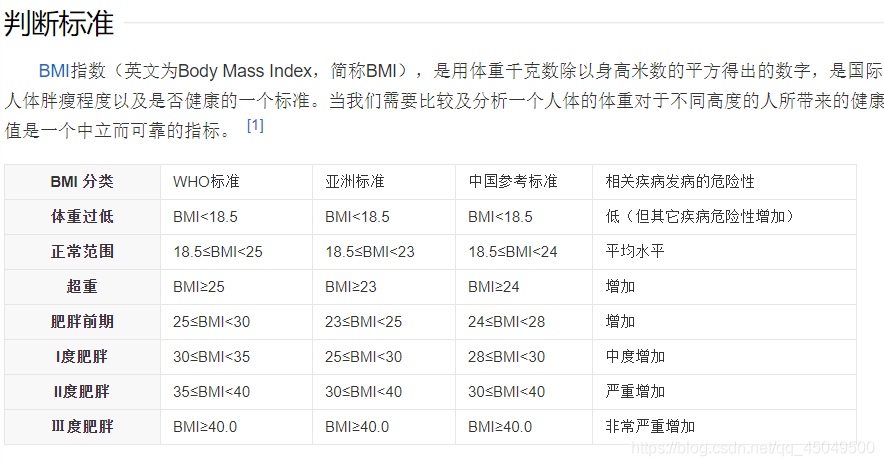


We want to use these data to find typical patterns of variability in oxygen saturation so that we could use several parameters to characterize an individual.
我们想用这些数据来找到氧饱和度变化的典型模式,这样我们就可以用几个参数来表征一个人。
We would also like to see whether the pattern of oxygen saturation series isrelated to age, i.e., which characteristics change in older people compared toyounger people.
我们还想知道氧饱和度系列的模式是否与年龄有关,也就是说,与年轻人相比,老年人的哪些特征会发生变化。
These characteristics should ideally be of biological or medical significance.
理想情况下,这些特征应该具有生物学或医学意义。
%处理氧含量数据的代码:
clc
close all
clear all
tic
load '010217B.txt';% input name of text file with appropriate extension
A = X010217B ;% for data such as 111213A add X at the beginning => i.e X111213A
m=mean(A)%数组均值
std = std(A)%数组标准差
[S,V]=dfa(A);
subplot (2,1,1)
title (['time-series'])
hold on
plot (A)
subplot (2,1,2)
scatter (S,V)
[r,a,b]=regression (S,V,'one'); % a = slope, b = intercept, r: correlation coefficnet (Pearson)
[r1,a1,b1]=regression (S(1:24),V(1:24),'one'); % a1 = slope, b1 = intercept, r1: correlation coefficnet (Pearson)
[r2,a2,b2]=regression (S(25:end),V(25:end),'one'); % a2 = slope, b2 = intercept, r2: correlation coefficnet (Pearson)
alpha = a(1,1)
title (['slope =',num2str(alpha),])
r
[se]=sampen(A,2,0.2)
[mse,sc]=msentropy(A);
toc
(S,V)=dfa(A);%dfa是去趋势波动分析法,
我之前理解为了有限状态自动机,唉,浪费了好长时间,
%下面是一个例程,可以参考参考,这个数据咋用,可以给我提供一下思路
clc
clear all
close all
%创建一个模拟数据集并计算其平均值。 sdata表示股票的每日价格变化。
t = 0:300;
dailyFluct = gallery('normaldata',size(t),2);
sdata = cumsum(dailyFluct) + 20 + t/100;
%计算均值
mean(sdata)
figure
plot(t,sdata);
legend('Original Data','Location','northwest');
xlabel('Time (days)');
ylabel('Stock Price (dollars)');
%计算去趋势数据,并且从原始数据中移除
detrend_sdata = detrend(sdata);
trend = sdata - detrend_sdata;
mean(detrend_sdata)
hold on
plot(t,trend,':r')
plot(t,detrend_sdata,'m')
plot(t,zeros(size(t)),':k')
legend('Original Data','Trend','Detrended Data',...
'Mean of Detrended Data','Location','northwest')
xlabel('Time (days)');
ylabel('Stock Price (dollars)');
function SampEnVal = sampen(data, m, r)
% SampEn 计算时间序列data的样本熵
% 输入:data是数据一维行向量
% m重构维数,一般选择1或2,优先选择2,一般不取m>2
% r 阈值大小,一般选择r=0.1~0.25*Std(data)
% 输出:SampEnVal样本熵值大小
data = data(:)';
N = length(data);
Nkx1 = 0;
Nkx2 = 0;
for k = N - m:-1:1
x1(k, :) = data(k:k + m - 1);
x2(k, :) = data(k:k + m);
end
for k = N - m:-1:1
x1temprow = x1(k, :);
x1temp = ones(N - m, 1)*x1temprow;
dx1(k, :) = max(abs(x1temp - x1), [], 2)';
Nkx1 = Nkx1 + (sum(dx1(k, :) < r) - 1)/(N - m - 1);
x2temprow = x2(k, :);
x2temp = ones(N - m, 1)*x2temprow;
dx2(k, :) = max(abs(x2temp - x2), [], 2)';
Nkx2 = Nkx2 + (sum(dx2(k, :) < r) - 1)/(N - m - 1);
end
Bmx1 = Nkx1/(N - m);
Bmx2 = Nkx2/(N - m);
SampEnVal = -log(Bmx2/Bmx1);
end
cs