数据结构课程实践
题目一:学生学籍管理系统
需求分析
- 学生信息录入,信息包括学号、姓名、专业、四门课成绩、总分、名次;
- 系统可对学生信息浏览、增加、删除和修改;
- 按学生成绩确定名次及信息输出,双向冒泡排序、希尔排序、快速排序、堆排序。
- 要求可对学生信息查询,根据学号或姓名进行查找;
- 信息修改仅可修改四门课成绩;
- 文件存取学生信息。
功能块
- 新增学生信息(包括学号、姓名、专业、4门课成绩……)
- 浏览学生信息(对学生排序后信息进行浏览)
- 删除学生信息(删除指定学生的信息,可给用户选择检索指定项)
- 查找学生信息(查找符合条件的某条记录)
- 保存学生信息(保存学生成绩档案信息到文本文件)
- 加载学生信息(登录系统后将磁盘文件中保存的学生成绩信息读取到内存中)
整体分析
类的定义
| 学生类 | 功能类 | 文档交互类 | 主类 |
|---|
| 学号 | 新增 | 写入 | 方法的调用 |
| 姓名 | 浏览 | 写出 | |
| 专业 | 删除 | | |
| 语文 | 修改 | | |
| 数学 | 查找 | | |
| 英语 | 保存 | | |
| 专业课 | 加载 | | |
| 总分 | | | |
| 名次 | | | |
算法分析
- 双向冒泡排序
与冒泡排序的不同处在于排序时是以双向在序列中进行排序,先想左排序再向右排(或者相反)比如大的向右小的向左这样当两个标志left>=right时整个就是正确的顺序了。
算法实例:
排序前:45 19 77 81 13 28 18 1977 11
往右排序:19 45 77 13 28 18 19 7711 [81]
向左排序:[11] 19 45 77 13 28 1819 77 [81]
往右排序:[11] 19 45 13 28 18 19 [77 77 81]
向左排序:[11 13] 19 45 18 28 19 [77 77 81]
往右排序:[11 13] 19 18 28 19 [45 77 77 81]
向左排序:[11 13 18] 19 19 28 [45 77 77 81]
往右排序:[11 13 18] 19 19 [28 45 77 77 81]
向左排序:[11 13 18 19 19] [28 45 77 77 81]
2 希尔排序
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为dl的倍数的记录放在同一个组中。先在各组内进行直接插人排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
算法示例: 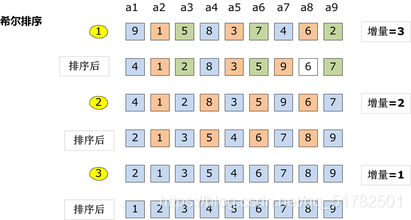
3 快速排序
首先找一个基准值然后以这个基准值分别分为两个区左边都小于这个基准值右边都大于这个基准值。然后用两个哨兵对这两边进行交换直到检索完毕。开始换基准。换基准值变又出现2个区一直循环下去直到基准值”用尽“值如下图示:
示例:
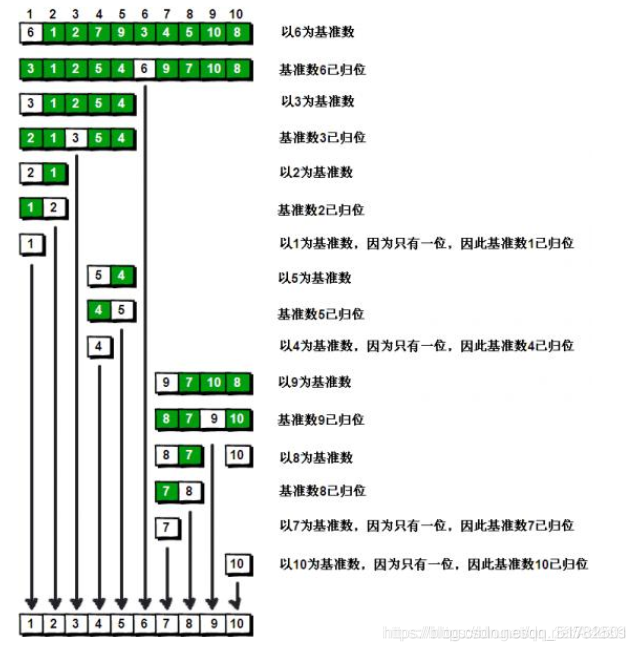
4 堆排序
将数据看成一个完全二叉树然后进行排序通过键堆然后会使最大值置于二叉树的顶部然后与尾部进行交换在进行建堆交换…直至全部排序。
预习总结
看到这个题便有了思路但对一些具体模块还是较为模糊,比如文档的写入写出没接触过,希尔排序以及双向冒泡排序较为陌生。