вЛЁЂЧАбд
ЛњЦїбЇЯАШ§ДѓМўЃКnumpyЃЌ pandasЃЌ matplotlib
NumpyЃЈNumerical PythonЃЉЪЧвЛИіПЊдДЕФPythonПЦбЇМЦЫуПтЃЌгУгкПьЫйДІРэШЮвтЮЌЖШЕФЪ§зщЁЃ
NumpyжЇГжГЃМћЕФЪ§зщКЭОиеѓВйзїЁЃЖдгкЭЌбљЕФЪ§жЕМЦЫуШЮЮёЃЌЪЙгУNumpyБШжБНгЪЙгУPythonвЊМђНрЕФЖрЁЃ
NumpyЪЙгУndarrayЖдЯѓРДДІРэЖрЮЌЪ§зщЃЌИУЖдЯѓЪЧвЛИіПьЫйЖјСщЛюЕФДѓЪ§ОнШнЦїЁЃ
NumPyЬсЙЉСЫвЛИіNЮЌЪ§зщРраЭndarray
import numpy as np
score = np.array(
[[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
score
array([[80, 89, 86, 67, 79],
[78, 97, 89, 67, 81],
[90, 94, 78, 67, 74],
[91, 91, 90, 67, 69],
[76, 87, 75, 67, 86],
[70, 79, 84, 67, 84],
[94, 92, 93, 67, 64],
[86, 85, 83, 67, 80]])
NumpyзЈУХеыЖдndarrayЕФВйзїКЭдЫЫуНјааСЫЩшМЦЃЌЫљвдЪ§зщЕФДцДЂаЇТЪКЭЪфШыЪфГіадФмдЖгХгкPythonжаЕФЧЖЬзСаБэЃЌЪ§зщдНДѓЃЌNumpyЕФгХЪЦОЭдНУїЯдЁЃ
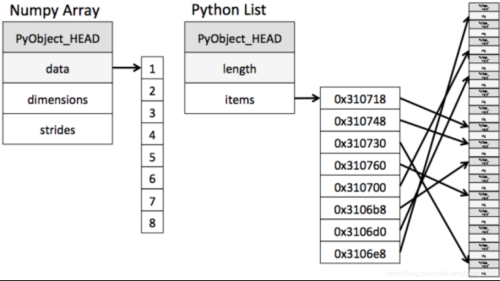
ДгЭМжаЮвУЧПЩвдПДГіndarrayдкДцДЂЪ§ОнЕФЪБКђЃЌЪ§ОнгыЪ§ОнЕФЕижЗЖМЪЧСЌајЕФЃЌетбљОЭИјЪЙЕУХњСПВйзїЪ§зщдЊЫиЪБЫйЖШИќПьЁЃ
list ЈC ЗжРыЪНДцДЂ,ДцДЂФкШнЖрбљЛЏ
ndarray ЈC вЛЬхЪНДцДЂ,ДцДЂРраЭБиаывЛбљ
ndarrayжЇГжВЂааЛЏдЫЫуЃЈЯђСПЛЏдЫЫуЃЉ
ndarrayЕзВуЪЧгУCгябдаДЕФ,аЇТЪИќИп,ЪЭЗХСЫGIL
ЖўЁЂЛљБОВйзї
# ЩњГЩ0КЭ1ЕФЪ§зщ
ones = np.ones([4,8])
ones
array([[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.]])
# ЩњГЩЕШМфИєЕФЪ§зщ
np.linspace(0, 100, 11)
array([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90.,
100.])
#ДДНЈЕШВюЪ§зщ ЁЊ жИЖЈВНГЄ
np.arange(10, 50, 2)
array([10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48])
Ш§ЁЂе§ЬЋЗжВМ
- randКЏЪ§ИљОнИјЖЈЮЌЖШЩњГЩ[0,1)жЎМфЕФЪ§ОнЃЌАќКЌ0ЃЌВЛАќКЌ1
array([[ 0.02173903, 0.44376568],
[ 0.25309942, 0.85259262],
[ 0.56465709, 0.95135013],
[ 0.14145746, 0.55389458]])
- randnКЏЪ§ЗЕЛивЛИіЛђвЛзщбљБОЃЌОпгаБъзМе§ЬЌЗжВМ
array([[ 0.27795239, -2.57882503, 0.3817649 , 1.42367345],
[-1.16724625, -0.22408299, 0.63006614, -0.41714538]])
- randintЗЕЛиЫцЛњећЪ§ЃЌЗЖЮЇЧјМфЮЊ[low,highЃЉЃЌАќКЌlowЃЌВЛАќКЌhigh
np.random.randint(1,5) # ЗЕЛи1Иі[1,5)ЪБМфЕФЫцЛњећЪ§
4
- ЩњГЩОљдШЗжВМЕФЫцЛњЪ§ЃЌОйР§1ЃКЩњГЩОљжЕЮЊ1.75ЃЌБъзМВюЮЊ1ЕФе§ЬЌЗжВМЪ§ОнЃЌ100000000Иі
x1 = np.random.normal(1.75, 1, 100000000)
array([2.90646763, 1.46737886, 2.21799024, Ё, 1.56047411, 1.87969135, 0.9028096 ])
# ЩњГЩОљдШЗжВМЕФЫцЛњЪ§
x2 = np.random.uniform(-1, 1, 100000000)
array([ 0.22411206, 0.31414671, 0.85655613, Ё, -0.92972446, 0.95985223, 0.23197723])
ЫФЁЂЪ§зщЕФЫїв§ЁЂЧаЦЌ
# Ш§ЮЌ
a1 = np.array([ [[1,2,3],[4,5,6]], [[12,3,34],[5,6,7]]])
# ЗЕЛиНсЙћ
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[12, 3, 34],
[ 5, 6, 7]]])
# Ыїв§ЁЂЧаЦЌ
a1[0, 0, 1] # ЪфГі: 2
ЮхЁЂаЮзДаоИФ
stock_change.reshape([5, 4]) #5*4
stock_change.reshape([-1,10]) #2*10ЃЌ-1: БэЪОЭЈЙ§Д§МЦЫу
СљЁЂзЊжУ
ЦпЁЂРраЭзЊЛЛ
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[12, 3, 34], [5, 6, 7]]])
arr.tostring()
АЫЁЂЪ§зщЕФШЅжи
temp = np.array([[1, 2, 3, 4],[3, 4, 5, 6]])
>>> np.unique(temp)
array([1, 2, 3, 4, 5, 6])
ТпМдЫЫу
жБНгНјааДѓгк,аЁгкЕФХаЖЯЃКtest_score > 60
КЯЪЪжЎКѓ,ПЩвджБНгНјааИГжЕЃКtest_score[test_score > 60] = 1
ЭЈгУХаЖЯКЏЪ§
np.all() np.all(score[0:2, :] > 60)
np.any() np.any(score[0:2, :] > 80)
ЭГМЦдЫЫу
np.max()
np.min()
np.median()
np.mean()
np.std()
np.var()
np.argmax(axis=) ЁЊ зюДѓдЊЫиЖдгІЕФЯТБъ
np.argmin(axis=) ЁЊ зюаЁдЊЫиЖдгІЕФЯТБъ
ОХЁЂЙуВЅЛњжЦ
- Ъ§зщдЫЫу,ТњзуЙуВЅЛњжЦ,ОЭOK
1.ЮЌЖШЯрЕШ
2.shape(ЦфжаЖдгІЕФЕиЗНЮЊ1,вВЪЧПЩвдЕФ)
arr1 = np.array([[0],[1],[2],[3]])
arr1.shape
# (4, 1)
arr2 = np.array([1,2,3])
arr2.shape
# (3,)
arr1+arr2
# НсЙћЪЧЃК
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])
js