上一篇介绍了使用python模拟登陆网站,但是登陆的网站都是直接输入账号及密码进行登陆,现在很多网站为了加强用户安全性和提高反爬虫机制都会有包括字符、图片、手机验证等等各式各样的验证码。图片验证码就是其中一种,而且识别难度越来越大,人为都比较难识别。本篇我们简单介绍一下使用python登陆带弱图片验证码的网站。
图片验证码
一般都通过加干扰线、粘连或扭曲等方式来增加强度。

登陆
我们选择一个政务网站(图片验证码的强度较低)。
点击个人用户登录
访问网站首页以后我们发现需要先点击个人用户登陆,且元素没有name、id登标识不好获取,所以我们直接执行里面的onClick方法


# 新建selenium浏览器对象,后面是geckodriver.exe下载后本地路径
browser = webdriver.Firefox()
url = 'http://xxx.gov.cn/'
# 浏览器访问登录页面
browser.get(url)
# 等待3s用于加载脚本文件
browser.implicitly_wait(3)
# 点击个人登陆
browser.execute_script('showpersonlogin();')
获取图片验证码
我们可以通过save_screenshot截图,然后找到验证码元素,获取元素位置然后在截图的基础上裁剪出验证码。
# 找到图片验证码元素
img = browser.find_element_by_id('imgCode')
location = img.location
size = img.size
left = location['x']
top = location['y']
right = left + size['width']
bottom = top + size['height']
# 按照验证码的长宽,切割验证码
image_obj = loginPage.crop((left, top, right, bottom))
image_obj.save('code.png')
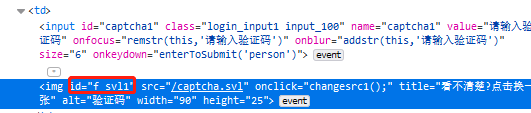

识别并登陆
由于该网站的验证码比较简单可以直接用pytesseract模块的image_to_string方法
orcCode = pytesseract.image_to_string('code.png')
# 输入用户名
username = browser.find_element_by_id('personaccount')
username.send_keys('账号')
# 输入密码
password = browser.find_element_by_id('personpassword')
password.send_keys('密码')
# 输入验证码
code = browser.find_element_by_id('captcha1')
code.send_keys(orcCode)
# 执行登录
browser.execute_script('personlogin();')
# 关闭浏览器
# browser.quit()
识别较复杂验证码算法
网上找的算法,先将图片转为灰度图,然后进行二值化处理(将图像上的像素点的灰度值设置为0或255。如灰度大于等于阈值的像素,用255表示。否则为0。),再去噪(8邻域降噪,判断8个邻域的黑色数量个数)。
ocrImage.py:
import pytesseract
from PIL import Image
from collections import defaultdict
# 获取图片中像素点数量最多的像素
def get_threshold(image):
pixel_dict = defaultdict(int)
# 像素及该像素出现次数的字典
rows, cols = image.size
for i in range(rows):
for j in range(cols):
pixel = image.getpixel((i, j))
pixel_dict[pixel] += 1
count_max = max(pixel_dict.values()) # 获取像素出现出多的次数
pixel_dict_reverse = {v: k for k, v in pixel_dict.items()}
threshold = pixel_dict_reverse[count_max] # 获取出现次数最多的像素点
return threshold
# 按照阈值进行二值化处理
# threshold: 像素阈值
def get_bin_table(threshold):
# 获取灰度转二值的映射table
table = []
for i in range(256):
rate = 0.1 # 在threshold的适当范围内进行处理
if threshold * (1 - rate) <= i <= threshold * (1 + rate):
table.append(1)
else:
table.append(0)
return table
# 去掉二值化处理后的图片中的噪声点
def cut_noise(image):
rows, cols = image.size # 图片的宽度和高度
change_pos = [] # 记录噪声点位置
# 遍历图片中的每个点,除掉边缘
for i in range(1, rows - 1):
for j in range(1, cols - 1):
# pixel_set用来记录该店附近的黑色像素的数量
pixel_set = []
# 取该点的邻域为以该点为中心的九宫格
for m in range(i - 1, i + 2):
for n in range(j - 1, j + 2):
if image.getpixel((m, n)) != 1: # 1为白色,0位黑色
pixel_set.append(image.getpixel((m, n)))
# 如果该位置的九宫内的黑色数量小于等于4,则判断为噪声
if len(pixel_set) <= 4:
change_pos.append((i, j))
# 对相应位置进行像素修改,将噪声处的像素置为1(白色)
for pos in change_pos:
image.putpixel(pos, 1)
return image # 返回修改后的图片
# 识别图片中的数字加字母
# 传入参数为图片路径,返回结果为:识别结果
def ocr_img(img_path):
image = Image.open(img_path) # 打开图片文件
imgry = image.convert('L') # 转化为灰度图
# 获取图片中的出现次数最多的像素,即为该图片的背景
max_pixel = get_threshold(imgry)
# 将图片进行二值化处理
table = get_bin_table(threshold=max_pixel)
out = imgry.point(table, '1')
# 去掉图片中的噪声(孤立点)
out = cut_noise(out)
# 仅识别图片中的数字
# text = pytesseract.image_to_string(out, config='digits')
# 识别图片中的数字和字母
text = pytesseract.image_to_string(out)
# 去掉识别结果中的特殊字符
exclude_char_list = ' .:\\|\'\"?![],()~@#$%^&*_+-={};<>/¥'
text = ''.join([x for x in text if x not in exclude_char_list])
return text

ocrImage.ocr_img('data/0021.png')
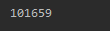
其他
针对不同的图片验证码用的方法不尽相同,cv2模块也提供了很多图片的处理方法可以用于识别图片验证码。
如使用cv2的腐蚀和碰撞方法就可以对图片进行简单的处理。
干扰条件较多、识别难度大的则需要依靠机器学习来完成。
js