高可用的网站架构
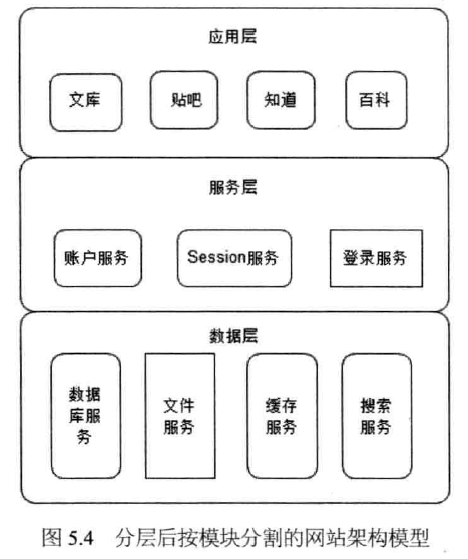
分层架构,每一层都分布式部署。使用冗余和故障转移的方式保证可用性。
- 应用层用负载均衡服务器,能够监测服务器的可用性,把不可能的踢出集群
- 服务层使用分布式调用框架dubbo
- 数据库使用同步复制,实现数据冗余。
- 还要考虑升级发布引起的宕机
高可用的应用
集群的session管理
- Session复制, 开启web服务器的session复制功能,能够在不同的web服务器之间进行session的同步。适合规模较小的情况
- Session绑定, 可以利用负载均衡的源地址hash算法实现,负载均衡服务器总是将同一IP的请求发到同一台服务器上(也可以根据cookie中的用户信息) 。这种显然不高可用
- 用cookie记录session 记录大小优先,每次都要用cookie传输影响性能。浏览器可以关闭cookie. 优点是简单,支持服务器扩展。
- session服务器 构建独立的session服务器。 可以简单的使用分布式缓存进行保留,如果需要继承SSO的话,就可能需要专门的session服务管理平台
高可用的服务
整体来说就是冗余,故障转移,使用分布式调用框架。
- 分级管理 0级,1级。更重要的服务,使用更好的设备
- 超时设置 不超时会长时间占用服务器资源。 可以设置超时策略,重试,还是转移
- 异步调用
- 服务降级 高并发时,可以
拒绝服务。 随机拒绝部分请求
关闭功能。关闭部分不需要的功能。双十一就是这样干的
- 幂等性设计 针对于重试机制。不会出现下两个订单的情况
高可用的数据
数据库高可用使用复制备份和故障转移解决
缓存的高可用作者认为应该使用集群分布式缓存,单点失效只是小部分失效不会造成数据库太大的压力
CAP原理
拂去耐受性(可以线性伸缩),可用性(随时可读写),一致性(所有应用访问得到相同的数据)。无法同时满足。
大型网站可能放弃一定的一致性。把一致性细分:
- 强一致性 各个副本总是一致的
- 数据用户一致 保证终端用户访问时,通过纠错和校验,确定一个一致且正确的数据返回给用户。
- 数据最终一致性 同一用户连续访问结果不同。 但是系统经过一段时间能够自我恢复和修正。
应该做到用户一致性
数据备份
冷备:无法保证最终一致性和可用性(因为恢复时间太多)
热备:
- 异步热备 只写主存储区。 异步线程同步写从存储区
- 同步热备 同时写主备连个存储区。mysql支持半同步,保证至少有一个备写完。
读写分离也是基于数据备份
失效转移
重新路由的过程
- 失效确认 心跳检测和应用程序访问失败报告 一般访问失败了还是需要再次发一次心跳,防止误判。
- 访问转移 重新路由,如果是对等的,直接路由就行了。但是如果是不对等的,就要根据路由算法,重新算数据等等。
- 数据恢复 转移之后修复宕机的服务,然后重新加入集群
高可用的软件质量保证
- 网站发布,自动化发布过程,减少人为操作带来的问题
- 自动化测试 Selenium等。
- 预发布 通过host访问,没有配置到vip或者负载均衡中。 注意不要因为预发布而导致了问题,比如修改了线上的金额等
- 代码控制。 分支开发主干发布?
 火车发布模型。注意,可能有重要客人,没他火车就不开
火车发布模型。注意,可能有重要客人,没他火车就不开 - 灰度发布 如果发布失败,就要回滚,这个时候,可能会耽误很长时间,因此可以先发灰度组运行一段时间,如果不错,再发剩下的
网站运行监控
监控数据采集
- 用户行为日志?
用户的操作系统,浏览器,ip地址,访问路径,页面停留时间等,用于分析用户行为,优化网站设计,个性化营销与推荐。?
- 服务器端日志收集 开启web容器的日志功能即可。 缺点是可能会失真
- 客户端浏览器日志手机。 需要专门JS脚本
- 使用Storm等统计分析工具
- 服务器性能监控?
系统Load,内存,磁盘,IO。等进行预警。 目前的开源工具是Ganglia - 报告, 设置阈值,进行告警
监控管理
采集之后可以对系统性能评估,集群规模伸缩性预测,进行风险预警,自动负载调整等。
主要用来做如下的功能: 系统报警,失效转移,自动优雅降级
cs