БОЮФвбећРэжТЮвЕФ github ЕижЗ https://github.com/allentofight/easy-cs ЃЌЛЖгДѓМв star жЇГжвЛЯТ
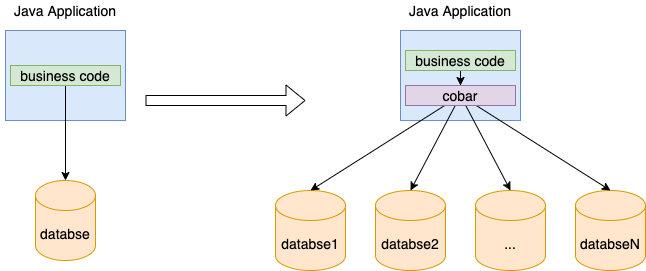
етЪЧвЛИіРЇШХЮвЫОгЩРДвбОУЕФЮЪЬтЃЌНќФъРДЫцзХЮвЫОвЕЮёЕФМБхсЗЂеЙЃЌЕЅБэЪ§ОнСПдНРДдНДѓЃЌетбљЛсЕМжТЖСаДадФмМБхсЯТНЕЃЌздШЛЖјШЛЕФЮвУЧЯыЕНСЫЗжПтЗжБэЃЌВЛЙ§жкЫљжмжЊЗжПтЗжБэЙцдђБШНЯИДдгЃЌЖјЧввЕЮёДњТыПЩФмашвЊДѓИФЃЈгЩгкЪ§ОнЗжВМдкВЛЭЌЕФПтБэРяЃЌвЕЮёашвЊХаЖЯЕНЕзШЅФФаЉБэШЁЪ§ЃЌВЂЧвШЁЭъКѓашвЊНЋЪ§ОндйОлКЯдквЛЦ№ЗЕЛиЧАЖЫЃЉЃЌЫљвдОЙ§КсЯђЖдБШЮвУЧВЩгУСЫАЂРяПЊдДЕФЗжПтЗжБэжаМфМў CobarЃЌетбљЕФЛАвЛРД Cobar ИљОнЮвУЧЩшЖЈЕФЙцдђЗжПтЗжБэСЫЃЌЖўРДдРДЕїгУ SQL ЕФЕиЗНжЛашИФГЩЕїгУ Cobar МДПЩЃЌCobar ЛсздЖЏИљОнЮвУЧаДЕФ SQL ШЅИїИіЗжПтЗжБэРяВщбЏВЂНЋНсЙћЗЕЛиИјЮвУЧЃЌЮвУЧвЕЮёВуЕФДњТыМИКѕВЛашвЊИФЖЏЃЈМДЖдгІгУЪЧЭИУїЕФЃЉ
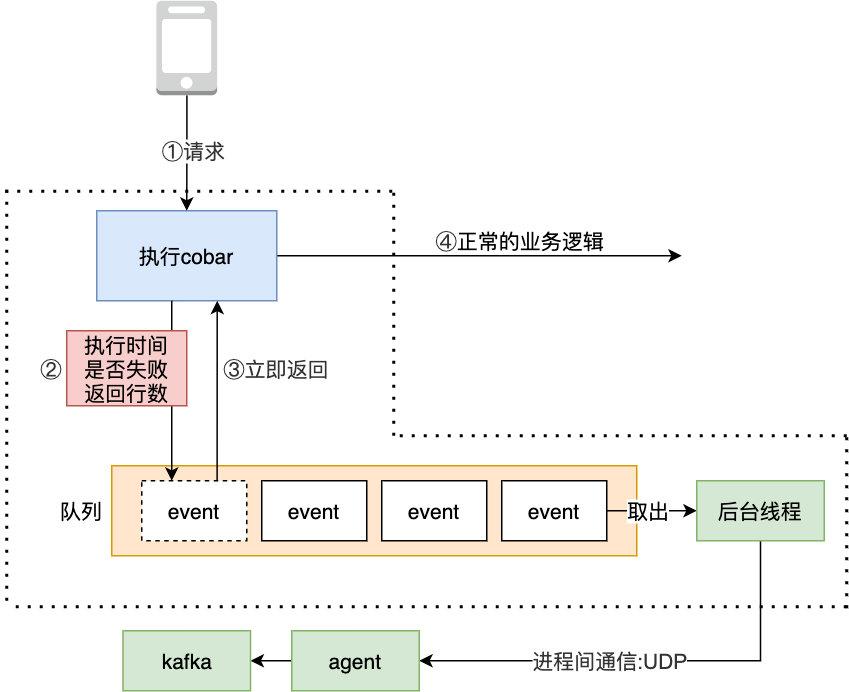
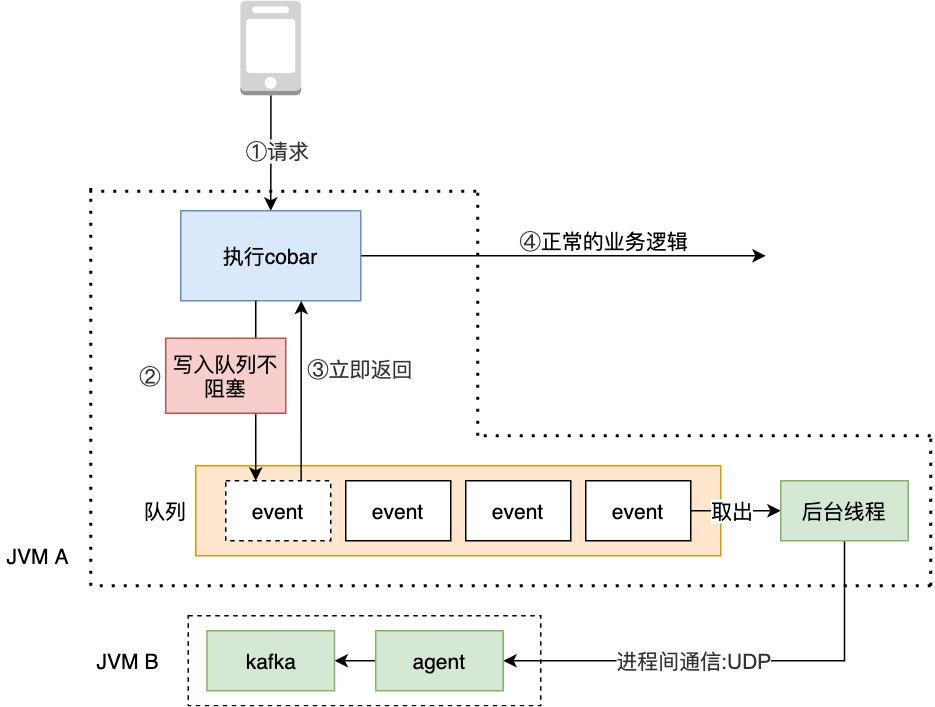
ШчЭМЪОЃКЪЙгУ cobar НјааЗжПтЗжБэКѓЃЌПЩвдПДЕНвЕЮёДњТыМИКѕВЛашвЊИФЖЏ
ЫљвдЮЪЬтЪЧЃП
ЪЙгУ Cobar ШЗЪЕНтОіСЫЗжПтЗжБэКЭЖдвЕЮёДњТыЧжШыадЕФЮЪЬтЃЌЕЋгЩгкгжв§ШыСЫвЛИіжаМфВуЃЌЕМжТПЩгУадНЕЕЭЃЌЮЊСЫЗРжЙ Cobar ВЛПЩгУЕШдьГЩЕФгАЯьЃЌЮвУЧашвЊМрПи Cobar ЕФИїЯюадФмжИБъЃЌШч SQL жДааЪБМфЃЌЪЧЗёЪЇАмЃЌЗЕЛиааЪ§ЕШЃЌетбљЗНБуЮвУЧЗжЮі Cobar ЕФИїЯюжИБъЃЌетОЭЪЧЮвУЧГЃЫЕЕФ SQL ЩѓМЦ ЃЈМЧТМЪ§ОнПтЗЂЩњЕФИїжжЪТМўЃЉЃЌФЧдѕУДбљВХФмИпаЇ МЧТМетаЉЪТМўЖјгжВЛЖджДаавЕЮёДњТыЕФЯпГЬдьГЩгАЯьФи?
вЊМЧТМЩЯБЈетаЉЩѓМЦЪТМўЃЌПЯЖЈВЛФмдкжДаавЕЮёДњТыЕФЯпГЬРяжДааЃЌвђЮЊетаЉЪТМўЪєгквЕЮёЮоЙиЕФДњТыЃЌШчЙћдквЕЮёЯпГЬРяжДааЃЌвЛРДКЭвЕЮёДњТыХККЯЃЌЖўРДШчЙћетаЉЩѓМЦЪТМўДЋЪфЃЈМЧТМЩѓМЦЪТМўзмвЊЭЈЙ§ДХХЬЛђЭјТчМЧТМЯТРДЃЉгіЕНЦПОБЛсЖде§ГЃЕФвЕЮёТпМдьГЩбЯжигАЯьЁЃЮвУЧПЩвдаоИФвЛЯТ cobar ДњТыЃЌдк cobar РяЕФжДааТпМжаФУЕНетаЉЪТМўКѓЃЌАбетаЉЪТМўЯШЛКДцдкЖгСажаЃЌШУСэЭтЕФЯпГЬДгетаЉЖгСаРяТ§Т§ШЁГіЃЈЯћЗбЃЉЃЌШЛКѓдйНЋетаЉЪ§ОнЩЯБЈЃЌетбљвЕЮёЯпГЬПЩвдСЂМДЗЕЛижДааЦфЫће§ГЃЕФвЕЮёТпМЁЃ
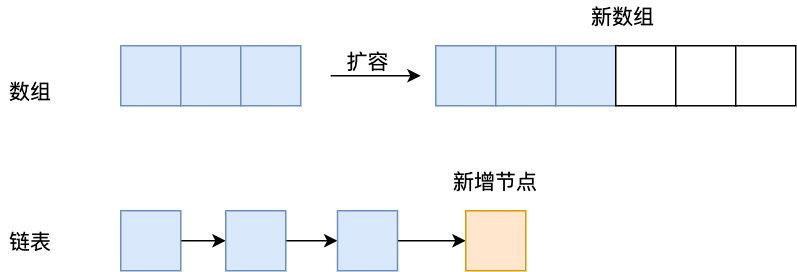
2 (1) зЂЃКащЯпВПЗжЮЊЖд cobar жаМфМўЕФИФдьЃЌвЕЮёЕїгУЪЧЮоИажЊЕФ
ШчЭМЪОЃЌжївЊВНжшШчЩЯЭМЫљЪО
cobar жДааКѓНЋЁИжДааЪБМфЁЙ,ЁИЪЧЗёЪЇАмЁЙ,ЁИЗЕЛиааЪ§ЁЙЕШаДШыЖгСа аДШыЖгСаКѓвЕЮёЯпГЬСЂМДЗЕЛиЃЌШЛКѓПЩвджДаае§ГЃЕФвЕЮёТпМ КѓЬЈЯпГЬдђВЛЖЯШЁГі event ЭЈЙ§ UDP ДЋИјСэЭтвЛИіЛњЦїЃЌаДШы kafka НјааЩЯБЈ
аЁЛязгВЛДэАЁЃЌвЛПДетМмЙЙЭМОЭжЊЕРгаЕуЖЋЮїЃЌЕЋЮветРягаЕувЩЮЪЃЌдкЕкЖўВНжаЃЌЮЊЩЖВЛАб SQL ЩѓМЦЕФФЧаЉжИБъжБНгаДШы kafka ФиЃЌШчЯТ
kafaka ВЛЪЧКХГЦаДШыадФмПЩДяМИЪЎЩѕжСЩЯАйЭђТ№ЃЌЯёЩЯЪіетбљЪЕЯжМмЙЙЩЯЪЕЯжВЛЪЧИќМђЕЅТ№
етЪЧИіКмКУЕФЮЪЬтЃЌгавдЯТСНИідвђ
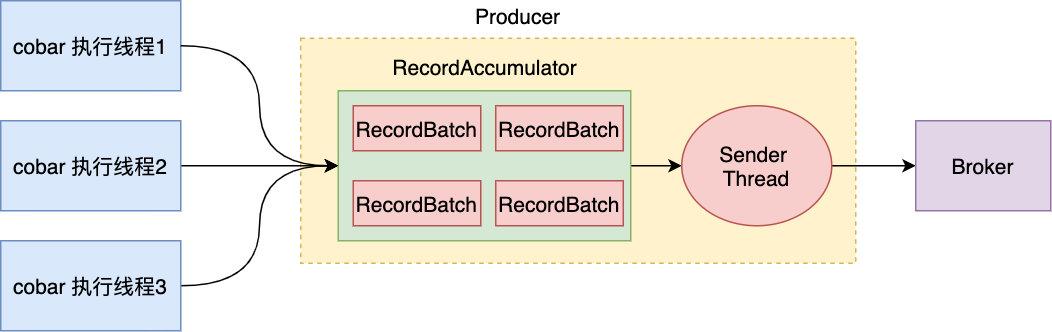
ЮвУЧЪЧЖд cobar ЙЄГЬБОЩэНјаааоИФЃЌШЛКѓНЋЦфДђГЩ jar АќдйМЏГЩЕНгІгУГЬађжаРДЕФЃЌШчЙћВЩгУЩЯУцЕФЩшМЦЃЌФЧОЭвтЮЖзХвЊдк cobar ЙЄГЬжав§ШыЖд kafka ЕФвРРЕЃЌЖјЮвУЧжЛЯыЖд cobar зїЩйСПЕФаоИФЃЌВЛЯывРРЕЬЋЖрЕкШ§ЗНЕФПт етвВЪЧзюживЊЕФЃЌв§Шы kafka БОЩэЛсЕМжТПЩгУадНЕЕЭЃЌгаПЩФмЛсзшШћвЕЮёЯпГЬ ЃЌдк kafka Producer жаЃЌЩшМЦСЫвЛИіЯћЯЂЛКГхГиЃЌПЭЛЇЖЫЗЂЫЭЕФЯћЯЂЪзЯШЛсБЛДцДЂЕНЛКГхГижаЃЌЭЌЪБ Producer ЦєЖЏКѓЛЙЛсЦєЖЏвЛИі sender ЯпГЬВЛЖЯЕиЛёШЁЛКГхГижаЕФЯћЯЂНЋЦфЗЂЫЭЕН Broker жа
ШчЭМЪОЃЌЮвУЧдкЙЙНЈ kafka producer ЪБЃЌЛсгавЛИіздЖЈвхЛКГхГиДѓаЁЕФВЮЪ§ buffer.memoryЃЌФЌШЯДѓаЁЮЊ 32MЃЌвђДЫЛКГхГиЕФДѓаЁЪЧгаЯожЦЃЌФЧШчЙћетИіЛКДцГиТњСЫдѕУДАьЃЌRecordAccumulator ЪЧ Kafaka ЛКГхГиЕФКЫаФРрЃЌЙйЗНЖдЦфзЂЪЭаДЕУЗЧГЃЧхГў
The accumulator uses a bounded amount of memory and append calls will block when that memory is exhausted, unless this behavior is explicitly disabled.
вВОЭЪЧЫЕШчЙћЛКДцГиТњ СЫЃЌЯћЯЂзЗМгЕїгУНЋЛсБЛзшШћЃЌжБЕНгаПеЯаЕФФкДцПщ ЃЌетбљЕФЛАжЛвЊ Kafka МЏШКИКдиКмИпЛђепЭјТчЩдгаВЈЖЏЃЌSender ЯпГЬДгЛКГхГиРЬШЁЯћЯЂЕФЫйЖШИЯВЛЩЯПЭЛЇЖЫЗЂЫЭЕФЫйЖШЃЌОЭЛсдьГЩПЭЛЇЖЫЃЈвВОЭЪЧ Cobar жДааЯпГЬЃЉЗЂЫЭБЛзшШћЃЌетбљЕФЛАПЩФмЕМжТЯпЩЯМИКѕЫљгаНгПкЕїгУбЉБРЃЌЯЕЭГВЛПЩгУЃЌЕМжТбЯжиЕФджФб!
ЖјдРДЕФЩшМЦПДЫЦИДдгЃЌЕЋЪЕМЪЩЯЗћКЯШэМўЩшМЦжаЕФЗжВуддђЃЌетбљЕФЩшМЦгаСНИіКУДІЃЌШчЯТЭМЪОЃК
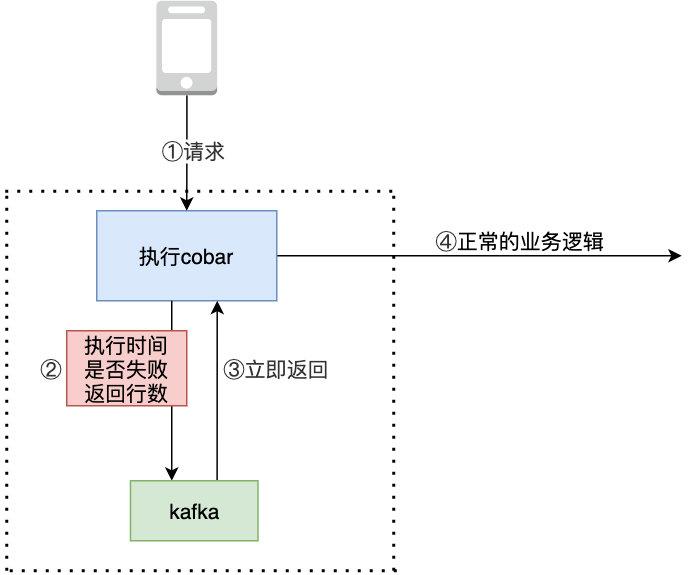
ЪзЯШ Cobar жДааЯпГЬНЋЩѓМЦаХЯЂЖЊИјЖгСаКѓСЂМДЗЕЛиЃЌЮвУЧжЛвЊЩшМЦетбљЕФВЛзшШћИпаЇЕФЖгСа МДПЩ КѓЬЈЯпГЬШЁГіКѓЭЈЙ§ UDP ДЋИјСэЭтЕФ agentЃЌCobar жДааЯпГЬЫљдкЕФ JVM КЭ agent ЕФ JVM ЪЧВЛЭЌЕФЃЈБЯОЙВПЪ№дкВЛЭЌЕФЛњЦїЩЯЃЉЃЌзіЕНСЫ JVM ЕФИєРыЃЌвВИќАВШЋ
аЁЛязгЙћШЛгаСНАбЫЂзгЃЌЕЅЖРСрГіЩЯЭМЕФ cobar жДааЯпГЬгыКѓЬЈЯпГЬЭЈЙ§ЖгСаЭЈаХЕФФЃПщЃЌПЩвдПДЕНЫќОЭЪЧИіЕфаЭЕФЩњВњепЯћЗбепФЃаЭ
cobar жДааЯпГЬаДШыЖгСаЮоТлШчКЮЖМВЛЛсзшШћ аДШыЖгСавЊзуЙЛПьЃЈЭЬЭТТЪвЊИпЃЉЃЌБЯОЙЮвЫОЪЧДѓГЇЃЌслЗхЦкПЩФмЛсДяЕНУПУыМИЭђЕФ QPS
УЛДэЃЌВЛРЂЪЧДѓРаЃЌвЛблПДЭИЮЪЬтЕФБОжЪЃЌжЛвЊФмЩшМЦКУетбљЕФЖгСаЃЌЫљгаЮЪЬтОЭгШаЖјНтСЫ
ЖїЃЌФЧФуОЭРДЬИЬИШчКЮЩшМЦетбљЕФЖгСаАЩЁЃ
ЫфШЛЮваФжавбОгаЪ§ЃЌЕЋЮЊСЫеЙЪОЮвИпГЌЕФДЕХЃ ЖдЖгСаЪьСЗдЫгУЕФФмСІЃЌЮвОіЖЈгЩЧГШыЩюЕиРДНВНтвЛЯТЖгСаЕФбнНјЪЗЃЌетбљПЩвдАбЖгСаЕФбЁаЭСЫНтЕУУїУїАзАз
ФуИпаЫОЭКУЁЃ
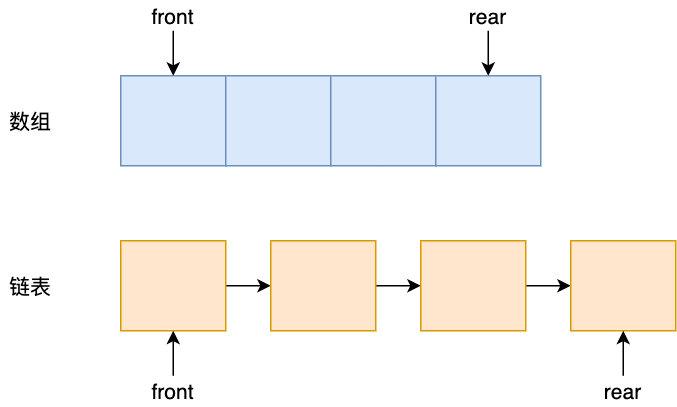
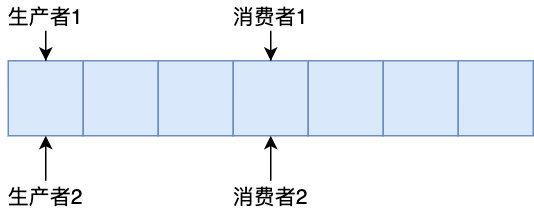
ИпадФмЖгСаЕФЪЕЯжЫМТЗ 1.ЖгСаЕФБэЪОЃКЪ§зщ or СДБэ? ЖгСаЃЈQueueЃЉЪЧвЛжжЯпадБэЃЌЪЧвЛжжЯШНјЯШГіЕФЪ§ОнНсЙЙЃЌжївЊгЩЪ§зщКЭСДБэзщГЩЃЌЖгСажЛдЪаэдкКѓЖЫЃЈГЦЮЊ rearЃЉНјааВхШыВйзїЃЌдкЧАЖЫЃЈГЦЮЊ frontЃЉНјааЩОГ§Вйзї
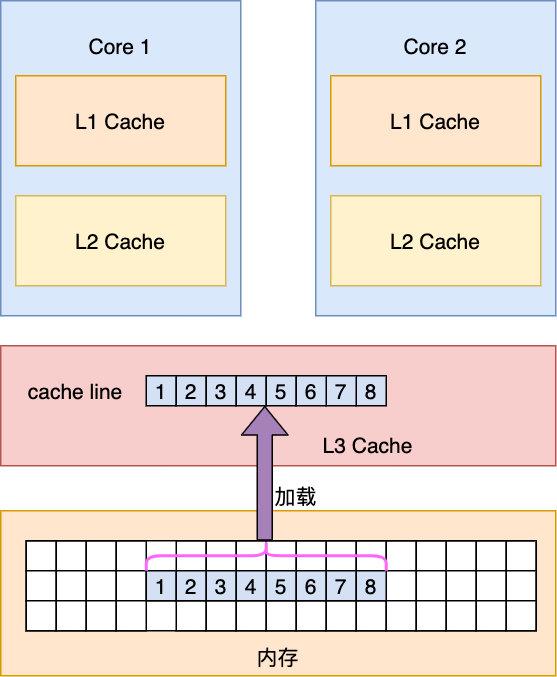
ЖгСаЕФСНжжБэЯжаЮЪН етСНепгХШБЕуЖМКмУїЯдЃЌЕЋзмЕФРДЫЕЪ§зщЕФжДаааЇТЪИќИпЃЌЮЊЩЖЃЌетРяМђЕЅНщЩмЯТ CPU ЕФдЫаадРэЃЌгЩгкФкДцЬЋТ§ЃЌЫљвддк CPU КЭ ФкДцМфЩшжУСЫЖрЕРЛКДцЃЈL1ЃЌL2ЃЌL3Ш§МЖЛКДцЃЌЦфжа L1,L2 ЛКДцЮЊУПИі CPU КЫЖРгаЕФЃЌ L3ЪЧЙВЯэЕФЃЉвдЬсЩ§ CPU ЕФжДаааЇТЪЃЌCPU жДааШЁЪ§ЪБЃЌЯШДг L1ВщевЃЌУЛгадйДг L2ВщевЃЌL2 УЛгадђДг L3ЃЌВщевЃЌL3ЛЙЪЧУЛгаЕФЛАОЭЛсДгФкДцМгдиЁЃ
ЕЋашвЊзЂвтЕФЪЧЃЌCPU ДгФкДцМгдиЪ§ОнЪБВЂВЛЪЧвдзжНкЮЊЕЅЮЛМгдиЃЌЫќЪЧвд cacheline ЕФаЮЪНРДМгдиЕФЃЌcacheline ЪЧДгФкДцМгдиЛђаДШыЕФзюаЁЕЅЮЛЃЌдк X86 МмЙЙжаЃЌвЛИіcacheline гЩФкДцРяСЌајЕФ 64 Иі byteзщГЩЕФЃЌЖјЪ§зщЪЧдкФкДцРяСЌајЗжХфЕФЃЌЫљвдЫќвЛДЮадФмБЛМгдиЖрИіЪ§ОнЕН cache жаЃЌЖјСДБэжа node ЕФПеМфЪЧЗжЩЂдкЗЧСЌајЕФФкДцЕижЗПеМфжаЃЌЫљвдзмЕФРДЫЕЪ§зщгЩгкРћгУСЫ cache line ЕФСЌајМгдиЬиадЖдЛКДцИќгбКУЃЌадФмЛсИќКУЁЃ
СДБэЖдРЉШнИќгбКУЃП
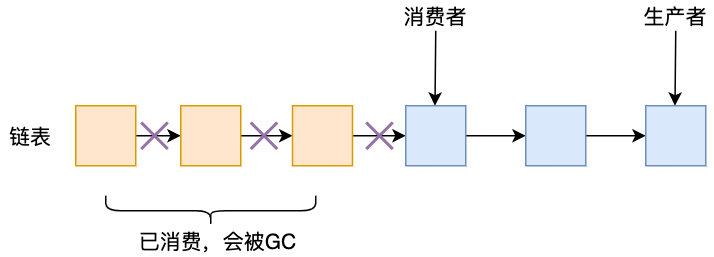
етгІИУЪЧВЛЩйШЫжЇГжЪЙгУСДБэЕФвЛИіживЊдвђСЫЃЌШчЙћПеМфВЛЙЛДѓЃЌашвЊРЉШндѕУДАьЃЌЖдгкСДБэРДЫЕЃЌКмМђЕЅЃЌдк rear НсЕуКѓаТдівЛИіНкЕуЃЌНЋ rear НсЕуЕФ next жИеыжИЯђЫќМДПЩЃЌЗЧГЃЗНБуЃЌЕЋЖдгкЪ§зщРДЫЕОЭУЛФЧУДШнвзСЫЃЌЫќашвЊЯШЩњГЩвЛИідРД nЃЈвЛАуЪЧ 2ЃЉ БЖДѓаЁЕФаТЪ§зщЃЌдйАбРЯЪ§зщРяЕФЪ§ОнИјвЦЙ§ШЅЃЌШчЯТЭМЫљЪО
ШчЙћЙтДгРЉШнетвЛНЧЖШРДПДЃЌШЗЪЕСДБэИќгХауЃЌЕЋЮвУЧВЛвЊЭќСЫЯћЗбепЯћЗбЭъКѓЪЧвЊАбСДБэЖдгІЕФНкЕуИјЪЭЗХЕєЕФЃЌдкИпВЂЗЂЯТЃЌОЭЛсдьГЩЦЕЗБЕФ GCЃЌдьГЩбЯжиЕФадФмгАЯь
ЙРМЦгаШЫОЭЛсЗДВЕСЫЃЌШчЙћЪ§зщжаЕФдЊЫиБЛЯћЗбЭъСЫЃЌФбЕРВЛвЊБЛвЦГ§ЃПетбљЕФЛАЦёВЛЪЧвВЛсДцдкИпВЂЗЂЯТЕФЦЕЗБ GCЃПзмВЛФмвЛПЊЪМИјетИіЪ§зщЗжХфвЛИіЮоЯоДѓЕФПеМфАЩЃЌетбљЕФЛАОЭГЩСЫЮоНчЖгСа ЃЌетбљЕФЛАЛЙУЛЕШФуЪ§зщЬюТњОЭ OOM СЫЁЃ
етЪЧИіКУЮЪЬтЃЌЪЕМЪЩЯЖдгкЪ§зщРДЫЕЃЌЮвУЧПЩвдЪЙгУвЛИіаЁ trickЃЌМШПЩвдШУЫќБфГЩгаНчЃЈМДЙЬЖЈДѓаЁЃЌЮоашРЉШнЃЉЪ§зщЃЌвВПЩвдБмУтЦЕЗБ GCЃЌИќПЩвдБмУтЪ§зщРЉШнДјРДЕФадФмЮЪЬтЃЌдѕУДзіЃЌНЋЯпадЪ§зщИФдьГЩбЛЗЪ§зщЃЈRingBufferЃЉ
2 ШчЭМЪОЃЌМйЩшЪ§зщЕФГѕЪМЛЏДѓаЁЮЊ 7ЃЌЕБЩњВњепАбЪ§зщЕФЦпИідЊЫиЖМЬюТњЪБЃЈДЫЪБ 0ЃЌ1ЃЌ2Ш§ИідЊЫивбОБЛЯћЗбепЯћЗбЭъСЫЃЉ,ШчЙћЩњВњепЛЙЯыдйЬюГфЪ§ОнЃЌгЩгк 0ЃЌ1ЃЌ2ЖдгІЕФШ§ЮЛдЊЫивбОБЛЯћЗбСЫЃЌЪєгкЙ§ЦкЮоаЇЕФдЊЫиСЫЃЌЫљвдЩњВњепПЩвдДгЭЗПЊЪМЭљРяЬюГфдЊЫиЃЌжЛвЊВЛГЌЙ§ЯћЗбепЕФНјЖШМДПЩЃЌЭЌРэЃЌШчЙћЯћЗбепЖдгІЕФжИеыДяЕНЪ§зщЕФФЉЖЫЃЌЯТвЛДЮЯћЗбвВОЭЛиЕНЪ§зщЯТБъ 0 ПЊЪМЯћЗбЃЌжЛвЊВЛГЌЙ§ЩњВњепНјЖШМДПЩЁЃ
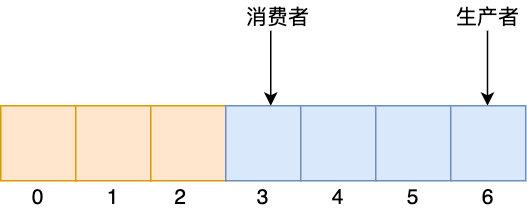
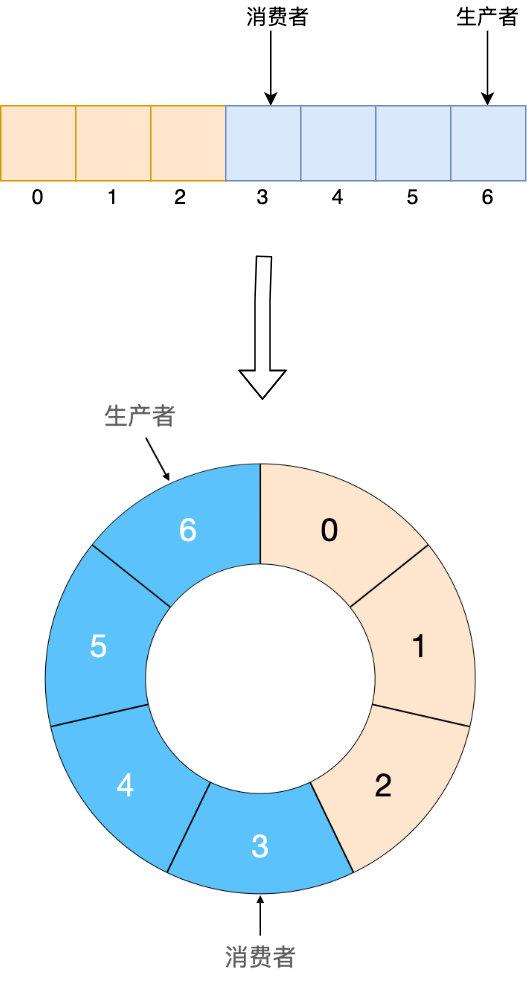
ЮвУЧНЋНЋЪ§зщЕФЪзЮВЦДНгОЭаЮГЩСЫвЛИі ringbuffer
ringbuffer гаШЫЛсЫЕШЦШІСЫдѕУДЖЈЮЛЪ§зщЕФОпЬхЯТБъЃПЖдЪ§зщДѓаЁШЁФЃМДПЩЃЌЩњВњеп/ЯћЗбепЖдгІЕФЪ§зщЯТБъЖМЪЧРлМгЕФЃЌвдвдЩЯЧщПіЮЊР§ЃЌЕБЧАЩњВњепЕФЯТБъЮЊ 6ЃЌЯТвЛИіЯТБъОЭЪЧ 7ЃЌЖјЕБЧАЪ§зщДѓаЁЮЊ 7ЃЌгкЪЧ 7 ЖдгІЕФЪ§зщЯТБъМДЮЊ 7%7 = 0ЃЌгыЪЕМЪЯрЗћЁЃЕЋашвЊзЂвтЕФЪЧШЁФЃВйзїЪЧИіКмАКЙѓЕФВйзїЃЌЫљвдЮвУЧПЩвдгУЮЛдЫЫуРДДњЬцЃЌЕЋЮЛдЫЫувЊЧѓЪ§зщЕФДѓаЁЮЊ 2^nЃЈЯыЯыЮЊЪВУДЃЉЃЌгкЪЧШЁФЃВйзїПЩвдгУ index & (2^n -1 ) РДДњЬцЃЈindex ЮЊ ЩњВњеп/ЯћЗбепЖдгІЕФЯТБъЃЉЁЃ
злЩЯЃЌЩшМЦвЛИіетбљДѓаЁЮЊ 2^nЃЈетРягаСНВуКЌвхЃЌвЛЪЧДѓаЁЮЊ 2^nЃЌЖўЪЧЪ§зщгаНчЃЉ ЧвгЩЪ§зщБэЪОЕФ ringbuffer гаЁИЖдЛКДцгбКУ ЁЙЃЌЁИЖд GC гбКУ ЁЙСНИіживЊЬиадЃЌдкИпВЂЗЂЯТЖдадФмЕФЬсЩ§ЪЧЗЧГЃгаАяжњЕФЁЃ
2. ЮоЫј жЛбЁКУ ringbuffer ЪЧВЛЙЛЕФЃЌдкИпВЂЗЂЯТЃЌЖрИіЩњВњеп/ЯћЗбепМЋгаПЩФмељгУ ringbuffer ЕФ ЭЌвЛИі indexЃЌШчЯТЭМЪОЃК
ЮЊСЫБмУтетжжЧщПіЃЌзюШнвзЯыЕНЕФЪЧМгЫјЃЌЕЋЯдШЛМгЫјЛсДцдкбЯжиЕФадФмЮЪЬтЃК
ЯпГЬШчЙћељгУВЛЕНЫјЪЇАмЃЌЛсзшШћЃЈгЩгУЛЇЬЌНјШыФкКЫЬЌЃЉЃЌЛНабЪБгжЛсДгФкКЫЬЌНјШыгУЛЇЬЌЃЌЮвУЧжЊЕРетжжВЛЖЯЕидкгУЛЇЬЌКЭФкКЫЬЌМфНјааЧаЛЛЕФВйзїЪЧЗЧГЃАКЙѓЕФ






 ЫљвдЯждкЮЪЬтЕФЙиМќОЭзЊЛЏЮЊШчКЮЩшМЦетбљЕФЖгСаСЫЃЌЫќвЊТњзуСНИіЬѕМў
ЫљвдЯждкЮЪЬтЕФЙиМќОЭзЊЛЏЮЊШчКЮЩшМЦетбљЕФЖгСаСЫЃЌЫќвЊТњзуСНИіЬѕМў