??�ع����ڽ�ģ���������ڷ�������֮��Ĺ�ϵ���Լ����������Ӱ������һ�ַ���������
??���������ֻع鷽��:���Իع�(linear regression)������ʽ�ع�(ploynomia regressionl)����ع�(ridge regression)��Lasso�ع�͵��Իع�����
1 ���Իع�
??���Իع���ָȫ�������Ա�����ɵĻع�ģ��,���絥�������Իع�ģ��
Y
=
a
?
X
+
b
Y=a?X+b
Y=a?X+b
??��������Իع�ģ��:
Y
=
a
1
?
X
1
+
a
1
?
X
2
+
a
3
?
X
3
+
.
.
.
.
.
+
a
n
?
X
n
+
b
Y=a1?X1+a1?X2+a3?X3+.....+an?Xn+b
Y=a1?X1+a1?X2+a3?X3+.....+an?Xn+b
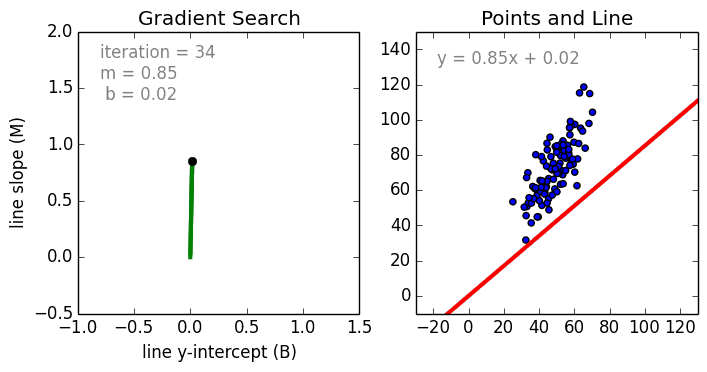
??����aΪϵ��,x�DZ���,bΪƫ�á���Ϊ�������ֻ�����Թ�ϵ,����ֻ�����ڽ�ģ���Կɷ����ݡ�����ֻ��ʹ��ϵ��Ȩ������Ȩÿ��������������Ҫ�ԡ�����ʹ������ݶ��½�(SGD)��ȷ����ЩȨ��a��ƫ��b,������ͼ��ʾ:
���Իع�ļ����ص�:
- ��ģ�ٶȿ�,����Ҫ�ܸ��ӵļ���,������������������Ȼ�����ٶȺܿ졣
- ���Ը���ϵ������ÿ������������ͽ���
- ���쳣ֵ������
2 ����ʽ�ع�
??���Իع��ʺ������Կɷֵ�����,�����Ǵ��������Կɷֵ�����ʱ����ʹ�ö���ʽ�ع顣�����ֻع���,������Ҫ�ҵ�һ��������������ݵ�,���Ա�ʾ�������ʽ��:
Y
=
a
1
?
X
1
+
a
2
?
X
2
+
a
3
?
X
3
+
.
.
.
+
a
n
?
X
n
+
b
Y=a_1?X_1+a_2?X_2+a_3?X_3+...+a_n?X_n+b
Y=a1??X1?+a2??X2?+a3??X3?+...+an??Xn?+b
??ѡ��ÿ��������ȷ�е�������Ҫ��ǰ���ݼ��������������һЩ����֪ʶ����������ͼ���������Իع������ʽ�ع�ıȽ�:
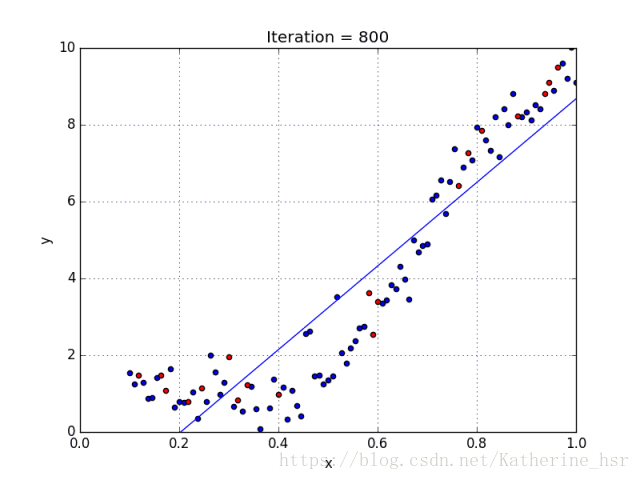
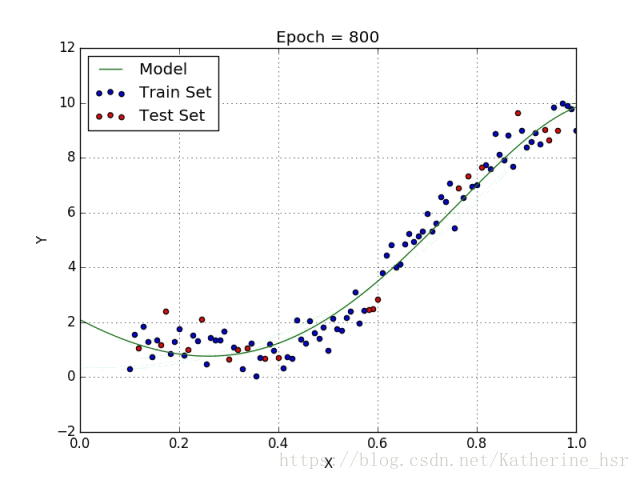
??����ʽ�ع��Ŀ�꺯��:��С���в�ƽ����,ͨ����ƫ�����Ż����⡣
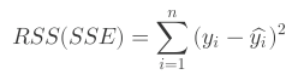
����ʽ�ع���ص�:
- �ܹ���Ϸ����Կɷֵ�����,�������Ĵ������ӵĹ�ϵ
- ��Ϊ��Ҫ���ñ�����ָ��,����������ȫ����Ҫ�ر����Ľ�ģ
- ��ҪһЩ���ݵ�����֪ʶ����ѡ�����ָ��
- ���ָ��ѡ�����׳��ֹ����
3 ��ع�(Ridge regression)
??������:collinearity,�Ա���֮����������Թ�ϵ,�����ͻ�Իع�������Ӱ�졣
??�߹����Ծ���ָ,�Ա���֮�������ij�ֺ�����ϵ,�����Ͳ��ܵõ���һ�����Խ����Ӱ���ˡ������Ҫ���ų��߹�����,�߹����Ե��жϿ���ͨ�����·�������:
- ���ܴ������Ͻ�,�ñ�����Y�߶����,���ǻع�ϵ��ȴ������
- ���ӻ�ɾ��X��������ʱ,�ع�ϵ���ᷢ�����Ա仯
- X�����������нϸߵijɶ������(pairwise correlations)(�����ؾ���)
??�����Իع���Ż���������:
m
i
n
�O
�O
X
w
?
y
�O
�O
2
min||Xw?y||^2
min�O�OXw?y�O�O2
??����X��ʾ��������,w��ʾȨ��,y��ʾ��ʵ�������ع������ģ���д��ڵĹ����Թ�ϵ��Ϊ��������һ��С��ƽ��ƫ������(Ҳ����������),���Ա�ʾ�������ʽ��:
m
i
n
�O
�O
X
w
?
y
�O
�O
2
+
z
�O
�O
w
�O
�O
2
min||Xw?y||2+z||w||^2
min�O�OXw?y�O�O2+z�O�Ow�O�O2
??������ƽ��ƫ��������ģ��������������ƫ��,���������˷��
��ع���ص�:
- ��ع�ļ������Сƽ���ع���ͬ,��������Сƽ���ع��ʱ�����Ǽ������ݷ��Ӹ�˹�ֲ�ʹ�õ��Ǽ�����Ȼ����(MLE),����ع��ʱ������������ƫ������,��w��������Ϣ,ʹ�õ��Ǽ���������(MAP)���õ����յIJ�����������Ȼ���ƺ���������ƿ�����
- û������ѡ����
4 Lasso�ع�
??����ع�����,���Ƕ���ʧ���������һ���ͷ���,Ҳ����������ع���õ���L2����,Lasso�ع���õ���L1����,
m
i
n
�O
�O
X
w
?
y
�O
�O
2
+
Z
�O
�O
w
�O
�O
min||Xw?y||^2+Z||w||
min�O�OXw?y�O�O2+Z�O�Ow�O�O
L1����L2������ϸ���⿴����:https://blog.csdn.net/jinping_shi/article/details/52433975 ���ߵ������
??L1���������ڲ���ϡ��ϵ��,��������������ѡ��,Ҳ������ѡ��L2�����ײ�����ϡ��ϵ��,���Բ�����������ѡ��,����ľ���������ֹ����ϡ�һ���̶���,L1����Ҳ���Է�ֹ������ϡ�
ϡ������ָ:�ܶ�Ԫ�ض���0,ֻ�м������ķ���Ԫ�ء������õ��Ĵֲ�����ϵ������0��
5 ���Իع�����
??���Իع�������Lesso�ع����ع鼼���Ļ���塣��ʹ����L1��L2����,Ҳ�ﵽ�����ּ������е�Ч��,���Իع�����ı���ʽ����:
m
i
n
�O
�O
X
w
?
y
�O
�O
2
+
z
1
�O
�O
w
�O
�O
+
z
2
�O
�O
w
�O
�O
2
min||Xw?y||^2+z1||w||+z2||w||^2
min�O�OXw?y�O�O2+z1�O�Ow�O�O+z2�O�Ow�O�O2
��Lasso����ع�֮�����Ȩ���һ��ʵ�������е���������ѭ��������¼̳���ع��һЩ�ȶ��ԡ�
���Իع�������ŵ�:
- �����ڸ߶���ر���������µ�Ⱥ��ЧӦ,������Lasso����������һЩ��Ϊ0.�������������һ��������ص�ʱ��������dz����á�Lasso���������ѡ������һ��,����������������ѡ��������
- ����ѡ����������û�����ơ�