# 1、如果字符串内部既包含'又包含"怎么办?
# 可以用转义字符`\`来标识
print("北京的金山上,"光芒"照四方。") # SyntaxError: invalid syntax
# 使用转义字符解决
print("北京的金山上,\"光芒\"照四方。")
# 使用上边说的引号之间的嵌套解决
print('北京的金山上,"光芒"照四方。')
"""
# 2、转义字符`\`可以转义很多字符,
比如`\n`表示换行,
`\t`表示制表符,
字符`\`本身也要转义,所以`\\`表示的字符就是`\`,
"""
# 输出结果:子曰:"学而时习之,\\n乐呵乐呵!"
s = "子曰:\"学而时习之,\\\\n乐呵乐呵!\""
print(s)
(3)常用转义字符对照表
| 转义字符 |
描述 |
\(在行尾时) |
续行符 |
\\ |
反斜杠符号 |
\' |
单引号 |
\" |
双引号 |
\a |
响铃 |
\b |
退格(Backspace) |
\e |
转义 |
\000 |
空 |
\n |
换行 |
\v |
纵向制表符 |
\t |
横向制表符,一个tab键(4个空格)的距离 |
\r |
回车 |
\f |
换页 |
\oyy |
八进制数,yy代表的字符,例如:\o12代表换行 |
\xyy |
十六进制数,yy代表的字符,例如:\x0a代表换行 |
\other |
其它的字符以普通格式输出 |
提示:转义、去转义在线工具:http://www.bejson.com
3、字符编码
字符串有一个比较特殊的问题,就是编码问题。
(1)字符编码介绍
1)字符编码的由来:
因为计算机只能处理二进制数字,也就是0和1。如果要处理文本,就必须先把文本转换为数字才能处理。
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
2)Unicode编码介绍:
如上所述,Unicode编码应运而生,又称为万国码。Unicode编码把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode编码标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode编码。
3)UTF-8编码介绍:
然而新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode编码字符根据不同的数字大小编码成1-6个字节【8个比特(bit)作为一个字节(byte)】,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符(如果统一标准的话,一个英文字符要补2-3个字节的0),用UTF-8编码就能节省空间。
如下图所示:

因为我们编写的代码文件中,绝大部分都是英文,所以我们常用的编码格式为UTF-8编码。
UTF-8编码还有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
(2)Python中的字符编码
Python3的默认编码是UTF-8编码,可通过如下代码查看。
import sys
# 可查看Python3的默认编码。
print(sys.getdefaultencoding())
# 下面的方式也可以查看
print(sys.stdout.encoding)
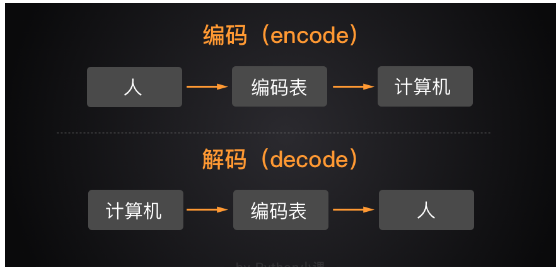
Python3中字符编码经常会使用到decode和encode函数。特别是在抓取网页中,这两个函数用的熟练非常有好处。
encode(编码)的作用,使我们看到的直观的字符转换成计算机内的字节形式。decode(解码)刚好相反,把字节形式的字符转换成我们看的懂的、直观的、“人模人样”的形式。
如下图所示:
(3)编码格式应用于不同场景
数据在内存当中处理时,使用的格式是Unicode,统一标准。
在硬盘上存储,或者是在网络上传输时,用的是UTF-8,因为省空间。
参考:https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896
bk