@一贤爱吃土豆
微服务架构样式
1.SpringCloud介绍
1.1:微服务架构
https://martinfowler.com/articles/microservices.html
- 但通在其常而言,微服务架构是一种架构模式或者说是一种架构风格,它提倡将单一应用程序划分成一组小的服务,每个服务运行独立的自己的进程中,服务之间互相协调、互相配合,为用户提供最终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于 HTTP 的 RESTful API ) 。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。
另外,应尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务。可以使用不同的语言来编写服务,也可以使用不同的数据存储。 - 简而言之,微服务架构样式 https://martinfowler.com/articles/microservices.html#footnote-etymology是一种将单个应用程序开发为一组小服务的方法,每个小服务都在自己的进程中运行并与轻量级机制(通常是HTTP资源API)进行通信。这些服务围绕业务功能构建,并且可以由全自动部署机制独立部署。这些服务的集中管理几乎没有,它可以用不同的编程语言编写并使用不同的数据存储技术。
1、 微服务架构只是一个样式,一个风格。
2、 将一个完整的项目,拆分成多个模块去分别开发。
3、 每一个模块都是单独的运行在自己的容器中。
4、 每一个模块都是需要相互通讯的。 Http,RPC,MQ。
5、 每一个模块之间是没有依赖关系的,单独的部署。
6、 可以使用多种语言去开发不同的模块。
7、 使用MySQL数据库,Redis,ES去存储数据,也可以使用多个MySQL数据库。 - 总结:将复杂臃肿的单体应用进行细粒度的划分,每个拆分出来的服务各自打包部署。
1.2:SpringCloud介绍
- SpringCloud是微服务架构落地的一套技术栈。
- SpringCloud中的大多数技术都是基于Netflix公司的技术进行二次研发。
- SpringCloud的中文社区网站:http://springcloud.cn/
- SpringCloud的中文网:http://springcloud.cc/
- 八个技术点:
- Eureka - 服务的注册与发现
- Robbin - 服务之间的负载均衡
- Feign - 服务之间的通讯
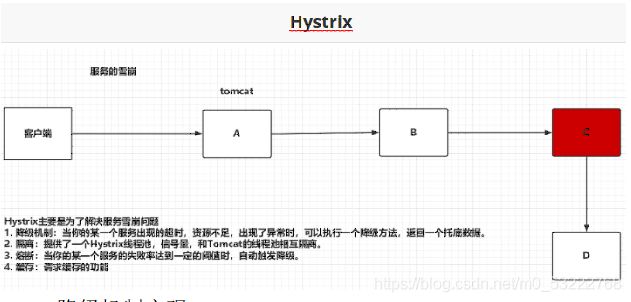
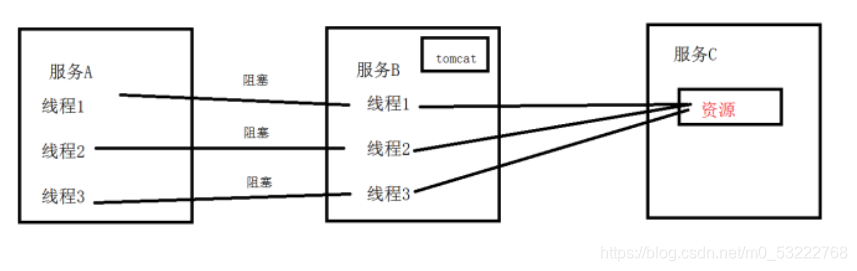
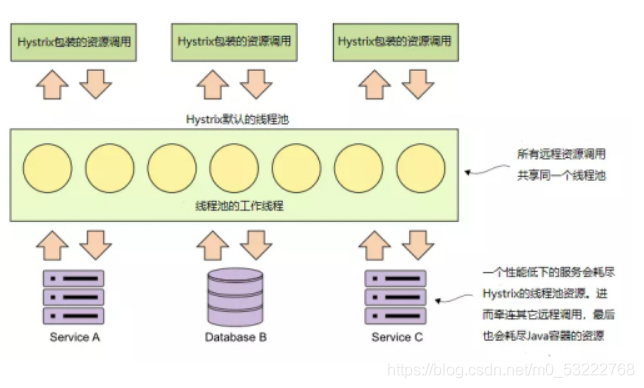
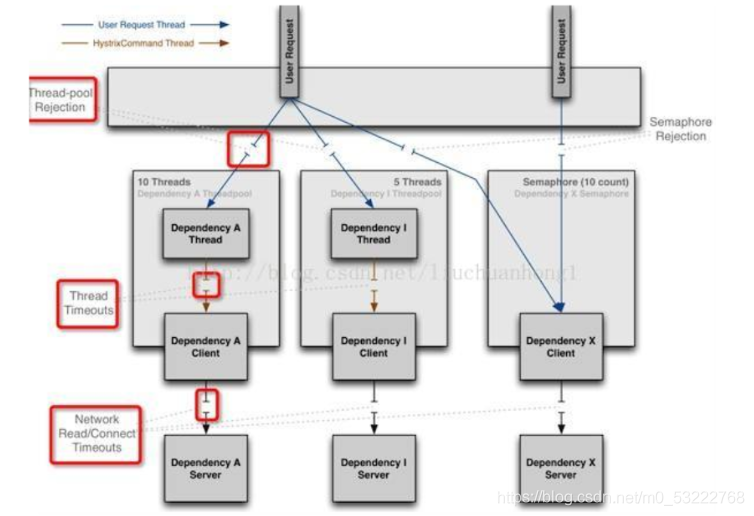
- Hystrix - 服务的线程隔离以及断路器
- Zuul - 服务网关
- Stream - 实现MQ的使用
- Config - 动态配置
- Sleuth - 服务追踪
2.服务的注册与发现-Eureka(重点)
2.1:引言
-
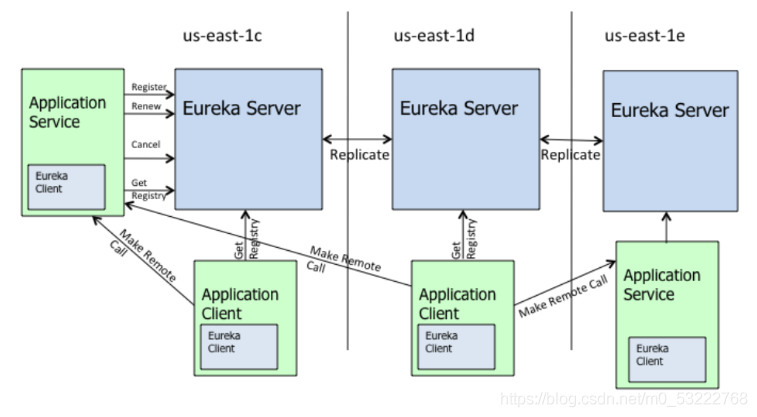
Eureka 是 Netflix 出品的用于实现服务注册和发现的工具。 Spring Cloud 集成了 Eureka,并提供了开箱即用的支持。其中, Eureka 又可细分为 Eureka Server 和 Eureka Client。
-
上图是基于集群配置的eureka;
-
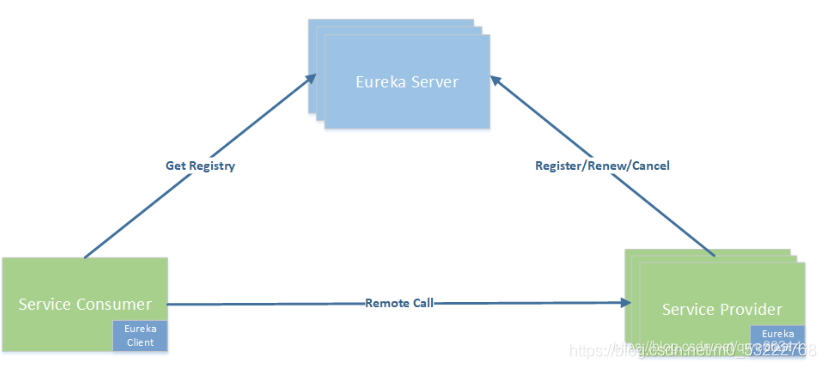
Eureka原理
-
服务启动后向Eureka注册,Eureka Server会将注册信息向其他Eureka Server进行同步,当服务消费者要调用服务提供者,则向服务注册中心获取服务提供者地址,然后会将服务提供者地址缓存在本地,下次再调用时,则直接从本地缓存中取,完成一次调用。
-
当服务注册中心Eureka Server检测到服务提供者因为宕机、网络原因不可用时,则在服务注册中心将服务置为DOWN状态,并把当前服务提供者状态向订阅者发布,订阅过的服务消费者更新本地缓存。
-
服务提供者在启动后,周期性(默认30秒)向Eureka Server发送心跳,证明当前服务是可用状态。Eureka Server在一定的时间(默认90秒)未收到客户端的心跳,则认为服务宕机,注销该实例。
2.2.1:创建EurekaServer服务端
- Eureka就是帮助我们维护所有服务的信息,以便服务之间的相互调用。
2.2:Eureka的快速入门
- 创建一个父工程,并且在父工程中指定SpringCloud的版本,并且将packaing修改为(三种pom jar war中的 )pom。
<packaging>pom</packaging>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Greenwich.SR5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
- 创建eureka的server,创建SpringBoot工程,并且导入依赖,在启动类中添加注解,编写yml文件
- 导入依赖
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class,args);
}
}
server:
port: 8761 # 端口号
eureka:
instance:
hostname: localhost # localhost
client:
# 当前的eureka服务是单机版的
registerWithEureka: false
fetchRegistry: false
serviceUrl:
defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
2.2.2:创建EurekaClient客户端
- 创建Maven工程,修改为SpringBoot
- 导入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
@SpringBootApplication
@EnableEurekaClient
public class CustomerApplication {
public static void main(String[] args) {
SpringApplication.run(CustomerApplication.class,args);
}
}
# 指定Eureka服务地址
eureka:
client:
service-url:
defaultZone: http://localhost:8761/eureka
#指定服务的名称
spring:
application:
name: CUSTOMER

2.2.3:测试Eureka
- 创建了一个Search搜索模块,并且注册到Eureka
- 使用到EurekaClient的对象去获取服务信息
@Autowired
private EurekaClient eurekaClient;
@GetMapping("/customer")
public String customer(){
//1. 通过eurekaClient获取到SEARCH服务的信息
InstanceInfo info = eurekaClient.getNextServerFromEureka("SEARCH", false);
//2. 获取到访问的地址
String url = info.getHomePageUrl();
System.out.println(url);//http://localhost:8082/search
//3. 通过restTemplate访问
String result = restTemplate.getForObject(url + "/search", String.class);
//4. 返回
return result;
}
2.3:Eureka的安全性
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
- 编写配置类,要让spring扫描到这个类
- 默认情况下,当spring security要求用户向应用程序发送请求时,都必须携带一个有效的csrf令牌,而 Eureka客户端通常不会拥有有效的跨站点请求(CSRF)令牌,此时Eureka Server端应该对eureka的请求路径放行。
- CSRF(Cross-site request forgery)是指跨站请求伪造,是web常见的攻击之一,从Spring Security 4.0开始,默认情况下security会启用CSRF保护,以防止CSRF攻击应用程序。
@EnableWebSecurity
public class WebSecurityConfig extends WebSecurityConfigurerAdapter {
@Override
protected void configure(HttpSecurity http) throws Exception {
// 忽略掉/eureka/**
http.csrf().ignoringAntMatchers("/eureka/**");
super.configure(http);
}
}
# 指定用户名和密码
spring:
security:
user:
name: root
password: root
- 其他服务想注册到Eureka上需要添加用户名和密码
eureka:
client:
service-url:
defaultZone: http://用户名:密码@localhost:8761/eureka
2.4:Eureka的高可用
- 如果程序的正在运行,突然Eureka宕机了。
- 如果调用方访问过一次被调用方了,Eureka的宕机不会影响到功能。
- 如果调用方没有访问过被调用方,Eureka的宕机就会造成当前功能不可用。
- 这里将eureka集群3台为例,将单机版的eureka拷贝3份后,配置分别如下
- eureka8001
server:
port: 8001
spring:
application:
name: eureka-server # 服务器域名
eureka:
client:
fetch-registry: false
register-with-eureka: false
service-url:
#集群的情况下,服务端之间要互相注册,指向对方,多个地址用逗号隔开
defaultZone: http://eureka8002.com:8002/eureka,http://eureka8003.com:8003/eureka
instance:
instance-id: eureka8001.com
server:
port: 8002
spring:
application:
name: eureka-server2
eureka:
client:
fetch-registry: false
register-with-eureka: false
service-url:
defaultZone: http://eureka8001.com:8001/eureka,http://eureka8003.com:8003/eureka
instance:
instance-id: eureka8002.com
server:
port: 8003
spring:
application:
name: eureka-server3
eureka:
client:
fetch-registry: false
register-with-eureka: false
service-url:
defaultZone: http://eureka8001.com:8001/eureka,http://eureka8002.com:8002/eureka
instance:
instance-id: eureka8003.com
集群后三台Eureka服务的IP都不一样,所以为了方便在本地测试,可以在hosts文件中做域名映射,把三台服务的ip都映射成127.0.0.1。hosts文件路劲如下:
C:\Windows\System32\drivers\etc
127.0.0.1 eureka8001.com
127.0.0.1 eureka8002.com
127.0.0.1 eureka8003.com
发布的每一个服务都应该注册到所有的Eureka中,所以每一个服务中都要写三个Eureka服务地址。
server:
port: 8082
spring:
application:
name: provider-server
eureka:
client:
service-url:
# 这里写三台Eureka地址
defaultZone: http://eureka8001.com:8001/eureka,http://eureka8002.com:8002/eureka,http://eureka8003.com:8003/eureka
搭建Eureka高可用准备多台Eureka采用了复制的方式,删除iml和target文件,并且修改pom.xml中的项目名称,再给父工程添加一个module,让服务注册到多台Eureka
eureka:
client:
service-url:
defaultZone: http://root:root@localhost:8761/eureka,http://root:root@localhost:8762/eureka
让多台Eureka之间相互通讯
eureka:
client:
registerWithEureka: true # 注册到Eureka上
fetchRegistry: true # 从Eureka拉取信息
serviceUrl:
defaultZone: http://root:root@localhost:8762/eureka/
2.5:Eureka的细节
- EurekaClient启动时,将自己的信息注册到EurekaServer上,EurekaSever就会存储上EurekaClient的注册信息。
*当EurekaClient调用服务时,本地没有注册信息的缓存时,去EurekaServer中去获取注册信息。 - EurekaClient会通过心跳的方式去和EurekaServer进行连接。(默认30sEurekaClient会发送一次心跳请求,如果超过了90s还没有发送心跳信息的话,EurekaServer就认为你宕机了,将当前EurekaClient从注册表中移除)
eureka:
instance:
lease-renewal-interval-in-seconds: 30 #心跳的间隔
lease-expiration-duration-in-seconds: 90 # 多久没发送,就认为你宕机了
- EurekaClient会每隔30s去EurekaServer中去更新本地的注册表
eureka:
client:
registry-fetch-interval-seconds: 30 # 每隔多久去拉取服务注册信息
- Eureka的自我保护机制,统计15分钟内,如果一个服务的心跳发送比例低于85%,EurekaServer就会开启自我保护机制
- 不会从EurekaServer中去移除长时间没有收到心跳的服务。
- EurekaServer还是可以正常提供服务的。
- 网络比较稳定时,EurekaServer才会开始将自己的信息被其他节点同步过去
eureka:
server:
enable-self-preservation: true # 开启自我保护机制
instance:
lease-expiration-duration-in-seconds: 2 #每间隔1s,向服务端发送一次心跳,证明自己依然”存活“
lease-renewal-interval-in-seconds: 1 #告诉服务端,如果我2s之内没有给你发心跳,就代表我“死”了,将我踢出掉
- CAP定理,C - 一致性,A-可用性,P-分区容错性,这三个特性在分布式环境下,只能满足2个,而且分区容错性(分区容错性是指系统能够容忍节点之间的网络通信的故障)在分布式环境下,是必须要满足的,只能在A和C之间进行权衡。
(一)一致性(C)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
(二)可用性(A)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
(三)分区容错性(P)
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
如果选择CP,保证了一致性,可能会造成你系统在一定时间内是不可用的,如果你同步数据的时间比较长,造成的损失大。
Eureka就是一个AP的效果,高可用的集群,Eureka集群是无中心,Eureka即便宕机几个也不会影响系统的使用,不需要重新的去推举一个master,也会导致一定时间内数据是不一致。
总结:
以上可以知道分区容错性(P)主要代表网络波动产生的错误,这是不可避免的,且这个三个模式不可兼得,所以目前就只有两种模式:CP和AP模式。
其中CP表示遵循一致性原则,但不能保证高可用性,其中zookeeper作为注册中心就是采用CP模式,因为zookeeper有过半节点不可以的话整个zookeeper将不可用。
AP表示遵循于可用性原则,例如Eureka作为注册中心用的是AP模式,因为其为去中心化,采用你中有我我中有你的相互注册方式,只要集群中有一个节点可以使用,整个eureka服务就是可用的,但可能会出现短暂的数据不一致问题。
2.6:Eureka数据同步
-
Eureka Server 集群相互之间通过 Replicate 来同步数据,相互之间不区分主节点和从节点,所有的节点都是平等的。在这种架构中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。
-
如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点。当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会进行节点间复制,将请求复制到其它 Eureka Server 当前所知的所有节点中。
-
另外 Eureka Server 的同步遵循着一个非常简单的原则:只要有一条边将节点连接,就可以进行信息传播与同步。所以,如果存在多个节点,只需要将节点之间两两连接起来形成通路,那么其它注册中心都可以共享信息。每个 Eureka Server 同时也是 Eureka Client,多个 Eureka Server 之间通过 P2P 的方式完成服务注册表的同步。
-
Eureka Server 集群之间的状态是采用异步方式同步的,所以不保证节点间的状态一定是一致的,不过基本能保证最终状态是一致的。
3.服务间的负载均衡-Ribbon(重点)
3.1:引言
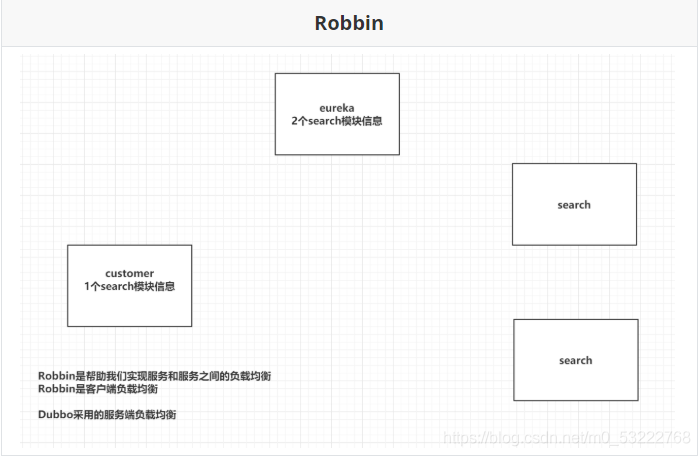
- Robbin是帮助我们实现服务和服务负载均衡,Robbin属于客户端负载均衡
- 客户端负载均衡:customer客户模块,将2个Search模块信息全部拉取到本地的缓存,在customer中自己做一个负载均衡的策略,选中某一个服务。
- 服务端负载均衡:在注册中心中,直接根据你指定的负载均衡策略,帮你选中一个指定的服务信息,并返回。
3.2:Ribbon的快速入门
- 启动两个search模块 vm options设置值为-Dserver.port=8082
- 在customer导入robbin依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-ribbon</artifactId>
</dependency>
@Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}
@GetMapping("/customer")
public String customer(){
String result = restTemplate.getForObject("http://SEARCH/search", String.class);
//4. 返回
return result;
}
3.3:Ribbon配置负载均衡策略
- 负载均衡策略
- Ribbon支持的负载均衡策略
- RandomRule:随机策略 随机选择server
- RoundRobbinRule:轮询策略 按照顺序选择server(ribbon默认策略)
- WeightedResponseTimeRule:默认会采用轮询的策略,后续会根据服务的响应时间,自动给你分配权重
- BestAvailableRule:根据被调用方并发数最小的去分配 最低并发策略 逐个考察server,如果server断路器打开,则忽略,再选择其中并发链接最低的server
- RetryRule 重试策略 在一个配置时间段内,当选择server不成功,则一直尝试选择一个可用的server
- AvailabilityFilteringRule 可用过滤策略 过滤掉一直失败并被标记为circuit tripped的server,过滤掉那些高并发链接的server(active connections超过配置的阈值)
- ResponseTimeWeightedRule 响应时间加权重策略 根据server的响应时间分配权重,响应时间越长,权重越低,被选择到的概率也就越低。响应时间越短,权重越高,被选中的概率越高,这个策略很贴切,综合了各种因素,比如:网络,磁盘,io等,都直接影响响应时间
- ZoneAvoidanceRule 区域权重策略 综合判断server所在区域的性能,和server的可用性,轮询选择server并且判断一个AWS Zone的运行性能是否可用,剔除不可用的Zone中的所有server
- 采用注解的形式,所有的服务都采用这个负载均衡策略
@Bean
public IRule robbinRule(){
return new RandomRule();
}
# 指定具体服务的负载均衡策略
SEARCH: # 编写服务名称
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.WeightedResponseTimeRule # 具体负载均衡使用的类
4.服务间的调用-Feign(重点)
4.1:引言
- Feign可以帮助我们实现面向接口编程,就直接调用其他的服务,简化开发。
4.2:Feign的快速入门
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
@EnableFeignClients
@FeignClient("SEARCH") // 指定服务名称
public interface SearchClient {
// value -> 目标服务的请求路径,method -> 映射请求方式
@RequestMapping(value = "/search",method = RequestMethod.GET)
String search();
}
@Autowired
private SearchClient searchClient;
@GetMapping("/customer")
public String customer(){
String result = searchClient.search();
return result;
}
SEARCH:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule
4.3:Feign的传递参数方式
- 注意事项
- 如果你传递的参数,比较复杂时,默认会采用POST的请求方式。
- 传递单个参数时,推荐使用@PathVariable,如果传递的单个参数比较多,这里也可以采用@RequestParam,不要省略value属性
- 传递对象信息时,统一采用json的方式,添加@RequestBody
- Client接口必须采用@RequestMapping
- 在provider模块下准备三个接口
@RequestMapping(value = "/getUserById/{id}")
public String getUserById(@PathVariable Integer id){
System.out.println("id = [" + id + "]");
return "getUserById:"+id;
}
@RequestMapping(value = "/login")
public String login(String username,String password){
System.out.println("username = [" + username + "], password = [" + password + "]");
return "login:username"+username+":password:"+password;
}
@RequestMapping(value = "/addUserFrom")
public String addUserFrom(@RequestBody User user){ // 表单转json的方式
System.out.println(user);
return "addUserFrom:"+user;
}
@RequestMapping(value = "/addUserJSON")
public String addUserJSON(@RequestBody User user){
System.out.println(user);
return "addUserJSON:"+user;
}
@Autowired
private IProviderService providerService;
@RequestMapping(value = "/getUserById/{id}")
public String getUserById(@PathVariable Integer id){
System.out.println("id = [" + id + "]");
return "consuemr:"+providerService.getUserById(id);
}
@RequestMapping(value = "/login")
public String login(String username,String password){
return "consuemr:"+providerService.login(username,password);
}
@RequestMapping(value = "/addUserFrom")
public String addUserFrom(User user){
System.out.println("user = [" + user + "]");
return "consuemr:"+providerService.addUserFrom(user);
}
@RequestMapping(value = "/addUserJSON")
public String addUserJSON(@RequestBody User user){
System.out.println(user);
return "consuemr:"+providerService.addUserJSON(user);
}
@FeignClient(value = "PROVIDER")
@RequestMapping(value = "/provider")
public interface IProviderService {
@RequestMapping(value = "/hello")
public String hello();
@RequestMapping(value = "/getUserById/{id}") // 这里必须要写属性名称,它不想springmvc那样会自动的把形参作为参数值
public String getUserById(@PathVariable("id") Integer id);
@RequestMapping(value = "/login") // 这里必须要写属性名称,它不想springmvc那样会自动的把形参作为参数值
public String login(@RequestParam("username") String username, @RequestParam("password") String password);
// feign不支持直接传递对象,可以通过这样方式转成json然后传递给服务提供者,服务提供者收到的json字符串
// feign[对象]--》对象转成json--》provider[对象]
@RequestMapping(value = "/addUserFrom",consumes = "application/json")
public String addUserFrom(@RequestBody User user);
@RequestMapping(value = "/addUserJSON")
public String addUserJSON(@RequestBody User user);
}
4.4:Feign的Fallback
- Fallback可以帮助我们在使用Feign去调用另外一个服务时,如果出现了问题,走服务降级,返回一个错误数据,避免功能因为一个服务出现问题,全部失效。
4.4.1:FallBack方式
@Component
public class ProviderServiceImpl implements IProviderService {
@Override
public String hello() {
return "服务出现故障,这里是默认值";
}
@Override
public String getUserById(Integer id) {
return "id";
}
@Override
public String login(String username, String password) {
return "login";
}
@Override
public String addUserFrom(User user) {
return "addUser";
}
@Override
public String addUserJSON(User user) {
return "addUserJSON";
}
}
@FeignClient(value = "PROVIDER",fallback = ProviderServiceImpl.class)
//@RequestMapping(value = "/provider") //开启了hystrix后这个路径要写到下面的方法上面
public interface IProviderService {
@RequestMapping(value = "/provider/hello")
public String hello();
}
# feign和hystrix组件整合
feign:
hystrix:
enabled: true
4.4.2:FallBackFactory方式
- 调用方无法知道具体的错误信息是什么,通过FallBackFactory的方式去实现这个功能
- FallBackFactory基于Fallback
- 创建一个POJO类,实现FallBackFactory
<Client>
@Component
public class ProviderFactory implements FallbackFactory<IProviderService> {
@Autowired
private ProviderServiceImpl providerService;
@Override
public IProviderService create(Throwable throwable) {
throwable.printStackTrace();; // 打印异常信息
return providerService; // 返回自定义的实现方法
}
}