1.股票预测
预测股市是机器学习在金融领域最重要的应用之一。在本文中,我将带您了解一个关于使用机器学习 Python 进行股票价格预测的简单数据科学项目。
在本文的最后,您将学习如何通过实现 Python 编程语言使用线性回归模型来预测股票价格。
自股市诞生以来,对其进行预测一直是投资者的祸根和目标。每天都有数十亿美元在股票交易所进行交易,每一美元背后都有一位投资者希望以某种方式获利。
整个公司每天的涨跌都取决于市场行为。如果一个投资者能够准确地预测市场走势,他就提供了一个诱人的财富和影响力的承诺。
1.1 数据准备
在上面的部分中,我通过导入python库开始了股票价格预测的任务。现在,我将编写一个函数来准备数据集,以便我们可以轻松地将其放入线性回归模型中:
def prepare_data(df,forecast_col,forecast_out,test_size):
label = df[forecast_col].shift(-forecast_out)
X = np.array(df[[forecast_col]])
X = preprocessing.scale(X)
X_lately = X[-forecast_out:]
X = X[:-forecast_out]
label.dropna(inplace=True)
y = np.array(label)
X_train, X_test, Y_train, Y_test = train_test_split(X, y, test_size=test_size, random_state=0)
response = [X_train,X_test , Y_train, Y_test , X_lately]
return response
df = pd.read_csv("prices.csv")
df = df[df.symbol == "GOOG"]
现在,我们需要准备三个输入变量,就像上面小节中创建的函数中准备的那样。我们需要声明一个输入变量,说明我们想预测哪一列。我们需要声明的下一个变量是我们希望预测的距离。
我们需要声明的最后一个变量是测试集的大小应该是多少。现在让我们声明所有的变量:
1.2 将机器学习应用于股票价格预测
现在我将对数据进行分割,并拟合到线性回归模型中:
X_train, X_test, Y_train, Y_test , X_lately =prepare_data(df,forecast_col,forecast_out,test_size);
learner = LinearRegression()
learner.fit(X_train,Y_train)
现在让我们预测产出,看看股票价格的价格:
score=learner.score(X_test,Y_test)
forecast= learner.predict(X_lately)
response={}
response['test_score']=score
response['forecast_set']=forecast
print(response)
{‘test_score’: 0.9481024935723803, ‘forecast_set’: array([786.54352516, 788.13020371, 781.84159626, 779.65508615, 769.04187979])}
2.美国总统身高统计
如果你是数据科学的初学者,你必须解决这个项目,因为你将学到很多关于处理来自csv文件或任何其他格式的数据的知识。
该数据可在文件height.Csv中找到,它是标签和值的简单逗号分隔列表:
链接:https://pan.baidu.com/s/1tW-3TBzCzyeX1U2vtdEhFw
提取码:qz25
data = pd.read_csv("heights.csv")
print(data.head())
我们将使用Pandas package 读取文件并提取此信息 (请注意,高度以厘米为单位):
height = np.array(data["height(cm)"])
print(height)

现在我们有了这个数据数组,我们可以计算各种摘要统计信息:
print("Mean of heights =", height.mean())
print("Standard Deviation of height =", height.std())
print("Minimum height =", height.min())
print("Maximum height =", height.max())

请注意,在每种情况下,聚合操作将整个数组简化为一个汇总值,这为我们提供了有关值分布的信息。我们也可以计算分位数:
print("25th percentile =", np.percentile(height, 25))
print("Median =", np.median(height))
print("75th percentile =", np.percentile(height, 75))

我们看到美国总统的平均身高是182厘米,或略低于6英尺。当然,有时查看这些数据的可视化表示会更有用,我们可以使用Matplotlib中的工具来完成:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
plt.hist(height)
plt.title("Height Distribution of Presidents of USA")
plt.xlabel("height(cm)")
plt.ylabel("Number")
plt.show()
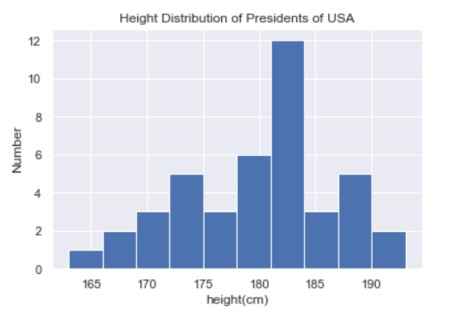
这些集合是探索性数据科学的一些基本部分,我们将在以后的项目中更深入地探讨。
3.出生率分析
让我们来看看美国疾病控制中心 (CDC) 提供的免费出生数据。这些数据可以在born s.csv中找到
链接:https://pan.baidu.com/s/1lrCuMvGGqtxfmuVHocZCpA
提取码:8ovj
import pandas as pd
births = pd.read_csv("births.csv") print(births.head()) births['day'].fillna(0, inplace=True) births['day'] = births['day'].astype(int)
births['decade'] = 10 * (births['year'] // 10)
births.pivot_table('births', index='decade', columns='gender', aggfunc='sum')
print(births.head())
我们立即看到,每十年男性出生数超过女性出生数。为了更清楚地看到这一趋势,我们可以使用Pandas 中的内置绘图工具来可视化按年出生的总数:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
birth_decade = births.pivot_table('births', index='decade', columns='gender', aggfunc='sum')
birth_decade.plot()
plt.ylabel("Total births per year")
plt.show()

3.1 进一步数据探索:
这里有一些有趣的特性,我们可以使用Pandas工具从这个数据集中提取出来。我们必须从清理数据开始,删除由于输入错误的日期或丢失的值而引起的异常值。一个简单的方法是一次性删除这些异常值,我们将通过一个健壮的sigma-clipping操作来做到这一点:
import numpy as np
quartiles = np.percentile(births['births'], [25, 50, 75])
mu = quartiles[1]
sig = 0.74 * (quartiles[2] - quartiles[0])
最后这条线是样本均值的稳健估计,其中0.74来自高斯分布的四分位数范围。这样我们就可以使用query()方法来过滤出这些值之外的诞生行:
births = births.query('(births > @mu - 5 * @sig) & (births < @mu + 5 * @sig)')
births['day'] = births['day'].astype(int)
births.index = pd.to_datetime(10000 * births.year +
100 * births.month +
births.day, format='%Y%m%d')
births['dayofweek'] = births.index.dayofweek
利用这个数据,我们可以连续几十年按工作日计算出生人数:
births.pivot_table('births', index='dayofweek',
columns='decade', aggfunc='mean').plot()
plt.gca().set_xticklabels(['Mon', 'Tues', 'Wed', 'Thurs', 'Fri', 'Sat', 'Sun'])
plt.ylabel('mean births by day');
plt.show()
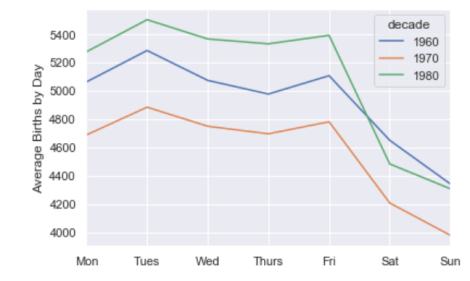
显然,周末出生的孩子比工作日出生的要少一些!需要注意的是,由于CDC的数据只包含了从1989年开始的出生月份,所以没有包括1990年代和2000年代。
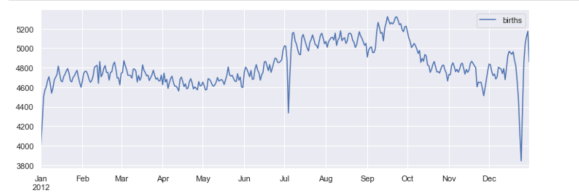
另一个有趣的观点是画出每年的平均出生人数。让我们首先将数据按月和日分别分组:
births_month = births.pivot_table('births', [births.index.month, births.index.day])
print(births_month.head())
births_month.index = [pd.datetime(2012, month, day)
for (month, day) in births_month.index]
print(births_month.head())

只关注月和日,我们现在有了一个时间序列,反映了每年出生的平均人数。由此,我们可以使用plot方法来绘制数据。它揭示了一些有趣的趋势:
fig, ax = plt.subplots(figsize=(12, 4))
births_month.plot(ax=ax)
plt.show()
4.时间序列数据科学项目-自行车计数
作为处理时间序列数据的一个例子,让我们看看西雅图弗里蒙特桥上的自行车数量。这些数据来自于2012年底安装的一个自动自行车计数器,它在大桥的东西两侧人行道上安装了感应传感器。每小时的自行车计数可以在这里下载。
一旦下载了这个数据集,我们就可以使用Pandas将CSV输出读取到一个DataFrame中。我们将指定我们想要的日期作为索引,并且我们想要这些日期被自动解析:
import pandas as pd
data = pd.read_csv("fremont-bridge.csv", index_col= 'Date', parse_dates=True)
data.head()
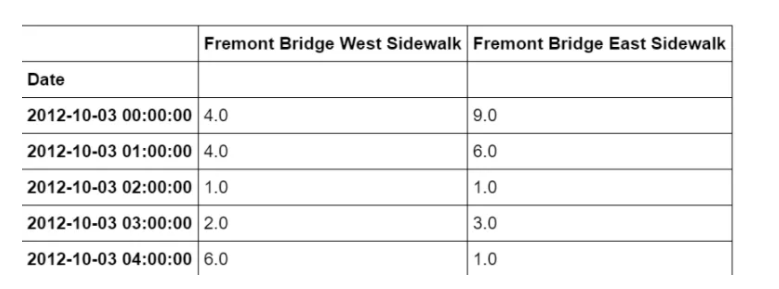
为方便起见,我们将通过缩短列名并添加 “总计” 列来进一步处理此数据集: