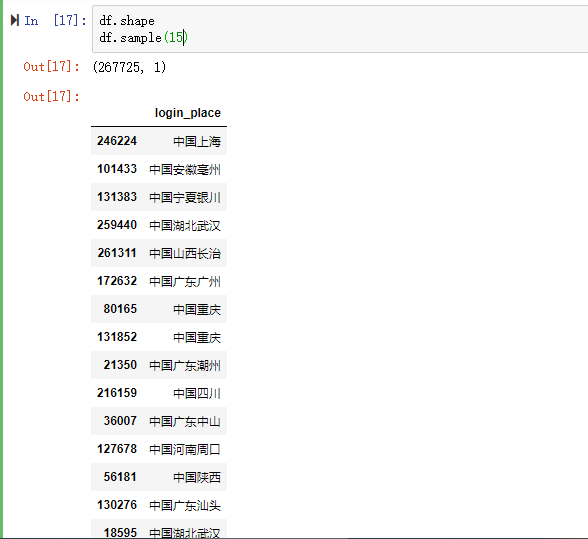
??КѓајЪ§ОнЗжЮіЙЄзїашвЊгУЕНЕиРэЮЌЖШНјааЗжЮіЃЌЫљвдашвЊАбlogin_placeзжЖЮНјааВ№ЗжГЩЃКЙњМвЁЂЪЁЗнЁЂЕиЧјЁЃ
%%time
# ЕиЧјВ№Зж
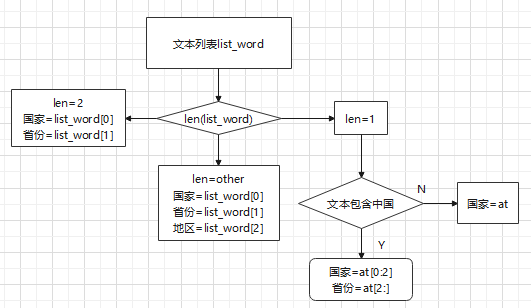
for i in range(1000):
list_word=[word for word in jieba.cut(df.iloc[i,0])]
if len(list_word)==1:
if 'жаЙњ' in df.iloc[i,0]:
df.loc[i,'ЙњМв']=df.iloc[i,0][0:2]
df.loc[i,'ЪЁЗн']=df.iloc[i,0][2:]
else:
df.loc[i,'ЙњМв']=df.iloc[i,0]
elif len(list_word)==2:
df.loc[i,'ЙњМв']=list_word[0]
df.loc[i,'ЪЁЗн']=list_word[1]
else:
df.loc[i,'ЙњМв']=list_word[0]
df.loc[i,'ЪЁЗн']=list_word[1]
df.loc[i,'ЕиЧј']=list_word[2]
if i%100==0:
print(f'{round(i*100/(int(1000)),2)}%')

??1000ЬѕгУСЫ1min 37УыЁЃШчЙћШЋВПНјааЪ§ОнНтЮіЕШД§ЪБМфгІИУКмОУКмОУЁЃгаКмЖржиИДЕФМЧТМЃЌетРяЯШШЅжиЃЌдйХмвЛДЮДњТыЁЃ
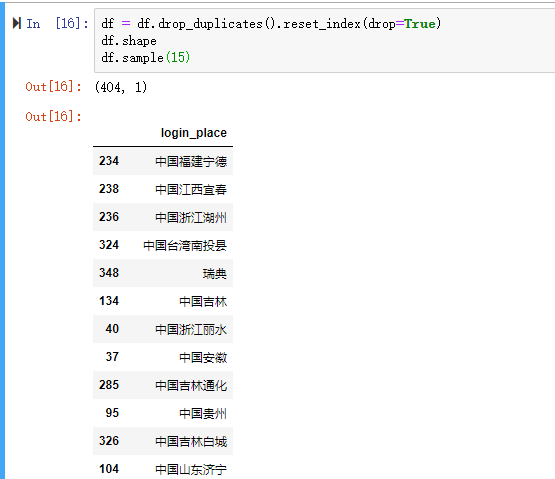
??ШЅжижЎКѓЃЌжЛга404ВЛжиИДЕФМЧТМЁЃ
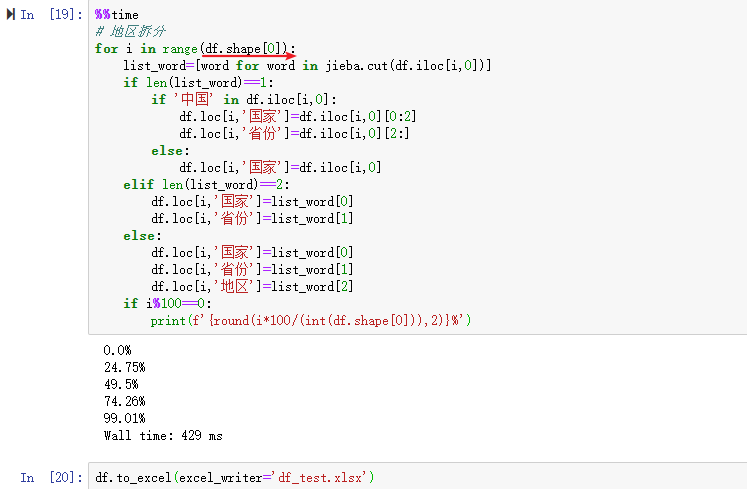
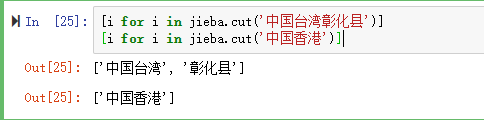
??дйХмвЛБщДњТыЃЌВЂЧвАбНсЙћБЃДцЕНБОЕиЮФМўЁЎdf_test.xlsxЁЏЁЃБугкВщПДjiebaЕкШ§ЗНЗжДЪПтЖдБОДЮЪ§ОнВ№ЗжЪЧВЛЪЧЯывЊЕФНсЙћЁЃ
ЙњМвЃК
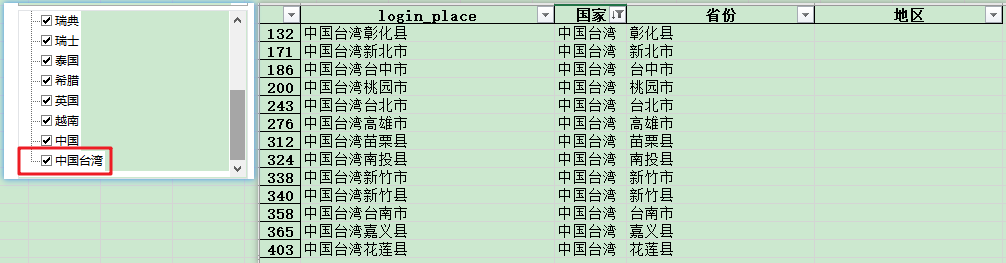
ЁЎЙњМвЁЏетвЛСаЃЌжаЙњЬЈЭхУЛгаВ№ЗжГіРДЁЃ
ДњТыЪдСЫвЛЯТЃЌЗЂЯжЁЎжаЙњЬЈЭхЁЏШЗЪЕВ№ЗжВЛСЫЁЃжЄЪЕСЫЬЈЭхШЗЪЕжаЙњВЛПЩШБЪЇЕФвЛВПЗжЁЃ
ЪЁЗнЃК

??ЁЎЪЁЗнЁЏетвЛСаВ№ЗжЕФИќМгдуИтЁЃ
змНсЃКзмЪ§ОнМЏдЫааЪБМфГЄЃЌЧаДЪВЛзМШЗЁЃашвЊгХЛЏВ№ЗжЗНАИЃЁ
Ш§ЁЂгХЛЏЗНАИ
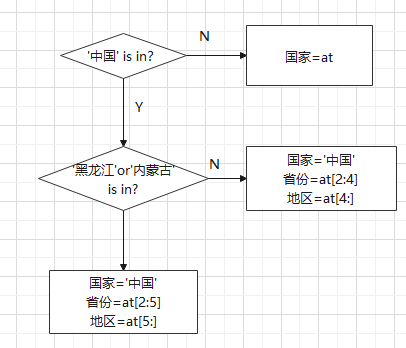
??дкЩЯУцВщПДExcelЮФМўЪБКђЗЂЯжЁЎlogin_placeЁЏзжЖЮЕФЪ§ОнгавдЯТЬиЕуЃК
- ећИіЪ§ОнМЏЗжРрСНРрЃКЁЎжаЙњЁЏКЭЭтЙњЃЛ
- жаЙњЕФЪЁЗнДѓЖрЪЧСНИізжЃЌГ§СЫЁЎКкСњНЁЏКЭЁЎФкУЩЙХЁЏЃЛ
- ЭтЙњЕФЃЌжЛгаЙњМвМЧТМЁЃ
гХЛЏЗНАИЃК
- ЖдЙњМвХаЖЯЃЌаЮГЩЗжжЇЃКжаЙњКЭЭтЙњЃЛ
- ЖдгкжаЙњЃЌдйХаЖЯЪЁЗнЪЧВЛЪЧЁЎКкСњНЁЏКЭЁЎФкУЩЙХЁЏЁЃ
- ВЛЪЧЃКПЩвджБНгЧаЗж[2:4]ЃЌЬсШЁЪЁЗнЁЃ[4:]ЃЌЬсШЁЕиЧјЃЛ
- ЪЧЃК[2:5]ЬсШЁЪЁЗнЁЃ[5:]ЬсШЁЕиЧј
%%time
# ЕиЧјВ№Зж
for i in range(df.shape[0]):
if 'жаЙњ' in df.iloc[i,0] :
df.loc[i,'ЙњМв'] = 'жаЙњ'
if ('ФкУЩЙХ' in df.iloc[i,0]) or ('КкСњН' in df.iloc[i,0]):
# print(df.iloc[i,0])
df.loc[i,'ЪЁЗн'] = df.iloc[i,0][2:5]
if len(df.iloc[i,0]) > 5:
df.loc[i,'ЕиЧј'] = df.iloc[i,0][5:]
else:
df.loc[i,'ЪЁЗн'] = df.iloc[i,0][2:4]
df.loc[i,'ЕиЧј'] = df.iloc[i,0][4:]
else:
list_word = [word for word in jieba.cut(df.iloc[i,0])]
if len(list_word) == 1:
df.loc[i,'ЙњМв'] = df.iloc[i,0][0:2]
df.loc[i,'ЪЁЗн'] = df.iloc[i,0][2:]
else:
df.loc[i,'ЙњМв'] = list_word[0]
df.loc[i,'ЪЁЗн'] = list_word[1]
if i%100==0:
print(f'{round(i*100/(int(df.shape[0])),2)}%')
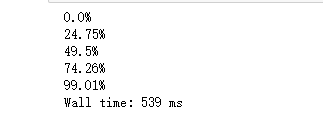
?БЃДцExcelЮФМўЃЌдйДЮВщПДВ№ЗжЧщПіЁЃОЙ§ШЅжиКѓЕФВтЪдМЏВ№ЗжЗћКЯЯывЊЕФНсЙћЁЃ
?дЫааЮДШЅжидДЪ§ОнМЏНсЙћЃК

bk